note:这里实现的wide_deep模型的输入是相同的,如果想参考不同输入的coding方法,可以参考:https://blog.csdn.net/qq_41660119/article/details/105762225
在这里选用的数据集是加利福尼亚的房价数据集,因为这个回归问题里有8个特征,可以将这8个特征进行划分,作为wide和deep模型的输入,因此这个问题更适合用wide_deep模型来实现,数据集的详细信息描述如下:
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
print(housing.DESCR)
print(housing.data.shape)
print(housing.target.shape).. _california_housing_dataset: California Housing dataset -------------------------- **Data Set Characteristics:** :Number of Instances: 20640 :Number of Attributes: 8 numeric, predictive attributes and the target :Attribute Information: - MedInc median income in block - HouseAge median house age in block - AveRooms average number of rooms - AveBedrms average number of bedrooms - Population block population - AveOccup average house occupancy - Latitude house block latitude - Longitude house block longitude :Missing Attribute Values: None This dataset was obtained from the StatLib repository. http://lib.stat.cmu.edu/datasets/ The target variable is the median house value for California districts. This dataset was derived from the 1990 U.S. census, using one row per census block group. A block group is the smallest geographical unit for which the U.S. Census Bureau publishes sample data (a block group typically has a population of 600 to 3,000 people). It can be downloaded/loaded using the :func:`sklearn.datasets.fetch_california_housing` function. .. topic:: References - Pace, R. Kelley and Ronald Barry, Sparse Spatial Autoregressions, Statistics and Probability Letters, 33 (1997) 291-297 (20640, 8) (20640,)
wide_deep模型并不是一个严格的层级结构,而是由两部分组成的,每一部分都是一个层级结构,因此不能用简单的Sequential的方式通过将层次堆叠的方式来实现模型了。在这里使用函数式API实现wide_deep模型的关键模型部分代码如下:
#函数式API
input = keras.layers.Input(shape=x_train.shape[1:])
hidden1 = keras.layers.Dense(30, activation='relu')(input)
hidden2 = keras.layers.Dense(30, activation='relu')(hidden1)
#复合函数:f(x)=h(g(x))
#假设wide模型的输入与deep模型的输入相同
concat = keras.layers.concatenate([input, hidden2])#将wide模型的输入与deep模型的输出连接起来
output = keras.layers.Dense(1)(concat)
#使用函数式方法需要用Model把模型固化下来
model = keras.models.Model(inputs=[input], outputs=[output])
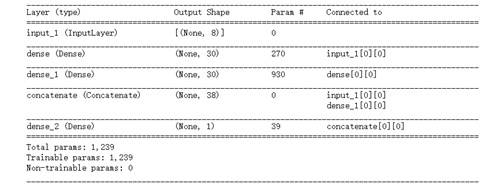
model.summary()
model.compile(loss="mean_squared_error", optimizer=keras.optimizers.SGD(0.001),)
callbacks = [keras.callbacks.EarlyStopping(patience=5, min_delta=1e-2)]
网络结构:
附全部代码:
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
print(tf.__version__)
print(sys.version_info)
for module in mpl, np, pd, sklearn, tf, keras:
print(module.__name__, module.__version__)
physical_devices = tf.config.experimental.list_physical_devices('GPU')
assert len(physical_devices) > 0, "Not enough GPU hardware devices available"
tf.config.experimental.set_memory_growth(physical_devices[0], True)
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
print(housing.DESCR)
print(housing.data.shape)
print(housing.target.shape)
from sklearn.model_selection import train_test_split
x_train_all, x_test, y_train_all, y_test = train_test_split(
housing.data, housing.target, random_state = 7)
x_train, x_valid, y_train, y_valid = train_test_split(
x_train_all, y_train_all, random_state = 11)
print(x_train.shape, y_train.shape)
print(x_valid.shape, y_valid.shape)
print(x_test.shape, y_test.shape)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_valid_scaled = scaler.transform(x_valid)
x_test_scaled = scaler.transform(x_test)
# 函数式API 功能API
input = keras.layers.Input(shape=x_train.shape[1:])
hidden1 = keras.layers.Dense(30, activation='relu')(input)
hidden2 = keras.layers.Dense(30, activation='relu')(hidden1)
# 复合函数: f(x) = h(g(x))
concat = keras.layers.concatenate([input, hidden2])
output = keras.layers.Dense(1)(concat)
model = keras.models.Model(inputs = [input],
outputs = [output])
model.summary()
model.compile(loss="mean_squared_error",
optimizer = keras.optimizers.SGD(0.001))
callbacks = [keras.callbacks.EarlyStopping(
patience=5, min_delta=1e-2)]
history = model.fit(x_train_scaled, y_train,
validation_data = (x_valid_scaled, y_valid),
epochs = 100,
callbacks = callbacks)
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 1)
plt.show()
plot_learning_curves(history)
model.evaluate(x_test_scaled, y_test, verbose=0)
