上一篇介绍在linux 搭建jupter lab,本文将介绍python数据接口的爬取以及提取建模分析的数据
导入依赖的包
import requests
import time
from urllib import parse
import pandas as pd
import datetime
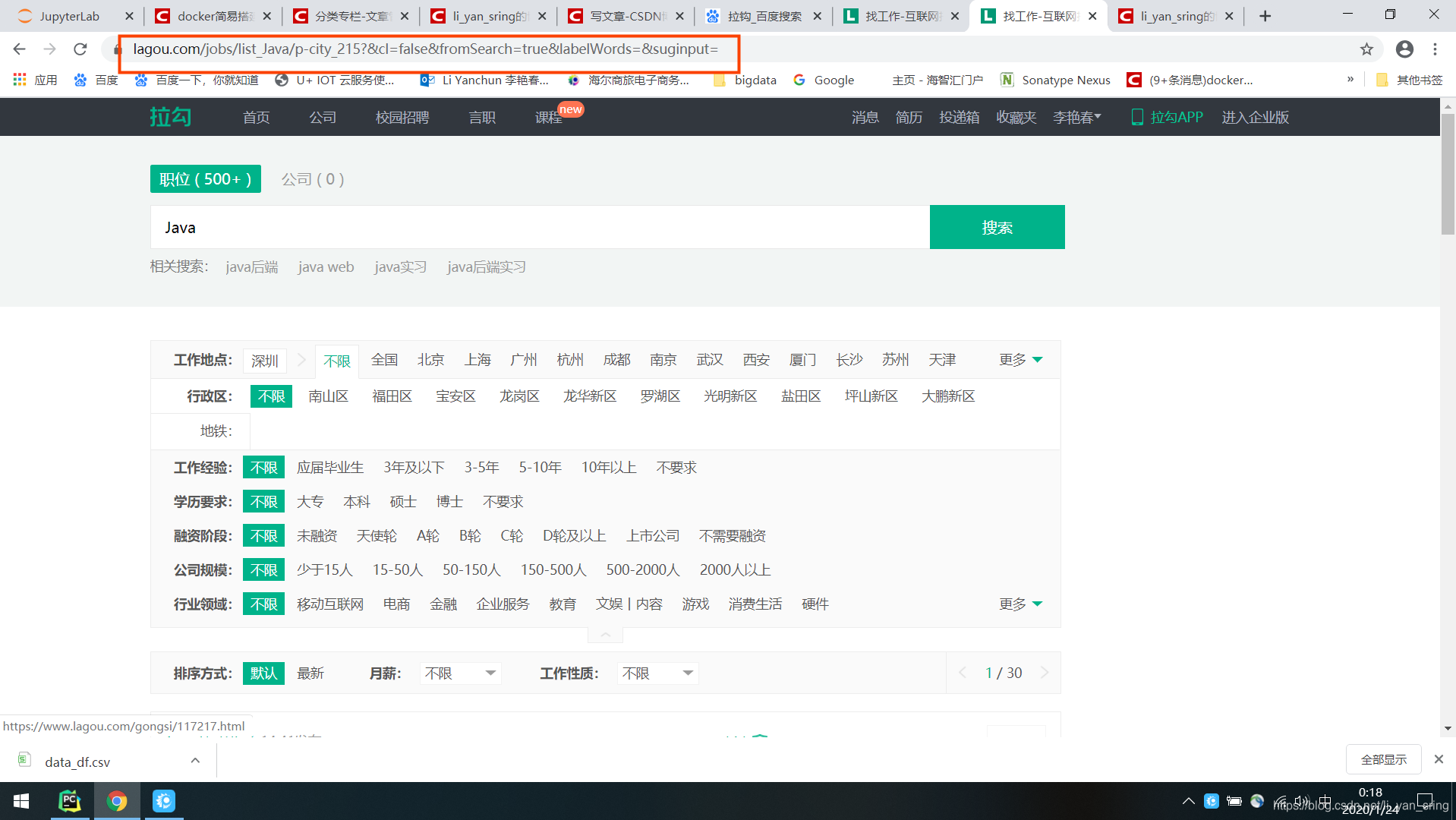
当你登录之后,点击首页的java,会跳入如下的链接:
https://www.lagou.com/jobs/list_Java/p-city_215&cl=false&fromSearch=true&labelWords=&suginput=
这个链接包含一下信息:
1.查找的列表是关于java的
2.要传入当前的对应深圳的cityCode=p-city_215
3.后面职位分页数据的查询依赖这个链接获取session
具体的代码如下:
'''
pages: 要爬取的总的数据页码数,这里等于30
total:pages*15
cityCode:深圳在拉勾网的代码编号
cityName:要查询的招聘的城市的信息
job:要查询的工作类型,java python go c++ 等等
'''
def main(pages,cityCode,cityName,job):
# 主url
mainUrl = 'https://www.lagou.com/jobs/list_'+job+'/'+cityCode+'?cl=false&fromSearch=true&labelWords=&suginput='
# ajax请求
url = 'https://www.lagou.com/jobs/positionAjax.json?city='+parse.quote(cityName)+'&needAddtionalResult=false'
# 请求头
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Referer': mainUrl,
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
'Host': 'www.lagou.com'
}
# 通过data来控制翻页
showid=''
#定义返回结果切片
ret=[]
#遍历所有数据
for page in range(pages):
'''
拉勾网分页的逻辑,当第一页码的时候
data = {
'first': 'true',
'pn': 1,
'kd': job
}
不是第一页码的时候,增加sid列,并且设置的值为上一页码json返回的showId
即 showid=respon_json["content"]["showId"]
data = {
'first': 'false',
'pn': page+1,
'kd': job,
'sid':showid
}
'''
data={}
if (page==0):
data = {
'first': 'true',
'pn': page+1,
'kd': job
}
else:
data = {
'first': 'false',
'pn': page+1,
'kd': job,
'sid':showid
}
s = requests.Session() # 建立session
s.get(url=mainUrl, headers=headers, timeout=3)
cookie = s.cookies # 获取cookie
#post 请求获取json数据
respon = s.post(url=url, headers=headers, data=data, cookies=cookie, timeout=3)
respon_json = respon.json()
#获取当前的要解析的数据
result = respon_json["content"]["positionResult"]["result"]
#获取到当前页码的showid,以便赋值下个页码请求data的sid
showid=respon_json["content"]["showId"]
print(result)
#利用pandas组装二维数组的格式
for item in result:
#定义一维数据切片,获取想要的属性并且赋值
temp = []
temp.append(item["positionName"])
temp.append(item["companyFullName"])
temp.append(item["companyShortName"])
temp.append(item["companyLogo"])
temp.append(item["companySize"])
temp.append(item["createTime"])
temp.append(item["salary"])
temp.append(item["workYear"])
temp.append(item["education"])
if (item["stationname"] != None):
temp.append(item["subwayline"]+"-"+item["stationname"])
else:
temp.append(item["subwayline"])
if(item["businessZones"]!=None):
temp.append(item["city"] + "-" + item["district"] + "-" + item["businessZones"][0])
else:
temp.append(item["city"]+"-"+item["district"])
temp.append("|".join(map(lambda x:str(x),item["companyLabelList"])))
temp.append("|".join(map(lambda x: str(x), item["skillLables"])))
ret.append(temp)
return ret
#最终整个函数的返回值为一个二维向量
至此函数封装已经完成,下面介绍将数据导入到csv 中,以便进行数据的清洗处理
#调用函数获取返回切片结果集
ret = main(30, "p-city_215", "深圳", "java")
'''DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表。
或许说它可能有点像matlab的矩阵,但是matlab的矩阵只能放数值型值(当然matlab也可以用cell存放多类型数据),DataFrame的单元格可以存放数值、字符串等,这和excel表很像。
同时DataFrame可以设置列名columns与行名index,可以通过像matlab一样通过位置获取数据也可以通过列名和行名定位,具体方法在后面细说。'''
#创建二维表
pdResult=pd.DataFrame(ret)
#将二维表数据以逗号隔开把数据写入到data_df.csv
pdResult.to_csv('data_df.csv',index=False
,header=True
,sep=','
)
#获取刚刚写入的文件
csv = pd.read_csv('data_df.csv')
#打印shape
print(csv.shape)
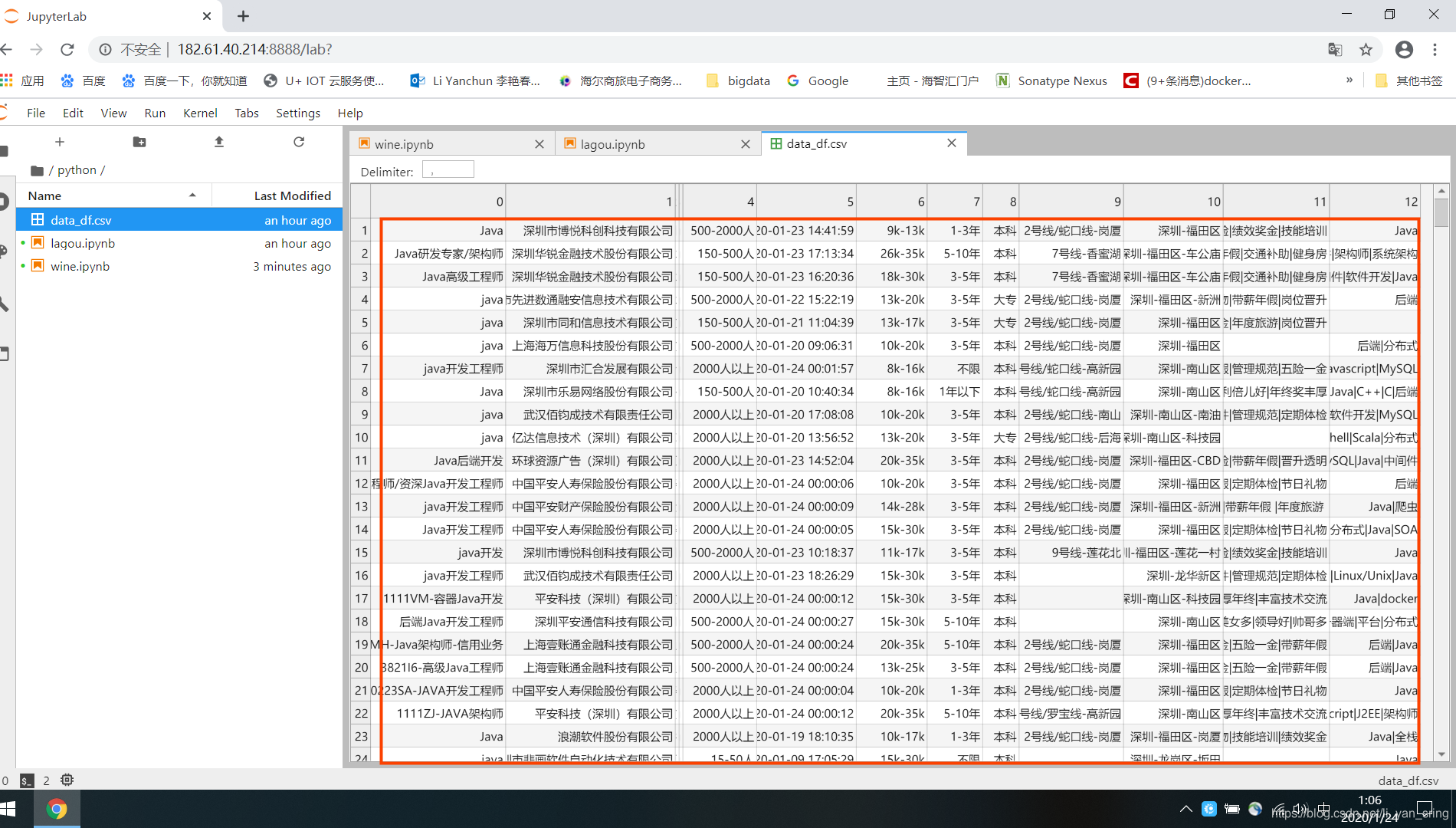
按照我的代码生成的文件地址data_df.csv
截图效果