最近学习一点数据分析,自己就想来点实际的比较有意思,刚好一年毕业季,就爬取了拉钩网,自己本人刚好又在做Java的程序设计实验,就顺便爬取了Java岗位。下面是我的爬虫代码。
1 import requests 2 import json 3 import lxml 4 from lxml import etree 5 from bs4 import BeautifulSoup 6 import time 7 8 9 positions = [] 10 header = {'Host':'www.lagou.com', 11 'Referer':'https://www.lagou.com/jobs/list_Java?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=', 12 'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Mobile Safari/537.36', 13 'X-Anit-Forge-Code':'0', 14 'X-Anit-Forge-Token':None, 15 'X-Requested-With':'XMLHttpRequest'} 16 for x in range(1,31): 17 if(x==1): 18 y='true' 19 else: 20 y='false' 21 data ={'first':y,'pn':x,'kd':'Java'} 22 urls = "https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false" 23 r = requests.post(url = urls,headers = header,data = data) 24 json_result = r.json() #将爬取得网页转化成json格式 25 position_page = json_result['content']['positionResult']['result']#获取每页我们需要的内容 26 for position in position_page: 27 position_dict = {"岗位名称": position['positionName'], 28 '地点': position['city'], 29 '公司名称': position['companyFullName'], 30 '薪水': position['salary'], 31 '工作经验': position['workYear'], 32 } #通过字典存储的我们的信息 33 positions.append(position_dict) 34 line = json.dumps(positions, ensure_ascii=False)#将字典转化为json 35 time.sleep(20)#因为拉钩的反扒机制,频率太快就会被限制,所以睡眠一下 36 with open('lagou.json', 'w') as fp: 37 fp.write(line) 38 print("第%d已经爬取完毕" % x) 39 print('爬取完成')
本人对爬虫也不太精通,有错误的地方还忘多多指教,拉钩网的爬虫还是很不错的,首先他使用了异步加载的方式,如果不懂异步加载,那么很可能你就无法爬取到内容,什么是异步加载,这里就不多做解释,说白了就是要找对我们想要信息的网址就是 urls = "https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false",而不是直接看到URL框里的那个网址,找到这个你以为你就能爬到真正的信息了吗?注意我用的是”真正的信息“,因为拉钩还是很狡猾的,如果你没有吧请求头加完整的话,那么拉钩将给你返回一大堆假的信息,如果你不仔细观察,就会被它骗了,不信你可以试试,爬虫就说这么多,下来看看这些信息的分析。

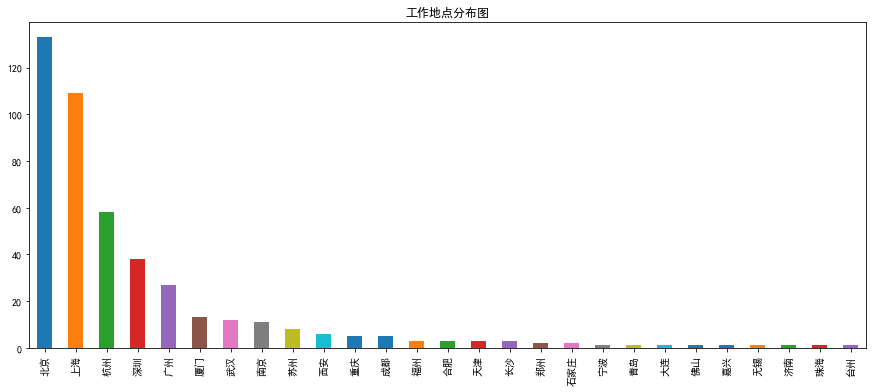
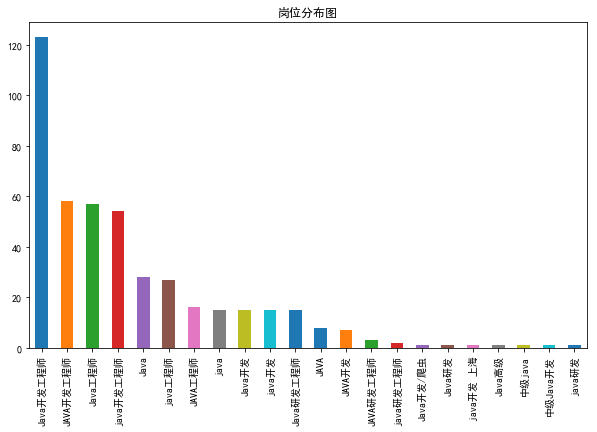
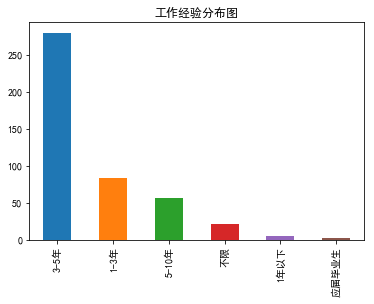
一波图片我想所有的问题都已经说的明明白白了。下面附上我代码,如有不足,多多指正。
# coding: utf-8
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import json
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #设置字体,解决中文乱码问题
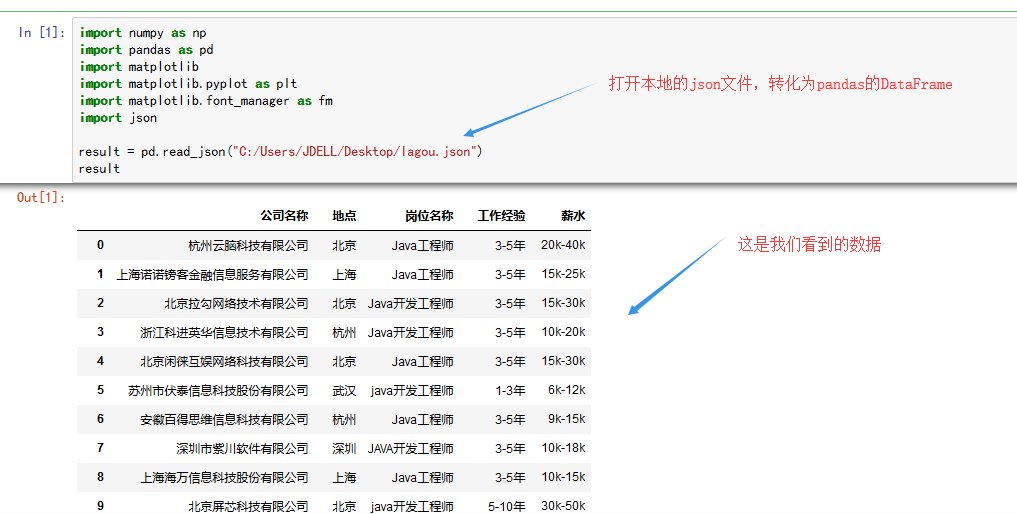
result = pd.read_json("C:/Users/JDELL/Desktop/lagou.json")
result.工作经验.value_counts().plot(kind = "bar")
plt.title("工作经验分布图")
fig = plt.figure(figsize = (10,5))
result.地点.value_counts().plot(kind = "bar")
plt.title("工作地点分布图")
plt.figure(figsize=(10,6))
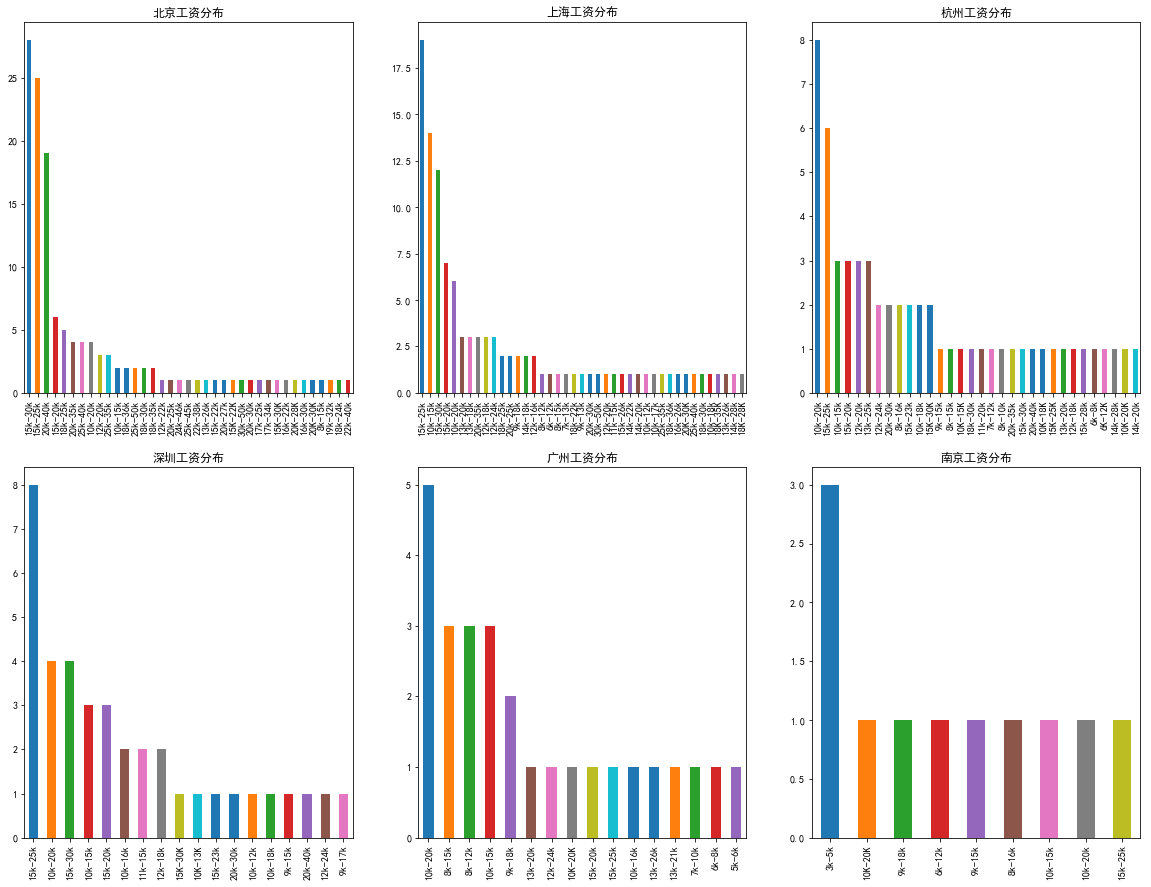
result.薪水[result.地点=="北京"].value_counts().plot(kind = "bar")
plt.title("北京工资分布")
plt.figure(figsize=(10,8))
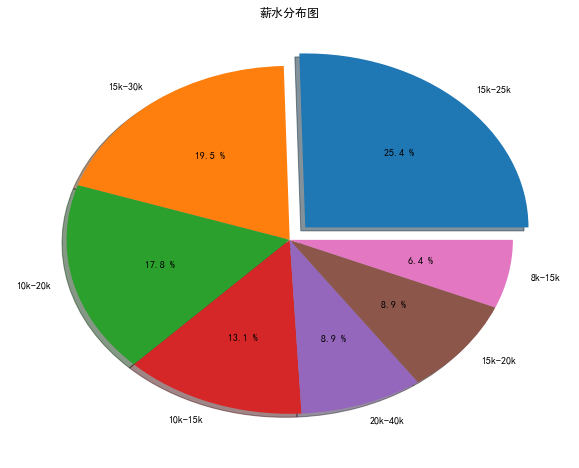
lables = '15k-25k','15k-30k','10k-20k','10k-15k','20k-40k','15k-20k','8k-15k'
explode = [0.1,0,0,0,0,0,0]
data = [60,46,42,31,21,21,15]
plt.pie(x = data,labels = lables,autopct='%3.1f %%',shadow=True, explode=explode)
plt.figure(figsize=(10,8))
lables = '15k-25k','15k-30k','10k-20k','10k-15k','20k-40k','15k-20k','8k-15k'
explode = [0.1,0,0,0,0,0,0]
data = [60,46,42,31,21,21,15]
plt.title("薪水分布图")
plt.pie(x = data,labels = lables,autopct='%3.1f %%',shadow=True, explode=explode)
plt.figure(figsize=(8,6))
lables = t.index
data = t.values
plt.title("深圳薪水分布饼状图")
plt.pie(x = data,labels = lables,autopct='%3.1f %%',shadow=True)
t = result.岗位名称.value_counts()
plt.figure(figsize=(15,20))
lables = t.index
data = t.values
plt.title("岗位分布饼状图")
plt.pie(x = data,labels = lables,autopct='%3.1f %%',shadow=True)