0 需求
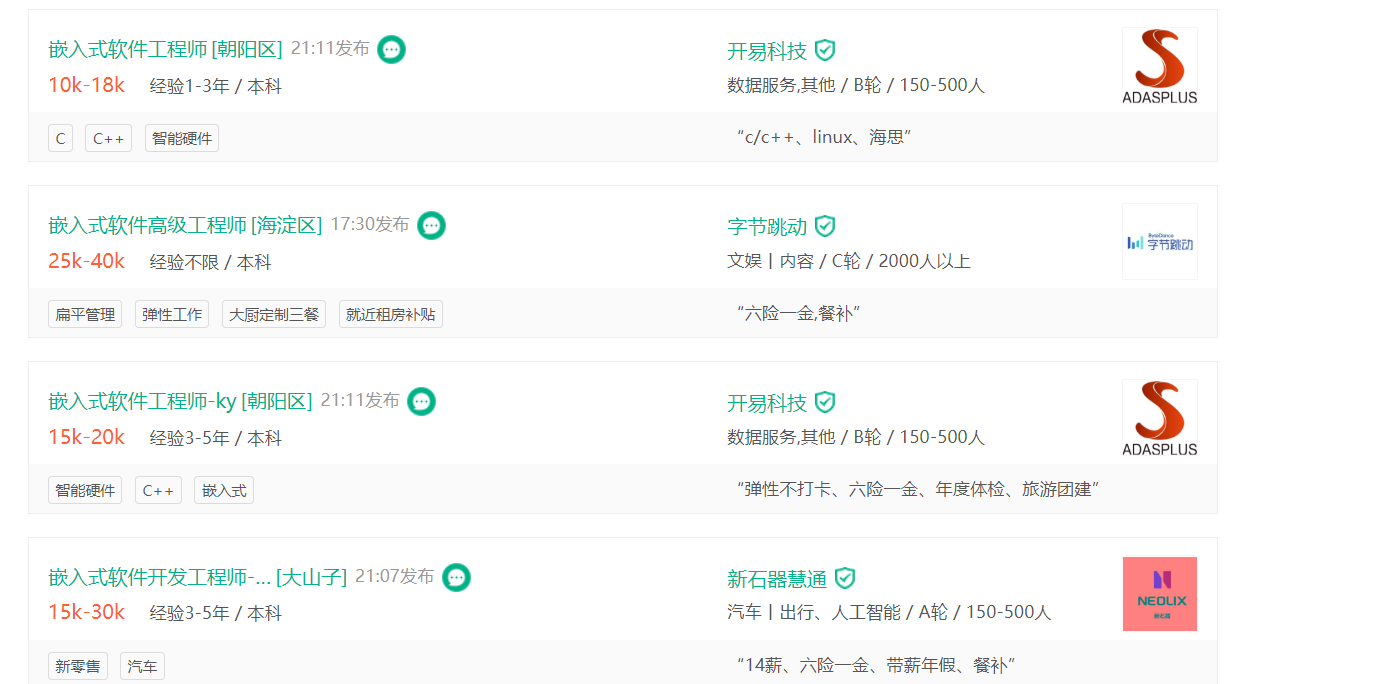
爬取拉勾网(https://www.lagou.com/)上与“嵌入式软件”关键字有关的职位信息。
1 分析
在网页的源代码中搜索我们所要的信息(公司名称等),无匹配,说明是数据动态获取的
打开检查工具,重新刷新网页,从Network下抓取到的包中找到返回数据的包。(可以使用XHR和JS标签过滤)
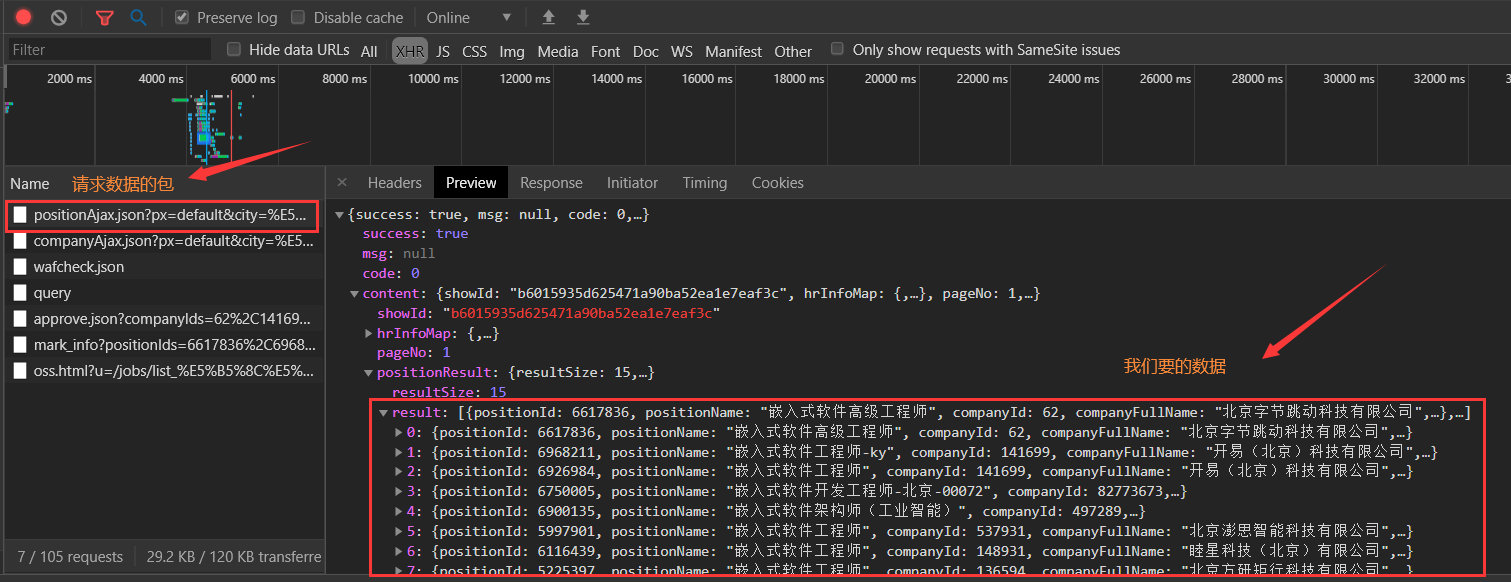
到这里基本上是成功了一半了,剩下的就要看网站的反爬机制有多给力了
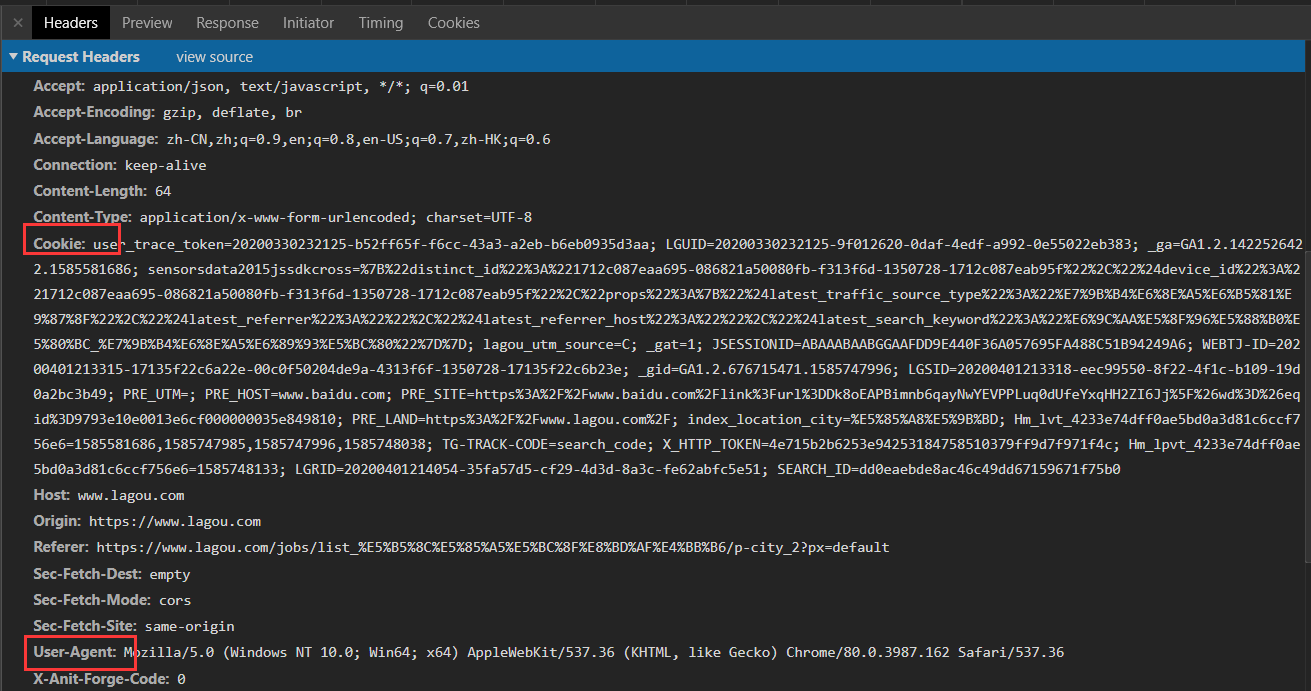
我们切换到Headers标签看这个数据包的头部信息:
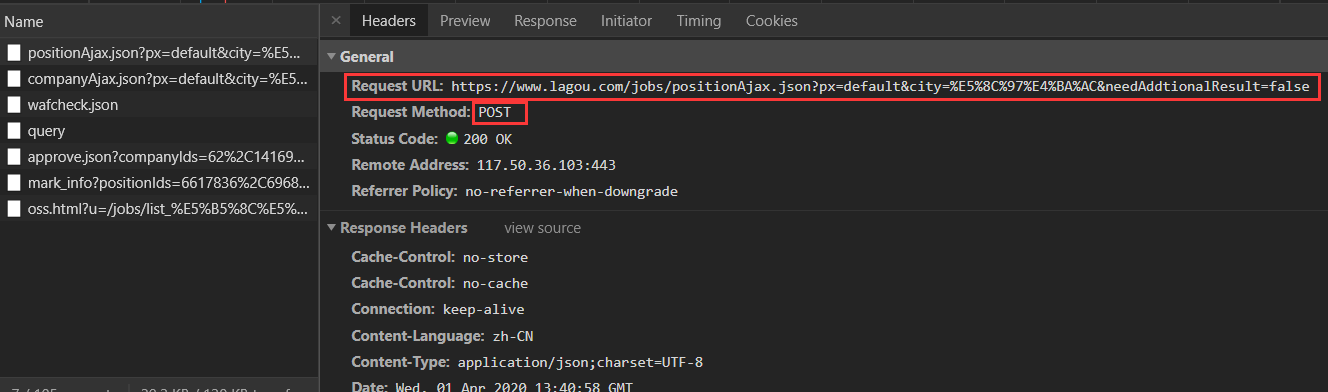
请求的URL:https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false
请求的方式:POST(与GET相比,请求数据是在FormData中,可能有加密)
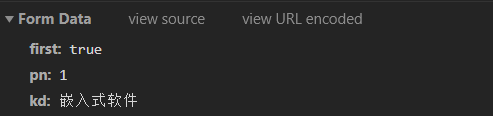 (这里比较良心,类似没有加密的数据)
(这里比较良心,类似没有加密的数据)
请求头:有可能需要加上,cookies有可能会制造麻烦/(ㄒoㄒ)/~~
分析到这,就可以开始写代码了,遇到问题解决问题(ง •_•)ง
2 爬取
一开始肯定要假设它没有设置什么反爬机制,写好URL、Headers和FormData,直接调用requests.post()
过程我就不多叙述了,直接说遇到的问题:我们如上操作后会发现返回的数据是“您访问太频繁了”
但事实上我们根本就没有访问很频繁,这便是网站设置的反爬机制,这种现象的专业名词叫——投毒
FormData既然没有加密数据,那么可以判定问题基本上是出在cookie上了
既然用固定的cookie不行,通过http请求和cookie的交互过程,我们就必须找到set-cookie的过程
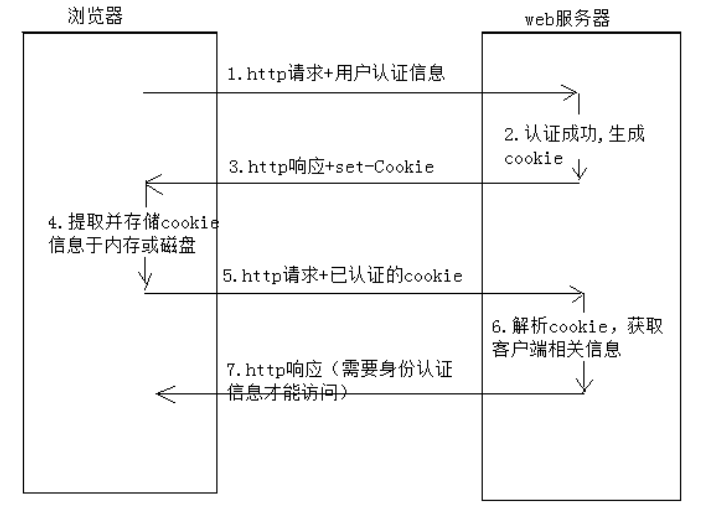 (图片来源:https://www.cnblogs.com/fanying/p/11650034.html)
(图片来源:https://www.cnblogs.com/fanying/p/11650034.html)
重新回到拉勾网的页面,清除掉现有的cookie(我是chrome,方法如下)
这时我们再刷新一下页面,分析抓到的包(找set-cookie的包啊(๑•̀ㅂ•́)و✧)
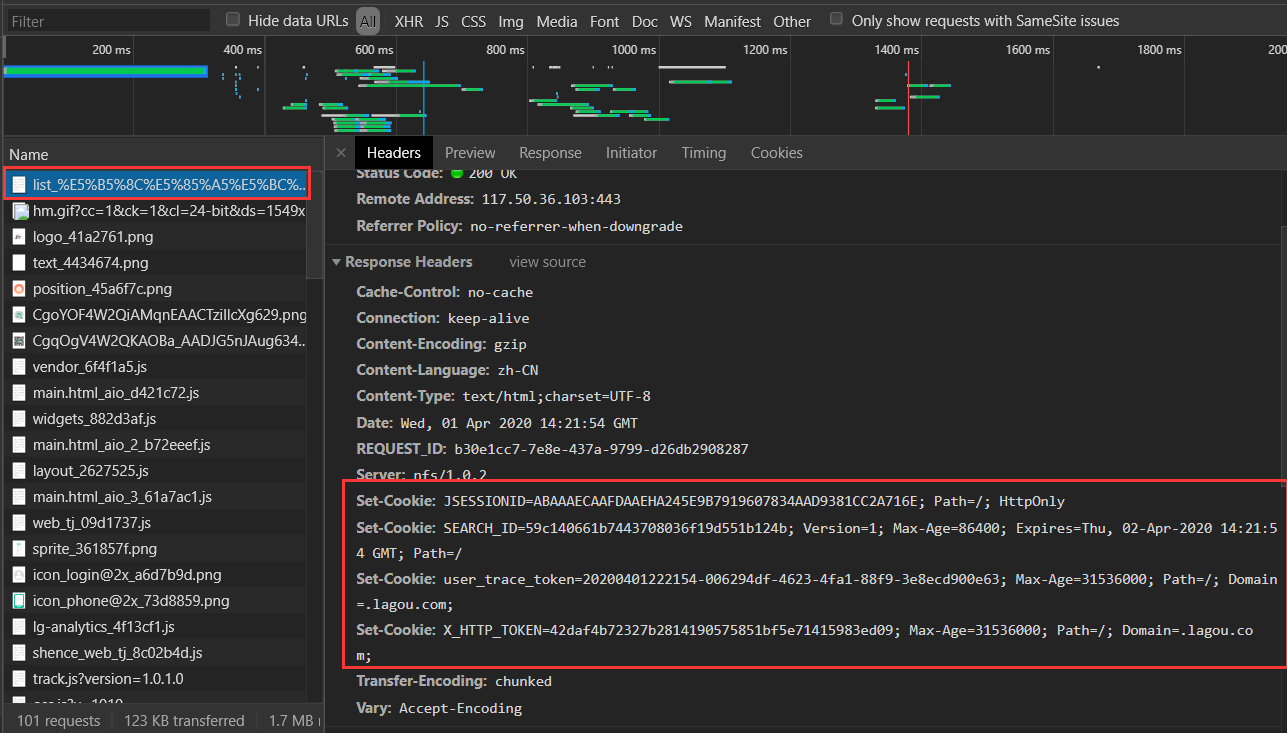
你得找到这个包啊,注意名字不一定是这个,但是一定是有Set-Cookie参数的啊
得到了cookie了,剩下的简单了,可以封装一个函数执行一个get请求获取cookie,将返回的cookie加入post请求的参数,就能获取到你想要的数据了
3 数据的处理
得到了数据,按理说我们要对数据进行筛选-提取,这里我没有特别的需求,仅仅是为了学习,就直接存一些关键信息到csv文件吧。
需要的可以用pandas、pycharts等工具进行可视化处理。
4 代码
# -*- encoding: utf-8 -*- ''' @File : lagou.py @Time : 2020/03/30 22:12:38 @Author : bAdblocks @Version : 1.0 @Contact : [email protected] ''' # here put the import lib import json import requests import pprint # 格式化打印 url = "https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E6%B7%B1%E5%9C%B3&needAddtionalResult=false" headers = { # "Cookie": getCookie(), "Host": "www.lagou.com", "Origin": "https://www.lagou.com", "Referer": "https://www.lagou.com/jobs/list_%E5%B5%8C%E5%85%A5%E5%BC%8F%E8%BD%AF%E4%BB%B6/p-city_215?px=default", # 防盗链 "Sec-Fetch-Dest": "empty", "Sec-Fetch-Mode": "cors", "Sec-Fetch-Site": "same-origin", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36", "X-Anit-Forge-Code": "0", "X-Anit-Forge-Token": "None", "X-Requested-With": "XMLHttpRequest" } form_data = { "first": "false", "pn": "1",# 页码 "kd": "嵌入式软件" } def getCookie(): cookie_url = "https://www.lagou.com/jobs/list_%E5%B5%8C%E5%85%A5%E5%BC%8F%E8%BD%AF%E4%BB%B6/p-city_215?px=default" cookie_headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400" } cookie_r = requests.get(cookie_url,headers=cookie_headers) return cookie_r.cookies cookies = getCookie() r = requests.post(url=url, data=form_data, headers=headers,cookies=cookies) print(r.text)
data = r.json() with open('职位信息.csv',mode="w+",encoding="utf-8") as f: header = ['职位名称', '公司全称', '公司规模', '薪资'] f.write(','.join(header)) f.write('\n') for item in position_data: d = [item['positionName'], item['companyFullName'],item['companySize'], item['salary']] f.write(','.join(d)) f.write('\n')