有这么几个问题:1、什么是正则化?2、为什么要用正则化?3、正则化分为哪几类?
在机器学习中我们经常看到在损失函数后会有一个正则化项,正则化项一般分为两种L1正则化和L2正则化,可以看做是损失函数的惩罚项。惩罚项的作用我认为就是对模型中的参数限制,从而防止过拟合。
- L1正则化就是参数向量的1范数:对参数向量各个分量去绝对值求和
- L2正则化就是参数向量的2范数:对参数向量各个分量求平方和
在线性回归模型中使用L1正则化的模型叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。
那么正则化是怎么得来的呢?
最初始的问题还是如何防止过拟合。在这里我们用一个多项式模型(h(θ) = θ0*x0 + θ1*x1 + .....+θn*xn)来代表我们的模型,为什么能代表我们的模型呢?根据高数中的泰勒展开式,我们可以知道任何函数都可以用多项式去逼近(如lnx,e^x,logx等),不同的函数就是这些基础函数的组合。我们假设模型的损失函数为J(θ)。我们的目标就是最小化J(θ)。
在我们训练模型拟合参数的时,如何选择合适的N(参数的个数)就很重要。N过大(每个特征都对模型产生作用)就会对训练集拟合的非常好(过拟合),N过小(对模型重要的特征没有包含在模型中)就会产生欠拟合。很显然这两种现象都是我们不想看到的。欠拟合可以通过增加模型中包含的特征数量从而改善(这句话待定)。而过拟合就很难解决,我们也不知道哪些特征是无用或用处不大的。所以一群聪明的人就想到了如何控制N的数量,而控制N的数量就是控制参数向量(θ)中非零项的个数。所以聪明的人就想到了用0范数(向量中的非零项个数),那么控制N的数量问题就变成了最小化参数向量(θ)的0范数(min||θ||o)。但是0范数求起来又很困难(NP难问题),所以就退而求其次去求1范数。为了保证求1范数和0范数效果是等价的,**的人总结出了下面的式子:
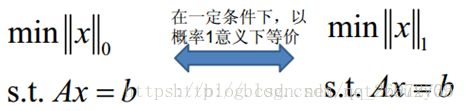
一定条件:包含了许多的算法,例如主成分分析(PCA)等
综上,我们希望最小化J(θ)的同时,还有一个限制条件就是参数向量(θ)的0范数,为了同时满足这两个条件,有点类似于拉格朗日乘子法,我们让这两项求和同时取最小值,从而得到了我们常见的带L1正则化项的损失函数模型。
L2正则化就是一个道理,但是与L1有所取别:L2正则化会令每一个参数都尽可能的小但是都不会为0,L1会令参数等于0,所以更常用的还是L2正则化(每一个特征对模型都有作用。)

参考资料:https://www.zhihu.com/question/20924039
https://blog.csdn.net/jinping_shi/article/details/52433975