explaining and harnessing adversarial examples(FGSM)
论文简述
本文依旧是Ian J. Goodfellow大神的系列,提出神经网络对对抗样本的脆弱性的根本原因是其线性特征,这也解释了对抗样本在结构和训练集上的泛化性,并在此基础上提出了FSGM算法用来生成对抗样本。
论文重点
先前工作
- 对抗样本的存在说明,即使我们当前的模型可以来解释训练数据或者正确标签测试数据,但是不代表它完全理解了我们实际想让它展示的效果。
- 对抗样本的原因有认为是极端的非线性、模型平均不足以及正则化不足等
对抗样本的线性解释
作者则认为正是由于高维空间的线性行为才导致了对抗样本的存在,因此要在容易训练的线性特征和抵抗对抗样本的非线性特征之间做trade off。
当前输入特征的精度是有限的,当各个维度的扰动小于精度时,应产生相同的分类结果
假定扰动: 1 norm,2 norm,∞ norm
,则扰动在该范围内取最大的形式为
。
则对于线性模型来讲:
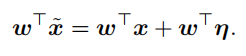
虽然扰动受到约束,但激活却会随参数w的维度和数值的增长而线性增长:
。
- 正是这种线性结构,使得微小的扰动却对分类结果产生重要的影响。
非线性模型的线性扰动
- 假定神经网络足够的线性化,导致其也不能抵抗对抗样本。(线性结构、非线性结构的非饱和,线性区域)
maxout network - 攻击样本的思想:追求以微小的修改,通过激活函数的作用,对分类结果产生最大化的变化。
- 如果我们的变化量与梯度的变化方向完全一致,那么将会对分类结果产生最大化的变化。sign函数用来保持变化量方向
此时的最优攻击样本是,也即FGSM(fast gradient sign method)
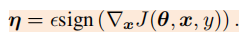
但之后作者给出的
并不是小于图像精度的,所以扰动幅度并不算特别小。
- 两个标准:错误率(error rate)是说误判的百分比,置信率(confidence):是指分类器认为该图像是错误类别的百分比,错误率和置信率越高,则说明生成的对抗样本越强势
- 正是因为线性响应,使得他们在训练数据分布中未出现的数据保持过度自信
- 其他生成对抗样本的方式:如沿梯度方向旋转原图像x一个小的角度
作者的思路总是很清晰且易懂,但却能发现问题和产出效果,真的很厉害。
*线性模型的对抗扰动推导及对抗训练
逻辑回归推导,目标值为{-1,1}或{0,1}两种形式 https://www.cnblogs.com/daguankele/p/6549891.html
林轩田机器学习逻辑回归函数,目标值为{-1,1}的推导公式:https://blog.csdn.net/red_stone1/article/details/72229903

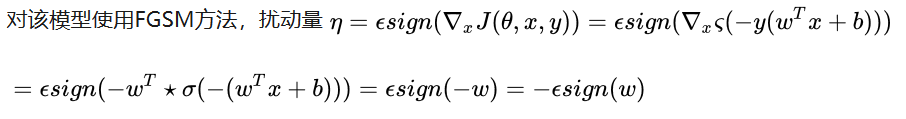
此处的y省略掉了,y指的是y_true,也即考虑的是y=1的情况。
则利用对抗扰动 作为正则项 来进行优化的损失函数为:
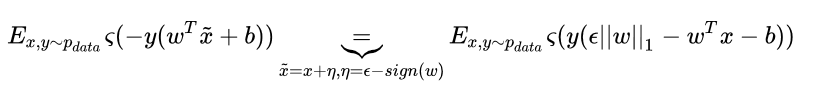
公式来源:https://zhuanlan.zhihu.com/p/32784766
正则化,权重衰减
*非线性模型的对抗训练
公式(持续更新对抗样本):
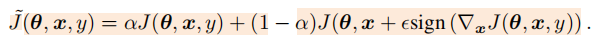
结论:
- 对抗训练能在dropout的基础上使训练结果有所提升或相差不大
- 好处在于对抗训练后的模型对对抗样本具有更好的鲁棒性
- 但对抗训练后的模型如果误认了对抗样本,仍然有很高的置信度
- 对抗训练类似于hard example mining,利用产生的随机噪声无法用来抵抗对抗样本
- 容量(拟合各种函数的能力)低的模型能够精准的逼近当前模型,所以可以抵抗对抗样本,但泛化性差;容量高的模型泛化性强,但也因此无法抵抗对抗样本。
- 如果我们设计一个模型,在指定位置精准逼近(类似于瓶颈形式),筛选掉对抗样本,再提高泛化性,有没有可能让两者很好的结合呢???
对抗样本的泛化性解释
- 对抗样本具有泛化性,且误判的分类通常保持一致。
- 由于模型的线性化,对抗样本存在于广泛的子空间中,而不是特定的某些位置(类似实数在有理数中一样)
- 扰动的方向更重要些,我们就只需要找准对抗样本的方向,然后使扰动足够大,就能产生对抗样本。
- 泛化性的原因是由于当前的方法论学到的权重是相似的,则对抗样本存在的子空间基本一致,也因此对抗样本具有迁移性。
不足之处
(未经过验证)
- 不定向攻击,无法做到定向攻击。
- 而且这种攻击的鲁棒性不强,添加的扰动容易在图片的预处理阶段被过滤掉。
- 尽管提出的对抗训练方式可以提高模型的泛化能力,从而在一定程度上防御对抗样例攻击,但这种防御方法只针对一步对抗样例攻击有效,攻击者仍可以针对新的网络构造其他的对抗样例。
思考
- 虽然不一定是正确解释,但感觉大神的思路就是很清晰明了
- 可以考虑模型,将精准模型与拟合性好的模型相结合