1. 过拟合问题
首先,我们来看看过拟合问题的定义:
为了得到一致假设而使假设变得过度严格称为过拟合。
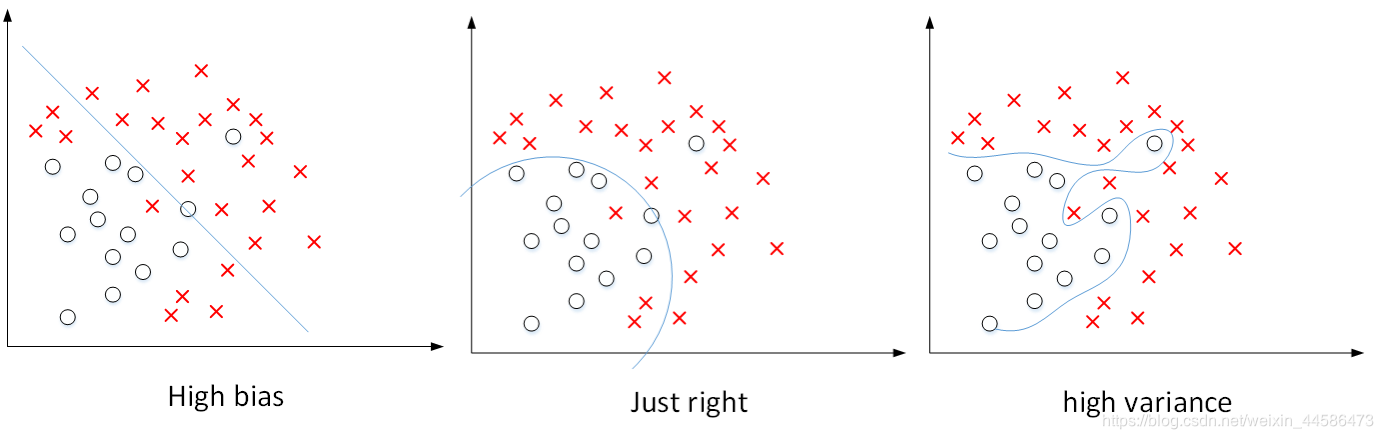
我们通过下面的图片直观理解什么是过拟合问题:

红色的叉叉代表我们的数据集。1. 假设我们用函数:
θ0+θ1x来拟合数据,得到的是一条简单的一次函数直线,很明显,这样的拟合过于简单,并不能反映数据的真实分布,我们称之为存在高偏差
2. 中间的图片:我们使用二次函数:
θ0+θ1x+θ2x2来拟合数据,现在非常好,拟合的程度可以反映数据的真实分布,我们称之为“Just Right”
3. 第三种情况:我们用一个高次函数
θ0+θ1x+θ2x2+θ3x3+θ4x4来拟合数据,我们可以看到,曲线完全经过所给数据集,但是,这样曲曲折折的曲线却反而不能表达数据的真实分布了,这时我们称之为具有高方差,此时的情况就是过拟合
下面的例子中,最右边的也是过拟合问题的范例:
过拟合产生的问题就是模型不能很好地泛化到新样本中
正则化将会很好地解决过拟合问题,在后面几节的学习中,我们会详细学习它
2.正则化里面的代价函数
首先,让我们来看看博文第一张图片,看看正常的模型和过拟合模型的函数:
正常:
hθ(x)=θ0+θ1x+θ2x2
过拟合:
hθ(x)=θ0+θ1x+θ2x2+θ3x3+θ4x4
很显然,在本例中,过拟合问题就是由这些高次项系数
θ3,θ4产生的,因此,要缓解过拟合,我们就希望让
θ3,θ4尽量小,怎么做呢?
首先,这是我们本来需要最小化的代价函数:
J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2
现在,我们对它进行一些改动:
J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2+1000∗θ32+1000∗θ42
(其中,1000是我们随便取的一个比较大的数字)
如果我们要最小化这个
J(θ),那么令
1000∗θ32+1000∗θ42最小的方法只有一个:就是令
θ3,θ4最小,那么这样一来,我们就相当于去掉了
θ3x3,θ4x4这两项
这就是正则化背后的思想:参数越小,越少,意味着使用更加简单的模型
下面再举一个例子:比如我们要进行房屋价格的预测
假设有100个特征:
x1,x2,x3,⋯,x100
那么,我们的参数有101个:
θ0,θ1,θ2,⋯,θ100
现在,问题来了:在第一个例子里面,我是知道
θ3,θ4是有影响的参数,可是现在我并不知道这101个参数里面那些参数参与导致了过拟合,因此,保险的办法就是对所有参数都加上惩罚项,因此,我们要对cost function做这样的修改:
J(θ)=2m1[i=1∑m(hθ(x(i))−y(i))2+λj=1∑nθj2]
(注意:这里我们都是从1开始对θ进行惩罚,并不去惩罚
θ0)
最后,正则化参数λ不能取得太大了,否则对所有参数的惩罚力度太大,将导致模型变成:
hθ(x)=θ0,这就变成了欠拟合了
3. 线性回归中的正则化
还记得我们正则化里面的代价函数吗?
J(θ)=2m1[i=1∑m(hθ(x(i))−y(i))2+λj=1∑nθj2]
而现在,我们来讨论一下这种代价函数的梯度下降法:
在梯度下降法中,我们做的是:
Repeat
{
θ0:=θ0−α[m1∑i=1m(hθ(x(i))−y(i))x0(i)]
θj:=θj−α[m1∑i=1m(hθ(x(i))−y(i))xj(i)+mλθj]
}
现在,我们对式子:
θj:=θj−α[m1i=1∑m(hθ(x(i))−y(i))xj(i)+mλθj]
做一些合并:
θj:=θj(1−αmλ)−α[m1i=1∑m(hθ(x(i))−y(i))xj(i)]
而通过数学知识我们知道:
1−αmλ < 1
4.逻辑回归中的正则化
还记得我们在逻辑回归中使用的代价函数吗?
J(θ)=−[m1i=1∑my(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))]
而现在我们要做的,也只是在上面这个损失函数的后面加上一个正则化项:
J(θ)=−[m1i=1∑my(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))]+2mλj=1∑nθj2
那么,对于梯度下降法:
Repeat
{
θ0:=θ0−α[m1∑i=1m(hθ(x(i))−y(i))x0(i)]
θj:=θj−α[m1∑i=1m(hθ(x(i))−y(i))xj(i)+mλθj]
}
