刚学python的时候,看到一位大佬说过的话 : Life is short, you need python.
昨天看了大四的毕业晚会,他们走了之后我们就是大四的了,猝不及防的就要毕业了(小小感慨一哈)
今天爬取的是招聘网站的信息,为毕业找工作的胖友们提供一个既好玩又可以查看工作信息的方法。Python的环境配置可以自行百度,开发工具用的Pycharm(当然其他开发工具也可以)。
首先看一下爬取的网站 : https://www.lagou.com/jobs/list_Python?px=default&city=%E5%8C%97%E4%BA%AC#filterBox
这是招聘网站中北京的一些招聘信息(工资看起来好高,不过水平不够。。。)。第一步爬取网站的源代码信息 :
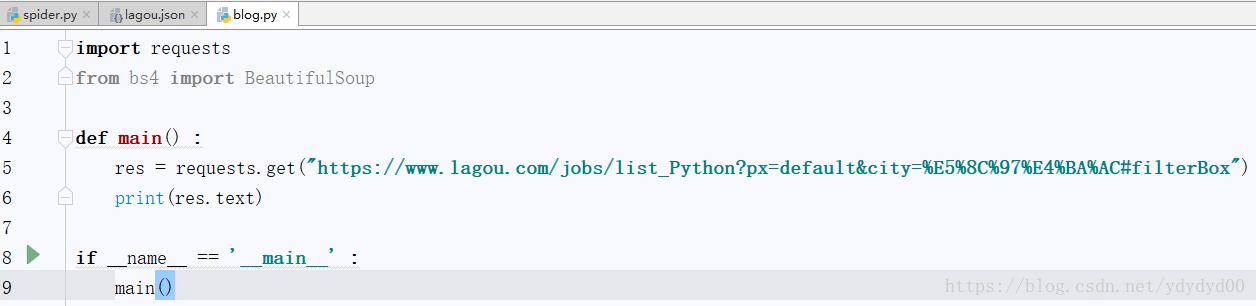
运行之后会在下方窗口显示运行结果 :
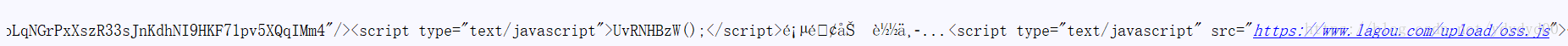
结果显示的主体部分是乱码,网站的反爬虫机制让爬虫无法直接爬取信息,并且网站的数据传输是Ajax异步传输,所以先打开开发者工具(按F12打开开发者工具),选择network下的XHR(XMLHttpRequest),选择带Ajax的正确的网址,然后在右边框中找到Request Headers,下面会有正确的头部信息,与招聘网站的专门为爬虫设置的反爬虫
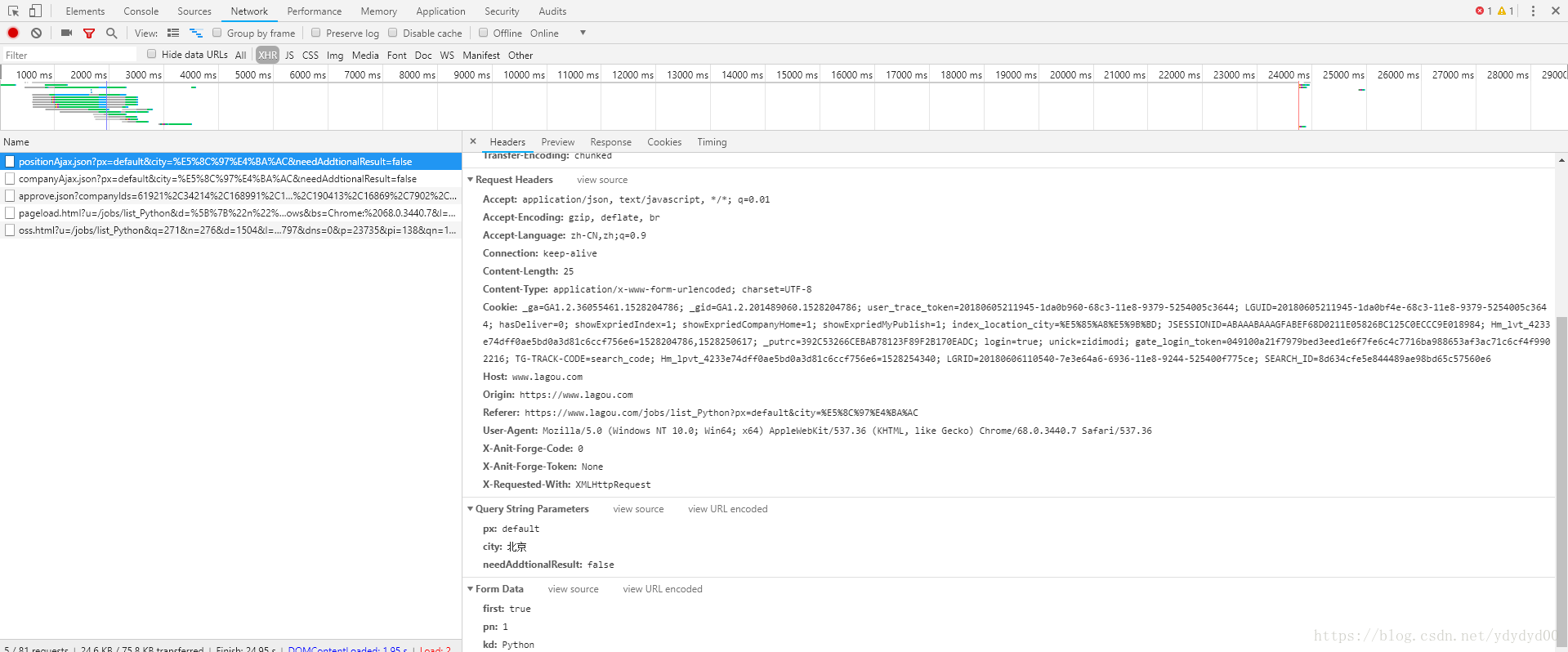
在添加headers与这个招聘网站专门的反爬虫代码后就可以开始模拟浏览器请求页面,并爬取网站本页的信息了,以下是添加后的代码与结果(结果的形式不太好看,将结果复制粘贴到 json.cn 下,会转化的稍微能看一点) :
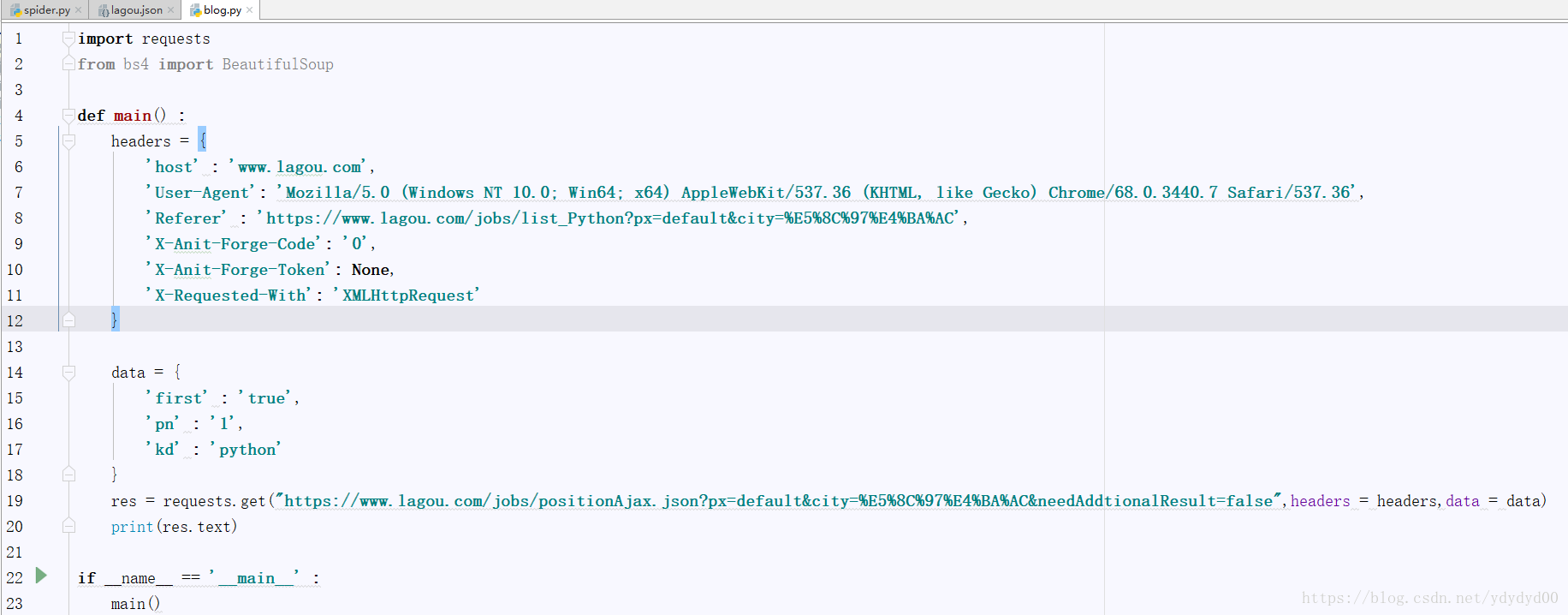

需要注意的是data,这个是本招聘网站的反爬虫,如果不加的话也会返回网页信息,不过返回的网页信息是后台数据库自动生成的虚假信息(可以说是很恶心了,弄一堆反爬虫的东西)


这里需要注意的是打开 lagou.json 的方法,后面是“wb+”,在python2的时候用的“w”
加上保存的代码后会在左方的菜单栏处生成一个.json的文件,打开.json文件就可以看到招聘的信息了(有点乱,可以自行整理):

最后一点就是迭代爬取,循环页面,不断的模拟浏览器翻页,并且爬取每一页的招聘信息(这个招聘网站的反爬虫做的确实好啊,迭代的时候只爬取了6页还是7页就不让爬了,说访问过于频繁),为了解决访问频繁的问题,可以在迭代的时候引入一个time.sleep(x)函数,x是参数,表示隔x秒后再请求,不过x太小了就无法解决访问频繁的问题,但是x大了之后时间太长,所以我就没有去试了,只爬了6到7页的信息。
附上源码 (爬虫真的有毒,沾上了就感觉停不下来的。。。):
import requests
from bs4 import BeautifulSoup
import json
import time
def main() :
headers = {
'Host' : 'www.lagou.com',
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.7 Safari/537.36',
'Referer' : 'https://www.lagou.com/jobs/list_Python?px=default&city=%E5%8C%97%E4%BA%AC',
'X-Anit-Forge-Code' : '0',
'X-Anit-Forge-Token' : None,
'X-Requested-With' : 'XMLHttpRequest'
}
positions = []
for x in range(1,6) :
data = {
'first' : 'true',
'pn' : x,
'kd' : 'python'
}
res = requests.post("https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false",headers = headers,data = data)
json_result = res.json()
page_positions = json_result['content']['positionResult']['result']
positions.extend(page_positions)
for position in positions :
#打印测试
print("-"*40)
print(position)
#转化为Json字符串
line = json.dumps(positions,ensure_ascii = False)
#保存
with open('lagou.json','wb+') as fp :
fp.write(line.encode('utf-8'))
time.sleep(3)
if __name__ == '__main__':
main()