Explaining and Harnessing Adversarial Examples
注:研究不深,纯个人理解,可能有误
1论文简介:
Szegedy提出有几种机器学习的模型容易受到对抗样本的攻击。在训练数据的不同子集上训练的具有不同体系结构的模型会误分类同一对抗样本。这表明对抗样本暴露了我们训练算法中的基本盲点。
为什么?:
猜想:由于深度神经网络的极端非线性所致,极端非线性可能与纯监督学习问题的模型平均不足和正则化不足有关。(即在假设空间中选择的模型不足够好)
证明:猜想是不必要的。高维空间中的线性行为足以造成对抗样本。此观点使我们能够设计一种快速生成对抗性样本的方法,从而实现对抗训练。对抗训练能够提供单独使用dropout以外的正则化好处,通用的正则化(一种为了减小测试误差的行为)策略(dropout, pretraning, model averaging)不能显著的降低模型对对抗样本的脆弱性,但是改用非线性模型族就可以(如RBF网络(多变量插值的径向基函数,径向基函数是一个取值仅仅依赖于离原点距离的实值函数))。
线性易于训练的模型、用非线性的性能来抵抗对抗性扰动的模型,这两种存在根本性的张力。最好的解决方法就是设计出更强大的优化方法,可以成功地训练更多的非线性模型。
2相关工作
(Szegedy)神经网路和相关模型的多种有趣特性:
A、盒子约束的L-BFGS(L-BFGS算法是一种在牛顿法基础上提出的一种求解函数根的算法)可以可靠地找到对抗样本;
B、 某些数据集,如ImageNet,对抗样本与原始数据的差别人眼无法区分;
C、 相同的对抗样本通常会因为有不同体系结构或在训练数据的不同子集上进行训练的各种分类器被错误分类;
D、Shallow softmax 回归模型容易受到对抗样本的影响;

E、 对抗样本的训练可以是模型规则化,但是需要在内部循环中进行昂贵的约束优化,因此这在当时不切实际。
这些结果表明,基于现代机器学习技术的分类器,即使是在测试集上获得出色性能的分类器,也无法学习确定正确输出标签的真正基础概念。(即都是黑盒测试,没有可解释性,但是效果很好)
比如:计算机视觉中一种流行的方法是将卷积网络特征用作欧几里得距离近似于感知距离的空间。如果感知距离很小的图像对应于网络表示中的完全不同的类别,则这种相似性显然是有缺陷的。
这种结果通常被认为是深度网络的缺陷,尽管线性分类器也有同样的问题。作者认为对这一缺陷的研究是修复它的机会。
3对抗样本的线性解释
线性模型的对抗样本的存在性:
单个输入特征的精确度有限。
示例:
数字图像通常每个像素8位,那么它们会丢弃低于1 /255动态范围的所有信息。
因为特征的精度是有限的:
输入:x 对抗输入: x‘ = x + η ( η 足够小,小于特征的精确度)
那么分类器就应该把x与x'分为同一类。
考虑权重向量和对抗样本的点积:
ωTx' = ωTx + ωTη
此时的对抗扰动的激活度增加到ωTη。在的最大范数(向量中各个元素绝对值的最大值)约束下,通过设定η=sign(ω)来最大化此增量。
如果ω权重向量,具有n维,元素平均大小为m,那么激活度就增长到εmn。
||η||∞不随问题的维度增加而增加,但是扰动引起的激活变化可以随n线性增长,所以对于高维问题,对input进行很多无穷小的变化,累加起来就能对output有很大的影响。
结论:如果简单线性模型的输入具有足够的维度,则可以具有对抗样本。也可以解释为什么softmax回归容易受到对样本的影响。
4非线性模型的线性扰动
对抗样本的线性观点提出了一种生成对抗样本的快速方法。我们假设神经网络过于线性无法抵抗线性对抗性扰动。
LSTM、Relu、maxout网络都是有意设计成以非常线性的方式表现的,因为更容易优化。非线性模型(如sigmoid 网络)为了更容易优化,也将大部分时间花在调整为非饱和、更线性的状态。
这些线性行为表明,简单的线性模型的解析扰动也能破环神经网络。
θ:模型的参数
x:模型的输入
y:目标(用于有监督的学习)
J(θ,x,y):损失函数cost
可以围绕当前θ的值线性化损失函数,以获得η的最优最大范数约束插值
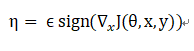
将其称为生成对抗样本的“fast gradient sign method”。可以使用反向传播有效地计算所需的梯度。
该方法非常有效的让各种模型将其input错误分类。
在以下两个数据集上的验证:
ImageNet数据集:

MNIST数据集:
| 精准度 |
classifier |
error rate |
average confidence |
| 0.25 |
shallow softmax |
99.9% |
79.3% |
| maxout network |
89.4% |
97.6% |
|
| 0.1 |
maxout network |
87.15% |
96.6% |
生成样本的其他简单方法也存在。 例如将x沿梯度方向旋转小角度也会产生对对抗样本。
这些简单、低效的算法能够产生错误分类的事实,正好作为证据支持对抗样本是线性的结果这一解释。这个算法也可以作为一种加速对抗训练的方法,或者仅仅是分析训练好了的网络。
5线性模型的对抗训练与权重衰减
Logistic regression:
逻辑回归中FGSM方法是精确的,然后了解如何在简单的设置中生成对抗样本。
训练一个单模型来识别标志y属于{-1,1}
其中:P(y=1)=σ(ωTx+b) 且σ()x是logistic sigmoid function
然后训练包括下面函数的梯度下降

ζ(z)=log(1+exp(z))是softplus function
可以基于梯度符号扰动导出简单的分析形式,用于训练x的最坏情况的对抗扰动而不是x本身。
梯度的符号是sign(ω),而且ωTsign(ω)=||ω||1,所以逻辑回归的对抗形式是最小化下面的函数
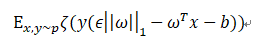
此方法类似L1正则化。
对比:训练过程中L1正则化是减去L1惩罚,而不是加上training cost,说明如果模型学习的足够好,惩罚最终可能会消失。那么L1正则化在underfitting的情况下,对抗训练只会使自身情况变得更糟糕。所以,可以认为L1权重衰减是比对抗训练“更坏的情况”,因为在good margin的情况,对抗训练不会失效。
Softmax regression:
在多分类情况下,L1权重衰减更加的悲观。因为,它把softmax的每个输出独立的进行扰动,但事实上不可能找到一个单一的η与该类的所有权重对齐。
深层网络中Weight decay高估了扰动效果,所以要使用比特征精确度相关的ε值更小的L1权重衰减系数。较小的权重衰减系数能够成功训练,但不会带来正则化好处。
6深度网络的对抗训练
批评深度网络容易受对抗样本的攻击是被误导了,它不像浅层线性模型,深度网络至少能够代表抵抗对抗性扰动的功能。The universal approximator theorem表示,只要允许其隐藏层具有足够的神经元,具有至少一个隐藏层的神经网络就可以以任意精度表示任何函数。
The universal approximator theorem并没有说明训练算法是否能够发现具有所有所需属性的函数。标准的有监督训练并未指定所选功能要抵抗对抗样本。所以要以某种方式将其编码在训练过程中。
Szegedy,表明,通过训练对抗样本和干净样本的混合集,能够对网络进行一定的正则化。对抗样本的训练和其他的数据增强方案有所不同:通常就是转换数据(如翻译,希望在测试集会出现)来扩充数据,但这种以模型概念化其决策功能的方式暴露了缺陷。
但是这个算法一直没有改善,因为很难对基于L-BFGS的昂贵的对抗样本进行广泛实验。
作者发现基于FGSM的对抗目标函数训练是一种有效的正则化器:

这种方法会不断更新对抗样本,以使其抵抗当前模型版本。
该模型在某种程度上也可以抵抗对抗样本。对抗样本可在两个模型之间转移,但对抗性训练的模型显示出更高的鲁棒性。学习模型的权重发生了显着变化,而经过对抗训练的模型的权重明显更具局限性和可解释性。
当数据被干扰时,对抗训练过程可以被看作是使最坏情况的错误最小化(即防止被干扰)。对抗训练也可以看作是主动学习的一种形式,其中模型能够请求新的点的标签(通过附近(能够得到附近的点是对抗训练的扰动造成的)的标签复制过来)。
还可以通过对最大范数框内的所有点进行训练,或者对该框内的很多点进行采样,来对模型进行正则化,使其对小于精度的特征变化不敏感。这相当于在训练过程中以最大范数增加噪声。我们可以将对抗训练看作是在嘈杂的输入中进行艰苦的样本挖掘,以便仅考虑那些强烈抵抗分类的嘈杂点来更有效地进行训练。
由于符号函数的导数在任何地方都是零或未定义,因此FGSM的对抗目标函数的梯度下降无法使模型预测对手对参数变化的反应。但是基于小旋转或按比例缩放的梯度的对抗样本,则扰动过程本身是可区分的,学习可以将对手的反应考虑在内。但是,发现此过程的正则化结果几乎没有强大的功能,因为这类对抗样本并不难解决。
扰动输入层或隐藏层或同时扰动两者那种情况更好?
Sigmoidal network :隐藏层,规则化效果更好
具有隐藏单元的激活不受限制的网络:输入层
Maxout network: 隐藏层的旋转扰动
我们对对抗性训练的观点是:只有在模型具有学习抵抗对对抗样本的能力时,它才明显有用。仅当应用The universal approximator theorem时,情况才很明显。而且因为神经网络的最后一层是linear sigmoid或linear softmax层,不是最终隐藏层功能的通用逼近器,所以很可能会遇到拟合不足的问题隐藏层,使用隐藏层扰动但不涉及最终隐藏层的扰动进行训练得到最佳结果。
7不同类型的模型容量
很多人认为容量(拟合各种函数的能力)低的模型无法做出很多不同的置信预测,这是不正确的。虽然有些模型确实表现出这种现象,如下面函数条件下的shallow RBF networks

只能有信心的预测出现在μ附近的正类。其他的地方,默认不存在或者是低置信度。
RBF网络天生不受对抗样本的影响,或者说,它被欺骗时信心不足。所以它会通过大幅降低其对“无法理解”的点的置信度来做出正确的响应。
线性单元:响应每个输入实现较高的查全率(即召回率),精度较低
RBF单元:响应特定的输入达到高精度,牺牲召回率(分类正确数/所有正确数),
探索各种涉及二次单元的模型,包括深层RBF网络很难,因为使用SGD训练时,具有足够二次抑制能力以抵抗对抗性扰动的每个模型都获得了很高的训练集误差。
8为什么对抗性例子会泛化?
为一个模型生成的对抗样本也经常被其他模型分错,尽管结构不同,使用的训练集也不交叉。
为什么多个具有多余容量的极非线性模型始终用相同的方式标记出分布点?
假设:对抗样本像现实中的有理数一样精细地平铺空间。所有对抗样本很常见,但仅在非常精确的位置发生。
在线性视图下,对抗样本出现在较宽的子空间中。方向只需要具有损失函数的梯度的正点积,并且只需要足够大即可。
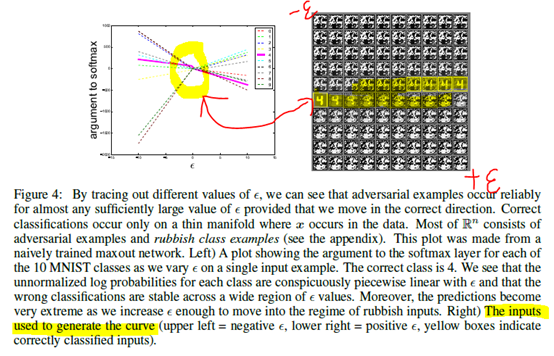
通过追踪不同的值,看到对抗样本出现在由FGSM定义的一维子空间的连续区域中,而不是在细小口袋中。这就解释了为什么对抗样本很多,为什么一个分类器分类错误的样本具有较高的先验概率被另一个分类器分类错误。
为什么多个分类器将相同类别分配给对抗样本?
假设:使用当前方法训练的神经网络都类似于在同一训练集上学习的线性分类器。
当在训练子集上进行训练时,此分类器能够学习大约相同的分类权重,因为机器学习算法的泛化能力。基础分类权重(即能够学习大约相同的分类权重)的稳定性反过来又导致对抗样本的稳定性。
检验该假设:

我们的假设无法解释maxout network的所有错误或跨模型泛化的所有错误,但显然其中很大一部分与线性行为一致,线性行为是跨模型泛化的主要原因。
9假设检验
思考并反驳一些对抗样本相关的假设。
1、 假设:生成训练(generative training)可以对训练过程有更多的约束,或者是模型学习从“假”数据中区分“真实”数据,并对“真实”数据有信心。
检验:
MP-DBM(多预测深玻尔兹曼机):它的推理过程在MNIST上具有良好的分类精度(错误率0.88%),该推断过程是可区分的(differentiable);本身来对付对抗样本,不依赖其他模型;容易受到对抗样本的攻击。
其他模型:推理过程不可微(non-differentiable);很难计算得到对抗样本,需要其他的其他非生成性鉴别器模型,才能在MNIST上获得良好的分类精度。
结论:生成训练的其他形式仍然有可能赋予抵抗力,但显然,仅产生生成这一事实并不足够。(即假设不一定成立)
2、 假设:单个模型有一些奇怪的特性,但对很多模型求平均可以使对抗样本淘汰。
检验:
在MNIST数据集上训练了12个maxout network(每个网络都使用不同的seed进行训练,以用于随机数生成器,该随机数生成器用于初始化权重,生成丢失掩码以及选择数据的最小批来进行随机梯度下降)
ε=0.25,干扰整个集合的对抗样本,集合的错误率为91.1%;干扰一组成员的对抗样本,错误率为87.9%。
结论:集合仅提供有限的抵抗对抗性干扰的能力。
10总结讨论
1对抗样本可以解释为高维点积的属性,它们是模型过于线性而不是非线性的结果。
2可以将对抗样本在不同模型之间的泛化解释为:对抗性扰动与模型的权重向量高度对齐,并且不同模型在训练以执行相同任务时会学习相似的功能。
3扰动的方向最重要,而不是空间中的特定点。
4因为最重要的是方向,所有对抗性扰动会在不同的干净样本中概括。(即在干净样本中求梯度下降的方向)
5介绍了一系列用于生成对抗样本的快速方法。(高维空间中的线性行为足以造成对抗样本。对抗样本的线性观点。逻辑回归下的对抗样本。深度网络,扰动隐藏层,不扰动最终隐藏层获得对抗样本。)
6对抗训练可以进行正则化,甚至比dropout更正规。
7我们进行的控制实验未能使用更简单但效率更低的正则器(包括L1权重衰减和添加噪声)来重现此效果。
8易于优化的模型很容易受到干扰。(如线性模型)
9 RBF网络可抵抗对抗样本。(欺骗时信心不足,所以它会通过大幅降低其对“无法理解”的点的置信度来做出正确的响应)
10经过训练可对输入分布进行建模的模型不能抵抗对抗样本。