
Wide&Deep的右边就是DNN部分,左边的FM Function用的是线性回归,其特征组合需要人去设计。
Wide&Deep模型。它混合了一个线性模型(Wide part)和Deep模型(Deep part)。这两部分模型需要不同的输入,而Wide part部分的输入,依旧依赖人工特征工程。
Wide&Deep模型
推荐系统和类似的通用搜索排序问题共有的一大挑战为同时具备记忆能力与泛化能力(同时获得推荐结果准确性和扩展性)。记忆能力可以解释为学习那些经常同时出现的特征,发掘历史数据中存在的共现性。泛化能力则基于迁移相关性,探索之前几乎没有出现过的新特征组合。基于记忆能力的推荐系统通常偏向学习历史数据的样本,直接与用户己经采取的动作相关;泛化能力相比记忆能力则更趋向于提升推荐内容的多样性。推荐的内容都是精准内容,用户兴趣收敛,无新鲜感,不利于长久的用户留存;推荐内容过于泛化,用户的精准兴趣无法得到满足,用户流失风险很大。相比较推荐的准确性,扩展性倾向与改善推荐系统的多样性。
例如:人脑可以记忆下每天发生的事情(麻雀可以飞,鸽子可以飞)然后泛化这些知识到之前没有看到过的东西(有翅膀的动物都能飞)。但是泛化的规则有时候不是特别的准,有时候会出错(有翅膀的动物都能飞吗),记忆可以修正泛化的规则。

1.3 Cross-product transformation
Wide中不断提到这样一种变换用来生成组合特征,也必须搞懂才行哦。它的定义如下: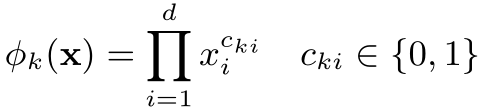
k表示第k个组合特征。i表示输入X的第i维特征。C_ki表示这个第i维度特征是否要参与第k个组合特征的构造。d表示输入X的维度。那么到底有哪些维度特征要参与构造组合特征那?这个是你之前自己定好的,在公式中没有体现。
该公式是one-hot之后的组合特征:仅仅在输入样本X中的特征gender=female和特征language=en同时为1,新的组合特征AND(gender=female, language=en)才为1。所以只要把两个特征的值相乘就可以了。Cross-product transformation 可以在二值特征中学习到组合特征,并且为模型增加非线性
wide模型介绍
Wide部分是广义线性模型(如逻辑回归),因为它们简单,可扩展,可解释,它在工业界大规模线上推荐和排序系统中得到了广泛应用。
wide模型可以通过利用交叉特征引入非线性高效的实现记忆能力,达到准确推荐的目的。wide模型通过加入一些宽泛类特征实现一定的泛化能力。但是受限与训练数据,wide模型无法实现训练数据中未曾出现过的泛化。
这些模型一般在二值稀疏特征上训练,这些特征一般采用独热编码。举个例子,如果用户安装了腾讯视频,则二值特征user_installed_app = TencenVideo的值为1。模型的记忆能力可以有效地通过稀疏特征之上的外积变换获得,类似地,当用户安装了腾讯视频,随后又展示了QQ音乐,那么AND ( user_installed_app=TencentVideo, impression_app=QQMusic)的值为1。这解释了同时发生的一对特征是如何与对应标签关联的。进一步我们可以通过使用小颗粒特征提高泛化能力,例如,AND( user_installed_category=video; impression_category = music ),但这些特征常常需要人工来选择。外积变换有一个限制,它对于不在训练数据中的查询项不具备泛化能力。
如:给model一个query(想吃的美食),model返回一个美食,然后你购买/消费了这个推荐。 Wide Part可以对一些特例进行记忆。比如AND(query=”fried chicken”, item=”chicken fried rice”)虽然从字符角度来看很接近,但是实际上完全不同的东西,那么Wide就可以记住这个组合是不好的,是一个特例,下次当你再点炸鸡的时候,就不会推荐给你鸡肉炒米饭了。
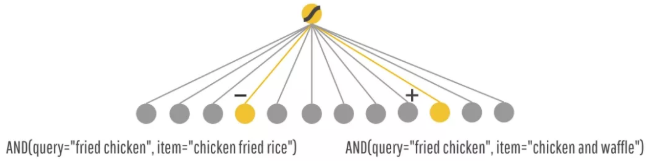
deep 模型介绍
基于嵌入的模型(如FM和DNN)可以通过学习到的低维稠密向量实现对以前没有出现过的查询项特征对也具备泛化能力,通过为每个查询和条目特征学习一个低维稠密的嵌入向量,减轻了特征工程负担。如:泛化给你推荐一些字符上看起来不那么相关,但是你可能也是需要的。比如说:你想要炸鸡,Embedding Space中,炸鸡和汉堡很接近,所以也会给你推荐汉堡。
Deep部分就是个前馈网络模型,特征首先转换为低维稠密向量,再将其作为第一个隐藏层的输入,根据最终的loss来反向训练更新。向量进行随机初始化,隐藏层的激活函数通常使用ReLU。前馈部分表示如下:
![]()
![]()

但嵌入的模型的缺点在于它很难有效学习低维表示,当query-item矩阵稀疏且高秩时很难非常效率的学习出低维度的表示(如user有特殊的爱好或item比较小众)。这种情况下,大多数query-item是没有交集的,但稠密嵌入(dense embedding)会给所有query-item带来非零预测,从而可能过度泛化,给出完全不相关的推荐,准确性不能得到保证。而使用外积特征变换的线性模型只需少量参数就能记住这些“特殊偏好”。
所以通过联合训练一个线性模型组件和一个深度神经网络组件设计了一种融合浅层模型和深层模型进行联合训练的框架,得到Wide & Deep模型。综合利用浅层模型的记忆能力(Memorization)和深层模型的泛化能力(Generalization),用一个模型就可以同时获得记忆能力和泛化能力,实现单模型对推荐系统准确性和扩展性的兼顾。
模型的训练
原始的稀疏特征,在两个组件中都会用到,比如query="fried chicken" item="chicken fried rice":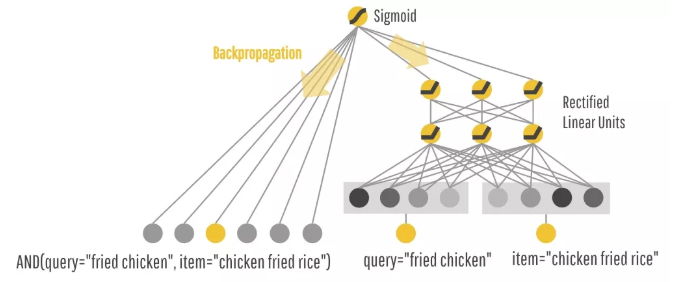
通过联合训练方式进行训练。之前面试问到两个部分是否可以用不同的优化器,论文中给出的是:Wide组件是用FTRL(Follow-the-regularized-leader) + L1正则化学习。Deep组件是用AdaGrad来学习。
在联合模型中,Wide和Deep部分的输出通过加权方式合并到一起,并通过logistic loss function进行最终输出。
![]()
![]()
联合训练和模型集成要进行区分,他们有着以下两点区别:
1. 训练方式。 集成模型的子模型部分是独立训练,只在inference阶段合并预测。而联合训练模型是同时训练同时产出的。
2. 模型规模。集成模型独立训练,模型规模要大一些才能达到可接受的效果。而联合训练模型中,Wide部分只需补充Deep模型的缺点,即记忆能力,这部分主要通过小规模的交叉特征实现。因此联合训练模型的Wide部分的模型特征较小。
联合模型求解采用FTRL算法,L1正则。深度部分用AdaGrad优化算法。
在训练的时候,根据最终的loss计算出gradient,反向传播到Wide和Deep两部分中,分别训练自己的参数。也就是说,两个模块是一起训练的,注意这不是模型融合。
Deep部分使用的特征:连续特征,Embedding后的离散特征,Item特征
Wide部分使用的特征:Cross Product Transformation生成的组合特征
-
Wide部分中的组合特征可以记住那些稀疏的,特定的rules
-
Deep部分通过Embedding来泛化推荐一些相似的items
Wide模块通过组合特征可以很效率的学习一些特定的组合,但是这也导致了他并不能学习到训练集中没有出现的组合特征。所幸,Deep模块弥补了这个缺点。
另外,因为是一起训练的,wide和deep的size都减小了。wide组件只需要填补deep组件的不足就行了,所以需要比较少的cross-product feature transformations,而不是full-size wide Model。
论文中的实现:
-
训练方法是用mini-batch stochastic optimization。
-
Wide组件是用FTRL(Follow-the-regularized-leader) + L1正则化学习。
-
Deep组件是用AdaGrad来学习。
3.2 模型训练
对提出的W&D模型,文中从推荐效果和服务性能两方面进行评价:1. 效果上,在Google Play 进行线上A/B实验,W&D模型相比高度优化的Wide浅层模型,app下载率+3.9%。相比deep模型也有一定提升。 2. 性能上,通过切分一次请求需要处理的app 的Batch size为更小的size,并利用多线程并行请求达到提高处理效率的目的。单次响应耗时从31ms下降到14ms。

模型在超过5千亿样本上训练。为了解决模型新样本训练和更新模型的延迟,文中设计了warm-starting方式进行模型的更新,即预先用上一个版本的向量和wide模型的权重进行初始化模型。模型加载后,空跑一轮确认在大规模服务期间无问题。有点类似为了解决tf程序懒加载而进行warm-up的空跑。
模型服务阶段将请求的batch size切分为更小的size,由多线程程序并行执行,缩短运行时间。
效果实验

实验通过离线AUC和线上ABtest进行评估。W&D模型的auc超过单纯的Wide和Deep模型。ABtest线上实验中,W&D模型比base部分高度优化过的Wide模型,Acquisition +3.9%,同样优于单纯的Deep模型。
4. 适用范围
Wide & Deep Model适用于输入非常稀疏的大规模分类或回归问题。比如推荐系统、search、ranking问题。
输入稀疏通常是由离散特征有非常非常多个可能的取值造成的,one-hot之后维度非常大。
5. 优缺点
缺点:Wide部分还是需要人为的特征工程。
优点:实现了对memorization和generalization的统一建模。