元信息
https://www.aclweb.org/anthology/P18-1241/
- acl18

目的
利用生成对抗样本的方式来检测图像描述系统的鲁棒性。之前的工作集中于针对图像分类的对抗样本攻击,这是第一篇检测视觉和语言结合的系统中的对抗样本攻击,同时之前多是研究如何攻击CNN模型,这也是第一次去研究攻击CNN+RNN模型,特别是研究攻击RNN模型。
提出了两种攻击场景:
- Targeted caption: 给图像加一个扰动,使图像描述系统能够生成我们给定的targeted caption
- Targeted keyword: 给图像加一个扰动(即生成对抗样本),使图像描述系统能够生成包含我们给定的若干关键词的caption
注意:生成的对抗样本在视觉上与原始样本无法区分(失真很小),但是能够误导图像描述模型给出错误的caption
方法
形式化描述
该任务的目标即给定一张图像\(I\), 分别生成符合上述两种攻击场景要求的对抗样本。具体则是解一个有约束优化问题:
上面公式的意思就是最小化任务loss同时还要保持对抗样本和原样本之间的像素级别的内容一致性,\(c\)是一个正则因子。下面这个约束条件则是保证像素的取值要在\([-1,1]\)之间,即加了扰动后,还是在图像的取值空间中。
为了方便解决,先要把它转换为一个无约束优化问题,也就是想办法去掉这个约束条件。这里,可以先假定\(I+\delta\)满足这个边界约束,利用\(\operatorname{arctanh}\)和\(\tanh\)的取值范围和关系来做。也就是可以令:
注意到这个\(w\)参数取值是无约束的,从而我们可以将有约束的\(I+\delta\) 表示为无约束的\(w\)的表达式:
从而上面的问题就可以改写成:
下面就开始研究两种不同攻击场景的loss函数设计。
Targeted caption
给定目标caption:
目标就是给定含扰动的图像,能够生成这个caption,即对于所有可能的caption,最有可能,即概率最大的是生成这个目标caption。
后面那项就是:
后面那项实际又是softmax输出
一般来说,最后就是将极大化取个负号,变成极小化,也就是最小化负对数似然损失,类似于这个
但是实际上,从图像分类的对抗攻击上学到的经验表示,在攻击loss中使用logit值而不是概率值能够更好地避免被别人防御,比如说采用defensive distillation(防御蒸馏)的方式。所以这里作者又提出了一种使用logit的方式。
把公式8带进公式7:
所以最大化概率的时候,就可以等价于最大化这前面一项了。
一般来说,都是希望每一个\(z_{t}^{\left(S_{t}\right)}\)要尽量大,但是作者采用了一个更巧妙的转换方法:不是要尽量大,而是在所有词的logit向量上,\(S_t\)位置的值是最大的,即top-1的值是在\(S_t\)位置上。于是他就提出了下面这个:
那个复杂的max项指的是除\(S_t\)位置的值以外的最大值,具体来说,如果\(z_{t}^{\left(S_{t}\right)}>\max _{k \neq S_{t}}\left\{z_{t}^{(k)}\right\}+\epsilon\) ,也就是说他比其他位置中的最大值还要大的话,那它就是top-1了,不用优化了,此时\(\max _{k \neq S_{t}}\left\{z_{t}^{(k)}\right\}-z_{t}^{\left(S_{t}\right)}\) 小于\(-\epsilon\) 。故相应位置上的loss就取这个值,是一个常数,不会对loss的梯度有所贡献。
相反,当他没有其他位置的最大值大的时候,我们肯定就希望他成为top-1,所以max取的是\(\max _{k \neq S_{t}}\left\{z_{t}^{(k)}\right\}-z_{t}^{\left(S_{t}\right)}\) 这一项,然后最小化loss就变成了让它和最大值尽量接近。
所以最后的loss就为:
Targeted Keyword
这个要求生成的caption里面要包含指定的M个关键词\(\left\{K_{1}, \cdots, K_{M}\right\} \subset \mathcal{V}\),但没有要求它的出现位置。看起来比上面那个简单,其实不是,因为还必须保证生成的caption是有意义的。
因为没有要求关键词的位置,所以只要存在一个合理的位置放就好(即该位置的logit值是top-1)。设计了以下loss
也就是说针对某一个关键词,在每个位置上应用上面的max项,然后取整个序列中值最小的位置进行优化。这是因为,值最小代表该位置的值最接近最大值,优化起来更加方便,因为只需要找了这样一个位置就好了,所以找最小的位置又方便优化,同时这样的位置还一定存在。
因为给的是关键词而不是targeted caption,所以训练RNN的时候会很尴尬,不知道该怎么输入。作者提出,使用原本的caption来作为初始化,迭代若干次后,然后infer出一个caption,用这个caption来作为RNN输入,再迭代若干次,直到收敛。
在这个攻击任务,还有一个尴尬的问题,就是有可能多个关键词都想占据同一个位置,也就是说有可能两个关键词在同一个位置都是top-2大的,且该位置的差值还是整个序列中最小的。为了避免这种位置冲突的问题(因为不可能一个位置放两个关键词),所以就加了一个门控函数来控制:
也就是说,比如两个关键词都在同一个位置拥有top-2的大小,但是优化速度可能不尽相同,在某一个时刻,一个关键词先达到最大值,也就是位置被A占掉了,那么对于其他关键词在该位置的差值就永远等于一个非常大,大过一般logit取值范围的值A,这时再使用min函数就永远取不到该位置了。
实验
用了一个预训练的CNN+RNN模型。
选择的目标caption和图像都是从MSCOCO的validation set里面找的,找了1000条。
- 之所以在验证集上找是为了保证目标caption在caption system的生成空间中。比如说,该系统从未被训练过去生成被动语态的句子,那该模型肯定无法生成被动语态的目标caption。其实就是为了排除一个out of domain的问题。
最后用一些指标去评价生成的caption与目标caption之间的关系。
实验结果
成功的对抗样本:
- 指的是生成的caption与目标caption完全一致
- 包含所有需要包含的关键词
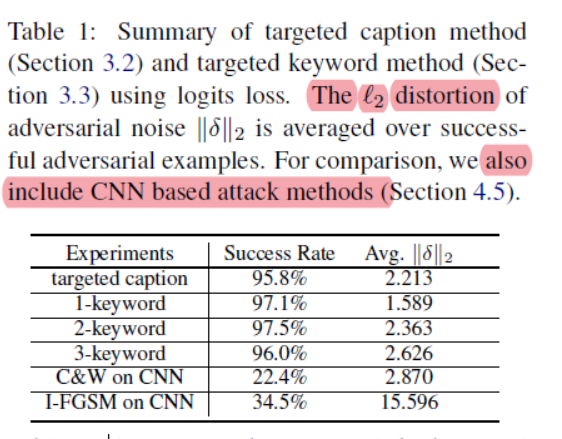


对于3-keyword,有4%是失败的,作者也分析了失败中的情况,发现生成的caption平均也能包含1.5个关键词。

对抗样本的迁移性
可以迁移:这个对抗样本这个模型A上生成的目标句子SA与在另一个模型生成的句子SB语义上相似。
作者比较了Show and tell 和show and attend tell

ori:同一个模型上,生成的caption和原始样本配对的caption之间的相似度
tgt:不同模型上,使用对抗样本生成的target caption之间的相似度
mis:不同模型上,使用原始样本生成的caption之间的相似度 (来度量tgt之间的差异是不是受了模型不匹配的影响)
一般来说,越小的ori,越大的tgt,迁移性更好,tgt更加接近mis的效果,迁移性更好。
增加\(c\)或\(\epsilon\)可以增加迁移性
