一、防止过度拟合
过度拟合问题:
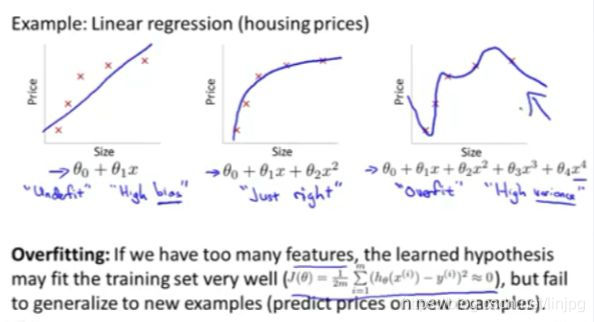
例如:那个用线性回归来预测房价的例子,我们通过建立以住房面积为自变量的函数来预测房价,我们可以对该数据做线性回归,以下为三组数据做线性拟合的结果:
①第一个图我们用直线去拟合,这不是一个很好的模型。
我们看看这些数据,很明显,随着房子面积增大,住房价格的变化应趋于稳定,或者越往右越平缓。
因此该算法没有很好拟合训练数据,我们把这个问题称为欠拟合(underfitting),这个问题的另一个术语叫做高偏差(bias) 。
②第二个图我们用二次函数来拟合它,这个拟合效果很好 。
③第三个图我们拟合一个四次多项式,因此在这里我们有五个参数 θ0到θ4 这样我们可以拟合一条曲线,通过我们的五个训练样本,你可以得到看上去如此的一条曲线。
这条回归直线似乎对训练数据做了一个很好的拟合,因为这条曲线通过了所有的训练实例。但是这仍然是一条扭曲的曲线。事实上,我们并不认为它是一个预测房价的好模型。
所以 这个问题我们把他叫做过度拟合或过拟合(overfitting),另一个描述该问题的术语是高方差(variance)。 高方差是另一个历史上的叫法,但是从第一印象上来说,如果我们拟合一个高阶多项式,那么这个函数能很好的拟合训练集,能拟合几乎所有的训练数据。这就面临可能函数太过庞大的问题、变量太多。
如果我们没有足够的数据去约束这个变量过多的模型 那么这就是过度拟合。
概括地说:过度拟合的问题,将会在变量过多的时候,发生这种时候训练出的方程总能很好的拟合训练数据。所以你的代价函数实际上可能非常接近于0或者就是0。 但是这样的曲线,它千方百计的拟合于训练数据,这样导致它无法泛化到新的数据样本中,以至于无法预测新样本价格。
在这里术语"泛化" 指的是一个假设模型能够应用到新样本的能力,新样本数据是没有出现在训练集中的房子。
在上图中,我们看到了线性回归情况下的过拟合。
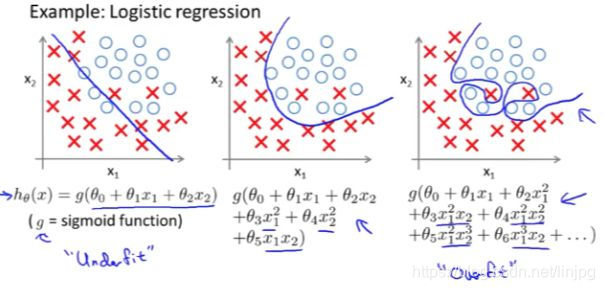
过拟合同样可能出现到逻辑回归中,如下图所示:
接下来,我们会学到调试和诊断:
诊断出导致学习算法故障的东西,以及如何用专门的工具来识别 过拟合和可能发生的欠拟合
解决过度拟合有两个办法
①第一个办法是:尽量减少选取变量的数量 。
例如 模型选择算法:
这种算法的优点:自动选择采用哪些特征变量、自动舍弃不需要的变量。这种减少特征变量的做法是非常有效的。并且可以减少过拟合的发生。
这种算法的缺点:舍弃一部分特征变量 你也舍弃了问题中的一些信息
②第二个办法是:正则化。正则化中我们将保留所有的特征变量。
二、代价函数

我们看到了,如果说我们要用一个二次函数来拟合这些数据。它给了我们一个对数据很好的拟合。然而,如果我们用一个更高次的多项式去拟合。我们最终可能得到一个曲线能非常好地拟合训练集。但是这真的不是一个好的结果,它过度拟合了数据因此一般性并不是很好。
现在我们来综合两个曲线的优势,二次曲线拟合得不错,但是均方误差比高次曲线的要大,那么我们可以找到这样一个函数,接近二次曲线的高次曲线,要实现这个函数,我们只需要将θ3 和 θ4设置得足够小,接近0就可以了。
这里给出了正规化背后的思路:如果我们的参数值对应一个较小值的话,就是说参数值比较小 那么往往我们会得到一个形式更简单的假设。

对于房屋价格预测,我们可能有上百种特征,我们谈到了一些可能的特征,比如说 x1 是房屋的尺寸 x2 是卧室的数目 x3 是房屋的层数等等。那么我们可能就有一百个特征。但是我们并不知道要将哪几个θ设置得足够小,也不知道要去缩小几个θ,因此我们可以通过添加一个额外的正则化项,来缩小我们前面的所有θ。
注意:正则化项是从θ1开始的,并且 λ 在这里我们称做正规化参数。
λ 要做的就是:
- 使假设更好地拟合训练数据
2.我们想要保持参数值θi较小

在正规化线性回归中:
如果正规化参数值被设定为非常大,那么我们会使所有这些参数接近于零:
θ1将接近零,θ2 将接近零,θ3 和 θ4 最终也会接近于零。
(因为 [公式] 这一额外的正则化项小,接近于0。)
(因为θ0 = 1,所以从θ1开始正则化)
如果我们这么做,那么就是我们的假设中,相当于去掉了这些项。
并且使我们只留下了一个简单的假设,这个假设表明:房屋价格就等于 θ0 的值,那就是类似于拟合了 一条水平直线。
对于数据来说,这就是一个欠拟合 (underfitting) ,这种情况下,这一假设它是条失败的直线,对于训练集来说,这只是一条平滑直线,它没有任何趋势,它不会去趋向大部分训练样本的任何值。
这句话的另一种方式来表达就是:这种假设有过于强烈的"偏见" 或者过高的偏差(bais), 认为预测的价格只是等于 θ0。
为了使正则化运作良好,我们应当注意一些方面,应该去选择一个不错的正则化参数 λ 。
并且当我们以后讲到多重选择时,在后面的课程中,我们将讨论一种方法:一系列的方法来自动选择正则化参数 λ ,这就是高度正则化的思路。
三、线性回归正则化

这是正则化以后的代价函数的梯度下降迭代算法
具体来说 (1-αλ/m ) 通常是一个具体的实数,而且小于1。由于αλ/m很小,所以(1-αλ/m )将是一个比1小一点点的值。所以我们可以把它想成一个像0.99一样的数字。
所以对 θj 更新的结果,我们可以看作是被替换为 θj 的0.99倍。另外 θj 后边的第二项,这实际上与我们原来的梯度下降更新完全一样。
跟我们加入了正则项之前规则大致是一样的,不同的是:
当我们使用正则化线性回归时,我们需要做的就是在每一个被正规化的参数 θj 上乘以了一个比1小一点点的数字,也就是把参数压缩了一点。然后,我们执行跟以前一样的更新。

这是正则化以后的代价函数的正规方程

正规化方程推导步骤:
关于不可逆性的问题,如果你的样本数量m 比特征数量n小的话,那么这个矩阵 X 转置乘以 X 将是 不可逆或奇异的(singluar) 。或者用另一种说法是这个矩阵是退化(degenerate)的。
如果你在 Octave 里运行它,无论如何,你用函数 pinv 取伪逆矩阵。这样计算理论上方法是正确的,但实际上,你不会得到一个很好的假设。
正规化也为我们解决了这个问题,具体地说只要正则参数是严格大于0的,这个矩阵将不是奇异的,即该矩阵将是可逆的。因此,使用正则化还可以照顾一些 X 转置乘以 X 不可逆的问题。
四、逻辑回归正则化
对于逻辑回归,我们之前已经看到,如果您使用这种非常高阶的多项式拟合逻辑回归,也可能容易出现过度拟合。

以上我们通过惩罚参数θ1、θ2等等直到θn。
如果你这样做,那么它会产生这样的效果,即使你正在拟合一个具有很多参数的非常高阶的多项式。
只要你应用正则化并保持参数小,你就更有可能获得决策边界。(玫红色曲线) 分离正面和负面的例子看起来更合理。

这是逻辑回归的梯度下降更新算法,它和线性回归是一样的,但是实际上不一样,因为假设函数是不一样的。
