AI视野·今日CS.CV 计算机视觉论文速览
Fri, 11 Oct 2019
Totally 29 papers
?上期速览✈更多精彩请移步主页

Interesting:
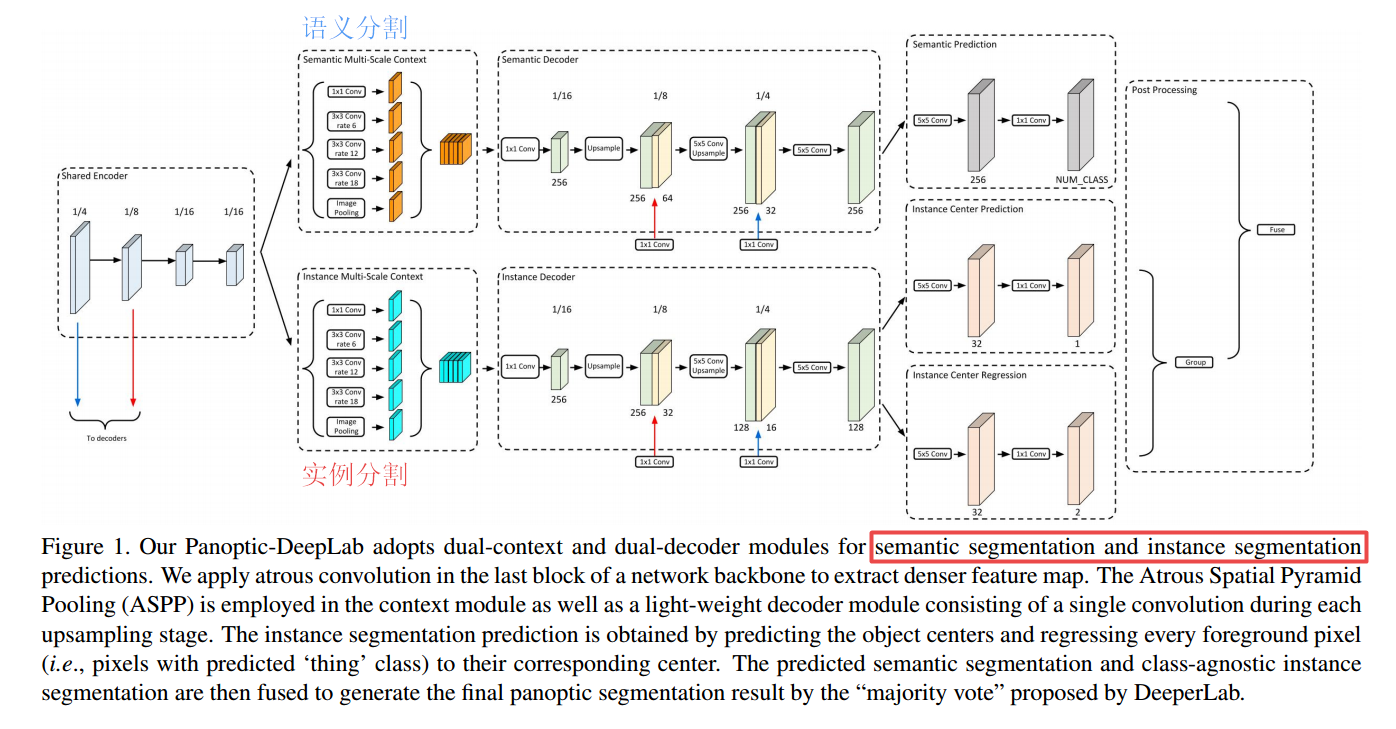
?*****全景图像分割网络 Panoptic-DeepLab, (from google UIUC)
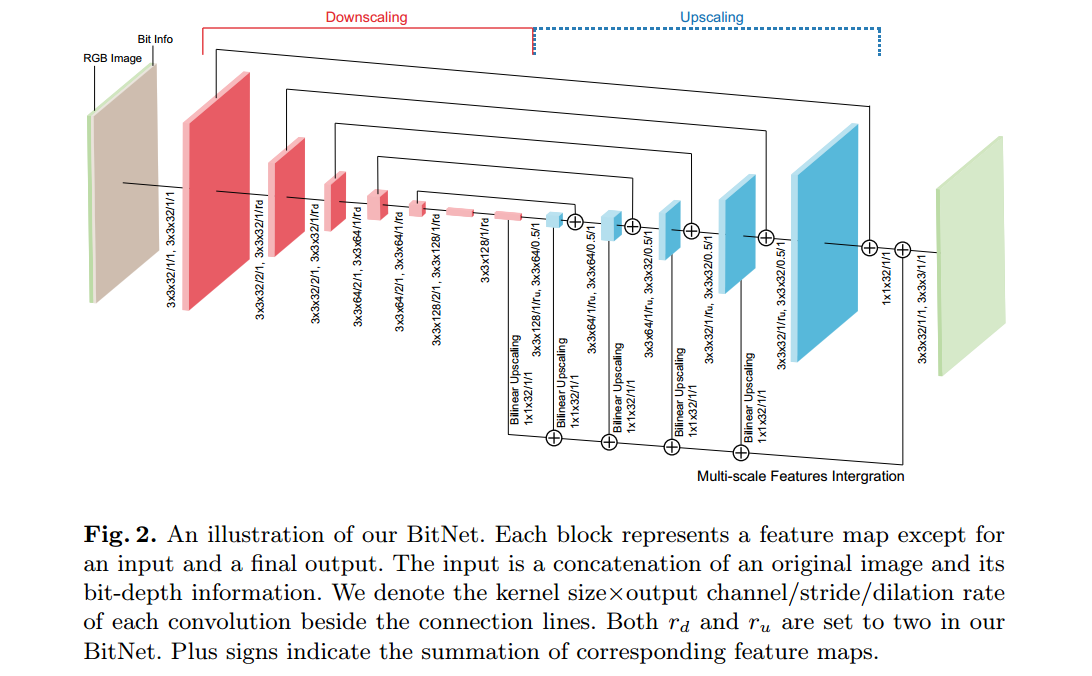
?**BitNet提高图像位深的模型 增加图像的色彩分辨率, (from KAIST)

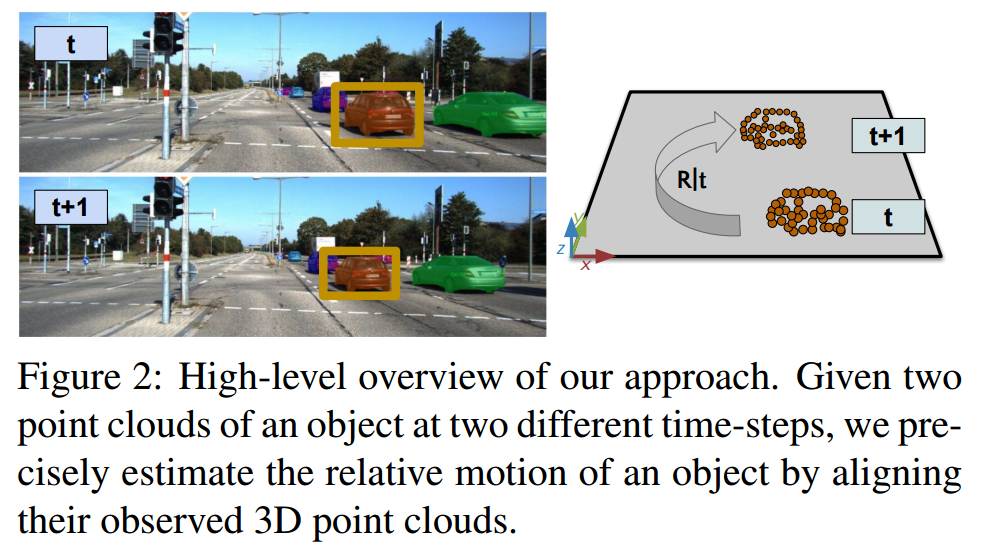
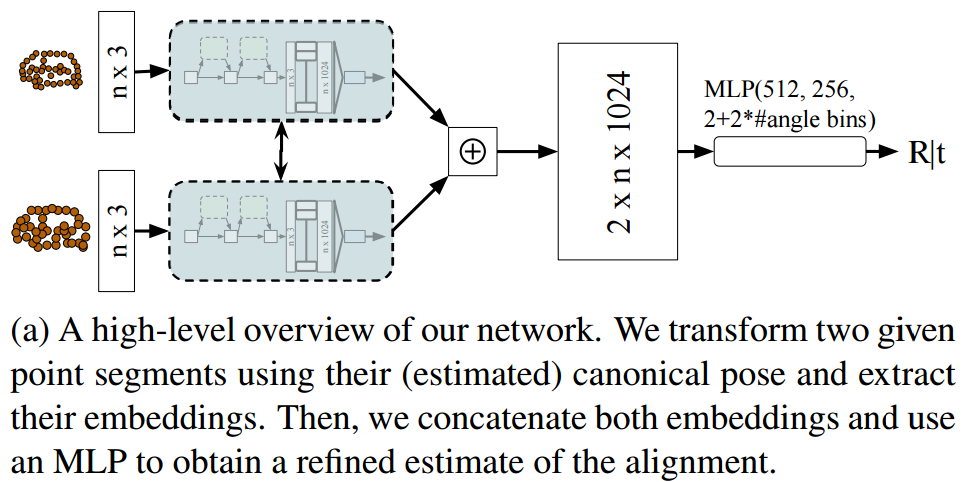
?AlignNet-3D快速匹配部分可视目标的点云, (from 亚琛工业大学)
code:https://www.vision.rwth-aachen.de/page/alignnet
?训练低秩剪枝的高效神经网络 low-rank approximation, (from fSJTU)
code:https://github.com/yuhuixu1993/Trained-Rank-Pruning
Daily Computer Vision Papers
| Panoptic-DeepLab Authors Bowen Cheng, Maxwell D. Collins, Yukun Zhu, Ting Liu, Thomas S. Huang, Hartwig Adam, Liang Chieh Chen 我们介绍了Panoptic DeepLab,这是一种自下而上的单镜头全景分割方法。我们的Panoptic DeepLab从概念上讲很简单,可以提供最先进的结果。特别地,我们分别采用特定于语义和实例分段的双重ASPP和双重解码器结构。语义分割分支与任何语义分割模型(例如DeepLab)的典型设计相同,而实例分割分支与类无关,涉及简单的实例中心回归。我们唯一的Panoptic DeepLab在三个Cityscapes基准上都设置了新的技术水平,测试集达到了84.2 mIoU,38.2 AP和65.5 PQ,并在另一个具有挑战性的Mapillary Vista上取得了进步。 |
| Referring Expression Object Segmentation with Caption-Aware Consistency Authors Yi Wen Chen, Yi Hsuan Tsai, Tiantian Wang, Yen Yu Lin, Ming Hsuan Yang 引用表达是自然语言的描述,用于标识场景中的特定对象,并广泛用于我们的日常对话中。在这项工作中,我们专注于在由引用表达式指定的图像中分割对象。为此,我们提出了一种端到端的可训练理解网络,该网络由语言和视觉编码器组成,以从两个域中提取特征表示。我们引入了空间感知型动态过滤器,以将知识从文本传递到图像,并有效地捕获指定对象的空间信息。为了更好地在语言和视觉模块之间进行交流,我们使用了字幕生成网络,该网络以跨两个域共享的功能作为输入,并通过使生成的句子类似于给定引用表达式的一致性来改进两种表示形式。我们在两个引用的表达式数据集上评估了提出的框架,并表明我们的方法相对于最新算法表现良好。 |
| CATER: A diagnostic dataset for Compositional Actions and TEmporal Reasoning Authors Rohit Girdhar, Deva Ramanan 计算机视觉已经在性能上发生了巨大的革命,这在很大程度上是受在大规模监督数据集上训练的深度特征的驱动。但是,这些改进中的许多改进都集中在静态图像分析上,而视频理解则是相当适度的改进。即使已经提出了新的数据集和时空模型,但简单的逐帧分类方法仍然仍然具有竞争力。我们假设当前的视频数据集在场景和对象结构上存在隐性偏差,这可能会使时间结构的变化相形见war。在这项工作中,我们建立了一个具有完全可观察和可控制的对象和场景偏差的视频数据集,并且它确实需要时空理解才能解决。我们的数据集名为CATER,是使用标准3D对象库进行综合渲染的,它测试了识别需要长期推理的对象运动组成的能力。除了具有挑战性的数据集外,CATER还提供了许多诊断工具,可以通过完全可观察和可控制的方式来分析现代时空视频体系结构。使用CATER,我们可以洞悉一些最新的深度视频体系结构。 |
| MetaPix: Few-Shot Video Retargeting Authors Jessica Lee, Deva Ramanan, Rohit Girdhar 我们解决了无监督地将人类行为从一个视频重定向到另一个视频的任务。我们考虑到具有挑战性的设置,其中只有几帧目标可用。我们方法的核心是一个条件生成模型,该模型可以对由现成的姿势估计器自动提取的输入骨骼姿势进行转码,以输出目标帧。但是,构建通用代码转换器具有挑战性,因为由于衣服和背景场景的几何形状,人类看起来可能会出现巨大差异。取而代之的是,我们学会使通用发生器适应目标的特定人员和背景或使其个性化。为此,我们利用元学习来发现即时个性化的有效策略。元学习的一个重要好处是,个性化转码器自然会在其生成的帧之间强制执行时间一致性,所有帧都包含目标的一致服装和背景几何。我们在野外的互联网视频和图像中进行了实验,并表明我们的方法在此任务的广泛使用的基准上有所改进。 |
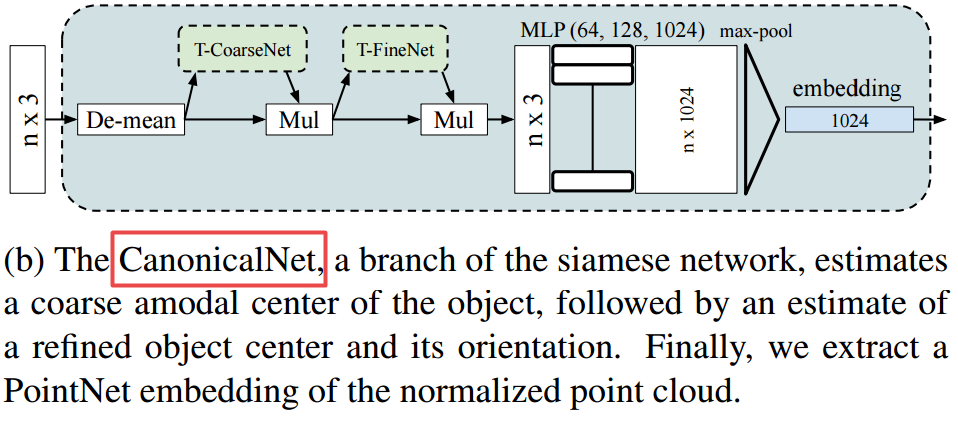
| AlignNet-3D: Fast Point Cloud Registration of Partially Observed Objects Authors Johannes Gro , Aljosa Osep, Bastian Leibe 解决多目标跟踪的方法需要估计感测区域中目标的数量以及估计它们的连续状态。尽管大多数现有方法集中于数据关联,但是精确状态3D姿态估计通常仅通过使用质心或3D边界框近似目标来粗略地估计。但是,在汽车场景中,周围人员的运动感知至关重要,并且车辆近距离范围内的误差可能会带来灾难性的后果。在这项工作中,我们专注于精确的3D轨道状态估计,并提出了一种基于学习的方法来部分观测对象的对象中心相对运动估计。我们的方法无需使用质心来近似目标,而是能够利用物体的嘈杂3D点段来估计其运动。为此,我们提出了一种简单,有效且高效的网络方法,该方法可以学习对齐点云。我们对两个不同数据集的评估表明,我们的方法在计算效率方面要优于计算昂贵的全局3D注册方法。我们在以下位置提供我们的数据,代码和模型 |
| Cross-modal knowledge distillation for action recognition Authors Fida Mohammad Thoker, Juergen Gall 在这项工作中,我们解决了一个问题,即如何对已在RGB视频等模态上进行训练的动作识别网络进行调整,以识别另一种模态(如3D人类姿势序列)的动作。为此,我们提取受过培训的教师网络的知识用于源情态,并将其转移到目标网络的一小群学生网络中。对于跨模式知识蒸馏,我们不需要任何注释数据。取而代之的是,我们使用两种模式的序列对作为监督,这很容易获得。与以前使用KL损失进行知识蒸馏的工作相反,我们证明交叉熵损失以及小学生网络整体的相互学习效果更好。实际上,所提出的交叉模式知识蒸馏方法几乎达到了在完全监督下训练的学生网络的准确性。 |
| Visual Indeterminacy in Generative Neural Art Authors Aaron Hertzmann 为什么GAN如此强大的艺术创作工具本文认为GAN艺术通常表现出视觉不确定性,这是Pepperrell创造的一个术语。 GAN通过创建合理的构图和纹理而导致视觉不确定性,尽管如此,这些构图和纹理仍无法进行连贯的解释,而这是最近艺术品中经常使用的GAN图像。由于视觉不确定性可以理解为一个感知过程,因此GAN为基于感知不确定性模型的艺术和神经科学实验提供了一种潜在的工具。 |
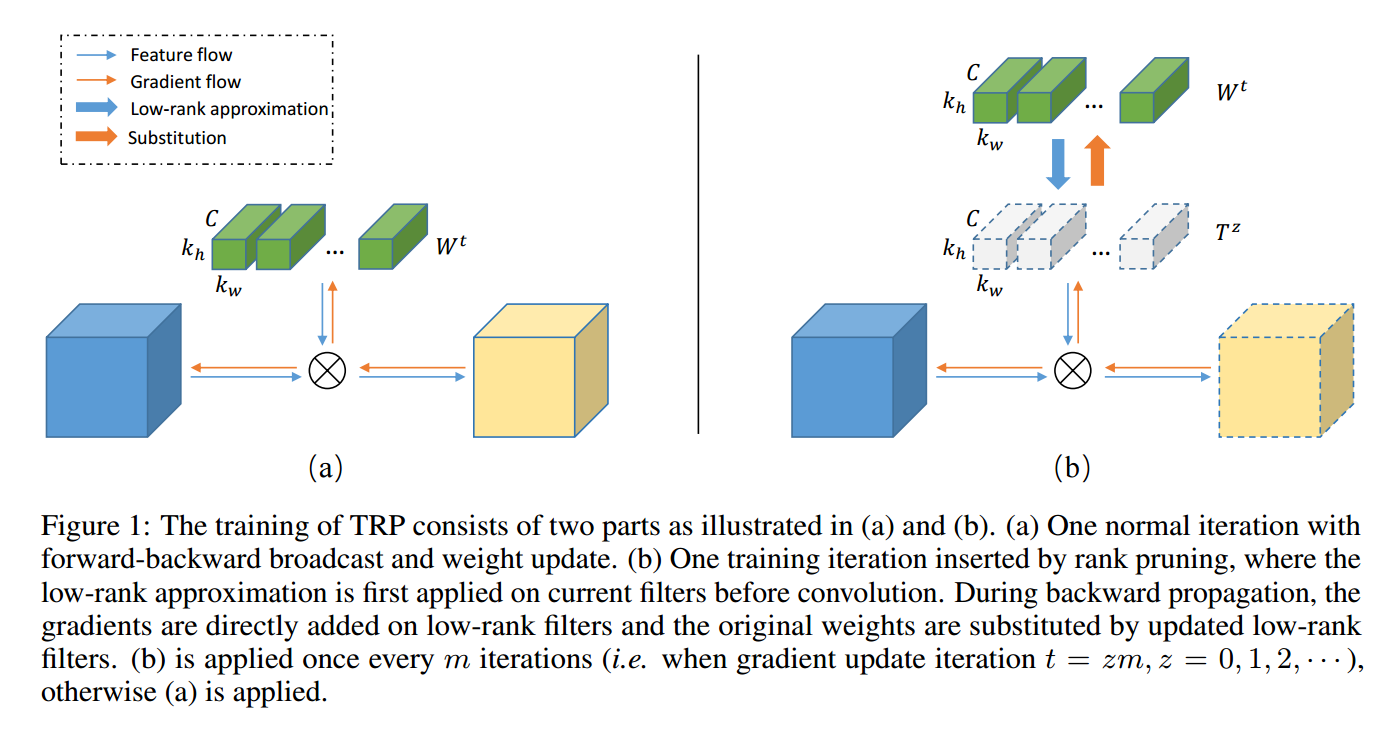
| Traned Rank Pruning for Efficient Deep Neural Networks Authors Yuhui Xu, Yuxi Li, Shuai Zhang, Wei Wen, Botao Wang, Wenrui Dai, Yingyong Qi, Yiran Chen, Weiyao Lin, Hongkai Xiong 为了加速DNN推理,由于其可靠的理论基础和有效的实现,低秩逼近已被广泛采用。先前的几项工作试图通过低秩分解直接逼近预先训练的模型,但是,参数中的小的逼近误差会在较大的预测损失上引起波动。显然,将低秩近似与训练分开并不是最佳选择。与以前的工作不同,本文将低秩逼近和正则化集成到训练过程中。我们提出训练等级修剪TRP,它在低等级近似和训练之间交替。 TRP保持原始网络的容量,同时在训练过程中施加低等级限制。利用随机亚梯度下降优化的核正则化可进一步提高TRP的低等级。经过TRP训练的网络本质上具有低秩结构,并且近似的性能损失可忽略不计,从而消除了低秩近似后的微调。在CIFAR 10和ImageNet上对所提出的方法进行了全面评估,使用低秩逼近方法优于以前的压缩方法。我们的代码位于 |
| Improving Pedestrian Attribute Recognition With Weakly-Supervised Multi-Scale Attribute-Specific Localization Authors Chufeng Tang, Lu Sheng, Zhaoxiang Zhang, Xiaolin Hu 行人属性识别已成为视频监控领域的新兴研究主题。为了预测特定属性的存在,需要定位与该属性有关的区域。但是,在此任务中,区域注释不可用。如何确定这些属性相关区域仍然具有挑战性。现有方法应用属性不可知的视觉注意力或启发式的身体部位定位机制来增强局部特征表示,而忽略采用属性来定义局部特征区域。我们提出了一种灵活的属性本地化模块ALM,以自适应地发现最具区分性的区域,并在多个级别上学习每个属性的区域特征。此外,还引入了特征金字塔体系结构,以在高级语义指导下增强低级别的特定于属性的定位。所提出的框架不需要额外的区域注释,并且可以通过多层次的深度监督进行端到端的培训。大量实验表明,该方法在三个行人属性数据集(包括PETA,RAP和PA 100K)上均达到了最新水平。 |
| Semi-Supervised Variational Autoencoder for Survival Prediction Authors Sveinn P lsson, Stefano Cerri, Andrea Dittadi, Koen Van Leemput 在本文中,我们提出了一种半监督变分自编码器,用于从肿瘤分割蒙版对整体生存组进行分类。该模型可以使用任何肿瘤分割算法的输出,从而消除了扫描平台上的所有假设以及所用脉冲序列的特定类型,从而提高了其泛化特性。由于其半监督性质,该方法可以通过使用相对少量的标记对象来学习对生存时间进行分类。我们在多模式脑肿瘤分割挑战赛BraTS 2019的公开数据集上验证了我们的模型。 |
| Searching for A Robust Neural Architecture in Four GPU Hours Authors Xuanyi Dong, Yi Yang 常规的神经体系结构搜索NAS方法基于强化学习或进化策略,这需要花费超过3000个GPU小时才能在CIFAR 10上找到良好的模型。我们提出了一种有效的NAS方法来学习通过梯度下降进行搜索。我们的方法将搜索空间表示为有向无环图DAG。该DAG包含数十亿个子图,每个子图表示一种神经体系结构。为了避免遍历子图的所有可能性,我们在DAG上开发了可微分的采样器。在训练采样的体系结构后,该采样器可通过学习损失来学习和优化。通过这种方式,我们的方法可以通过梯度下降以端到端的方式进行训练,即使用“可微体系结构采样器GDAS”进行基于梯度的搜索。在实验中,我们可以在CIFAR 10上四个GPU小时内完成一个搜索过程,发现的模型仅使用2.5M参数即可获得2.82的测试误差,与最新技术水平相当。代码在GitHub上公开可用 |
| Sentiment Analysis from Images of Natural Disasters Authors Syed Zohaib, Kashif Ahmad, Nicola Conci, Ala Al Fuqaha 社交媒体已被广泛用于检测和收集有关观点和事件的相关信息。但是,信息的相关性非常主观,而是取决于应用程序和最终用户。在本文中,我们着眼于社交媒体数据处理的一个特定方面,即通过考虑人们的观点,态度,感受和情感来对灾害相关图像进行情感分析。我们分析视觉情感分析如何通过从社交媒体中挖掘信息来改善最终用户受益者的结果。我们还将找出挑战和相关应用,这可能有助于为视觉情感分析的未来研究工作确定基准。 |
| On Recognizing Texts of Arbitrary Shapes with 2D Self-Attention Authors Junyeop Lee, Sungrae Park, Jeonghun Baek, Seong Joon Oh, Seonghyeon Kim, Hwalsuk Lee 场景文本识别STR是识别自然场景中字符序列的任务。尽管STR方法已经取得了很大的进步,但是当前的方法仍然无法识别任意形状的文本,例如在日常生活中丰富的大量弯曲或旋转的文本,例如餐厅标志,产品标签,公司徽标等。本文介绍了一种新颖的用于识别任意形状的文本的体系结构,该结构称为“自注意文本识别网络SATRN”,其灵感来自于Transformer。 SATRN利用自我关注机制来描述场景文本图像中角色的二维二维空间相关性。利用自我注意力的全图传播,SATRN可以识别具有任意排列和较大字符间距的文本。结果,在不规则的文本基准中,SATRN的性能平均要比现有STR模型高5.7 pp。我们提供的经验分析说明了该模型的内部机制和适用范围,例如旋转多行文字。我们将开源代码。 |
| Adaptive and Azimuth-Aware Fusion Network of Multimodal Local Features for 3D Object Detection Authors Yonglin Tian, Kunfeng Wang, Yuang Wang, Yulin Tian, Zilei Wang, Fei Yue Wang 本文着重于构建更强的局部特征以及图像与LiDAR数据的有效融合。我们采用不同形式的LiDAR数据来生成更丰富的特征,并提出了一种自适应的方位角感知网络来聚合来自图像,鸟瞰图和点云的局部特征。我们的网络主要由三个子网组成:地平面估计网络,区域提议网络和自适应融合网络。地平面估计网络提取点云的特征并预测用于生成大量3D锚点的平面参数。区域提议网络生成图像和鸟瞰图的特征以输出区域提议。为了集成异构图像和点云特征,自适应融合网络通过引入方位角融合模块显式调整多个局部特征的强度,并实现图像与LiDAR数据之间的方向一致性。在KITTI数据集上进行了实验,结果验证了我们整合多模式局部特征和自适应融合网络的优势。 |
| Unconstrained Road Marking Recognition with Generative Adversarial Networks Authors Younkwan Lee, Juhyun Lee, Yoojin Hong, YeongMin Ko, Moongu Jeon 随着深度学习的快速发展,最近的道路标记识别在过去几年中已取得了巨大的成功。尽管已经取得了长足的进步,但它们通常过于依赖无代表性的数据集和受约束的条件。在本文中,为了克服这些缺点,我们提出了一种替代方法,该方法可实现更高的准确性并生成高质量的样本作为数据增强。有以下两个主要贡献:1拟议的去模糊网络可以通过采用生成对抗网络GAN从模糊的道路成功恢复干净的道路标记。 2所提出的基于互信息的数据扩充方法可以从给定的数据集中保存和学习语义上下文。我们构造并训练了一个有条件的GAN类,以增加训练集的大小,使其适合识别目标。实验结果表明,我们提出的框架可以从模糊的样本中生成去模糊的干净样本,即使在道路标记数据集不受约束的情况下也能胜过其他方法。 |
| Practical License Plate Recognition in Unconstrained Surveillance Systems with Adversarial Super-Resolution Authors Younkwan Lee, Jiwon Jun, Yoojin Hong, Moongu Jeon 尽管当前大多数车牌LP识别应用程序已经取得了显着进步,但它们仍然限于理想环境,在理想环境中,训练数据必须在受限的场景下进行仔细注释。在本文中,我们提出了一种新颖的车牌识别方法来处理不受约束的现实世界中的交通场景。为了克服这些困难,我们使用对抗性超分辨率SR以及一级字符分割和识别。结合基于VGG网络的深度卷积网络,我们的方法提供了简单但合理的训练过程。此外,我们介绍了GIST LP,这是一个具有挑战性的LP数据集,其中可以从不受约束的监视场景中有效地收集图像样本。在AOLP和GIST LP数据集上的实验结果表明,我们的方法在没有任何特定场景适应的情况下,在准确性方面优于当前的LP识别方法,并且在SR结果中提供了视觉增强,比原始数据更易于理解。 |
| Deep localization of protein structures in fluorescence microscopy images Authors Muhammad Tahir, Saeed Anwar, Ajmal Mian 由于类间的相似性和类内的不一致性,在解决多类分类问题时引起了严重的关注,从荧光显微镜图像中准确定位蛋白质是一项具有挑战性的任务。传统的基于机器学习的图像预测在很大程度上依赖于诸如归一化和分段之类的预处理,然后在进行分类之前先进行手工特征提取,以识别有用的和有用的以及特定于应用的特征。我们提出了一种端到端的蛋白质定位卷积神经网络PLCNN进行分类蛋白质定位图像更加准确可靠。 PLCNN直接处理原始图像,而无需任何预处理步骤,并且无需为特定数据集进行任何自定义或参数调整即可生成输出。我们方法的输出是根据网络产生的概率计算的。对五个公开可用的基准数据集进行了实验分析。 PLCNN在机器学习和深度架构方面始终优于现有的最新方法。 |
| Non-contact Infant Sleep Apnea Detection Authors Gihan Jayatilaka, Harshana Weligampola, Suren Sritharan, Pankayraj Pathmanathan, Roshan Ragel, Isuru Nawinne 睡眠呼吸暂停是一种呼吸障碍,人们反复在睡眠中停止呼吸。早期发现对婴儿至关重要,因为它可能带来长期的逆境。现有的精确检测机制脉搏血氧饱和度是皮肤接触测量。现有的非接触机制的声学,视频处理还不够准确。本文提出了一种视频处理检测睡眠呼吸暂停的新算法。该解决方案非接触式,准确且轻巧,足以在单板计算机上运行。本文讨论了该算法在实际数据上的准确性,新算法的优点,其局限性并提出了未来的改进方案。 |
| GLADAS: Gesture Learning for Advanced Driver Assistance Systems Authors Ethan Shaotran, Jonathan J. Cruz, Vijay Janapa Reddi 随着自动驾驶汽车的普及,人机交互HCI对于生命安全至关重要。然而,在确保AV理解道路上的人类方面所做的努力很少。在本文中,我们介绍GLADAS,这是一个基于模拟器的研究平台,旨在教AV理解行人手势。 GLADAS支持基于深度学习的自动驾驶汽车手势识别系统的培训,测试和验证。我们将重点放在手势上,因为手势是原始的(即与汽车互动的自然且常见的方式)。据我们所知,GLADAS是同类中的第一个系统,旨在为进一步研究人类AV交互提供基础设施。我们还使用GLADAS评估了自动驾驶汽车的手势识别算法,以评估其性能。我们的结果表明,AV可以理解人类手势的时间为85.91,从而增强了对人类AV交互进行进一步研究的需求。 |
| Machine Learning with Multi-Site Imaging Data: An Empirical Study on the Impact of Scanner Effects Authors Ben Glocker, Robert Robinson, Daniel C. Castro, Qi Dou, Ender Konukoglu 这是一项实证研究,旨在研究在多站点神经影像数据上使用机器学习时扫描仪效果的影响。我们利用从两项不同的研究(Cam CAN和UK Biobank)获得的结构性T1加权脑MRI。为了我们的调查目的,我们构建了一个数据集,该数据集由来自592个年龄和性别匹配的个体(每个原始研究的296个受试者)的脑部扫描组成。我们的结果表明,即使在使用先进的神经影像流水线进行仔细的预处理之后,分类器仍可以非常高精度地轻松地区分数据的来源。我们对性别分类示例应用的分析表明,当前的数据统一方法无法消除扫描仪特定的偏见,从而导致过分乐观的性能估计和较差的概括性。我们得出的结论是,多站点数据协调仍然是一个开放的挑战,在将此类数据与高级机器学习方法一起用于预测建模时,需要格外小心。 |
| Image Super-Resolution via Attention based Back Projection Networks Authors Zhi Song Liu, Li Wen Wang, Chu Tak Li, Wan Chi Siu, Yui Lam Chan 基于深度学习的图像Super Resolution SR由于其大数据消化能力而显示出快速发展。通常,更深更广的网络可以提取更丰富的特征图,并生成质量卓越的SR图像。但是,我们拥有的网络越复杂,实际应用所需的时间就越多。拥有简化的网络以实现高效的图像SR至关重要。在本文中,我们提出了一种基于注意力的反投影网络ABPN用于图像超分辨率。与最近的一些工作类似,我们认为可以进一步开发用于SR的反投影机制。建议使用增强型背投影块来迭代更新低分辨率和高分辨率特征残差。受近期注意力模型研究的启发,我们提出了一种空间注意力块SAB,以学习不同层上要素之间的互相关。基于这样的假设:降采样后,良好的SR图像应接近原始LR图像。我们提出了一种精细的反投影块RBPB,用于最终重建。在一些公共和AIM2019图像超分辨率挑战数据集上的大量实验表明,所提出的ABPN可以在定量和定性测量方面提供最先进的技术甚至更好的性能。 |
| Multi-Stage Pathological Image Classification using Semantic Segmentation Authors Shusuke Takahama, Yusuke Kurose, Yusuke Mukuta, Hiroyuki Abe, Masashi Fukayama, Akihiko Yoshizawa, Masanobu Kitagawa, Tatsuya Harada 组织病理学图像分析是发现疾病如癌症的重要过程。但是,考虑到可用的存储容量,在千兆像素分辨率的整个幻灯片图像WSI上训练CNN是一项挑战。大多数以前的工作将高分辨率WSI分成小图像块,并将它们分别输入到模型中以将其分类为肿瘤或正常组织。但是,基于补丁的分类仅使用补丁规模的本地信息,而忽略相邻补丁之间的关系。如果考虑相邻面片与全局特征的关系,则可以提高分类性能。为了提高自动病理诊断的预测性能,本文提出了一种基于补丁的分类模型和载玻片分割模型相结合的新模型结构。我们从分类模型中提取补丁特征,并将其输入到分割模型中,以获得完整的载玻片肿瘤概率热图。分类模型考虑补丁规模局部特征,而分割模型可以考虑全局信息。我们还提出了一种新的优化方法,该方法可以保留梯度信息并为有限的GPU内存容量的端到端学习部分训练模型。我们将我们的方法应用于WSIs的肿瘤正常预测,并且与传统的基于补丁的方法相比,分类性能得到了改善。 |
| Breathing deformation model -- application to multi-resolution abdominal MRI Authors Chompunuch Sarasaen, Soumick Chatterjee, Mario Breitkopf, Domenico Iuso, Georg Rose, Oliver Speck 动态MRI是一种连续获取一系列图像以跟踪生理随时间变化的技术。然而,这种快速成像导致低分辨率图像。在这项工作中,将从动态低分辨率图像计算出的腹部变形模型应用于先前获取的高分辨率图像,以生成动态高分辨率MRI。动态低分辨率图像模拟到吸气和呼气的不同呼吸阶段。然后,使用B样条SyN变形模型并使用互相关作为相似性度量标准,进行呼吸时间点之间的图像配准。根据高度欠采样的数据估算了不同呼吸阶段之间的变形模型。然后将此变形模型应用于高分辨率图像,以获得不同呼吸阶段的高分辨率图像。结果表明,可以从相对较低分辨率的图像中计算变形模型。 |
| BitNet: Learning-Based Bit-Depth Expansion Authors Junyoung Byun, Kyujin Shim, Changick Kim 位深度是图像中像素的每个颜色通道的位数。尽管许多现代显示器都支持前所未有的更高位深度,以显示具有更高动态范围的更逼真的自然色彩,但大多数媒体源的位深度仍为8或更低。由于位深度不足会产生令人讨厌的错误轮廓或失去详细的视觉外观,因此从低位深度LBD图像到高位深度HBD图像的位深度扩展BDE变得越来越重要。在本文中,我们采用了一种基于学习的BDE方法,并提出了一种基于CNN的新型位深扩展网络BitNet,该网络可以有效去除伪轮廓并同时恢复视觉细节。我们已经基于带有扩张卷积和新颖的多尺度特征集成的编码器-解码器体系结构精心设计了BitNet。我们已经使用MIT Adobe FiveK,Kodak,ESPL v2和TESTIMAGES等四个不同的数据集进行了各种实验,我们提出的BitNet在其他现有BDE方法以及基于CNN的著名图像处理等方面,在PSNR和SSIM方面均达到了最先进的性能。网络。与以前的方法分别处理每个颜色通道不同,我们可以一次处理所有RGB通道,并大大改善了颜色恢复。此外,我们的网络显示出近实时最快的计算速度。 |
| Visual Understanding of Multiple Attributes Learning Model of X-Ray Scattering Images Authors Xinyi Huang, Suphanut Jamonnak, Ye Zhao, Boyu Wang, Minh Hoai, Kevin Yager, Wei Xu 这个扩展的摘要提供了一个可视化系统,该系统设计用于领域科学家以视觉方式了解他们的深度学习模型,该模型在X射线散射图像中提取多个属性。该系统专注于研究与多个结构属性有关的模型行为。相对于领域科学家标记的实际属性,它允许用户浏览特征空间中的图像,不同属性的分类输出。丰富的交互功能使用户可以灵活地选择实例图像,它们的群集,并在视觉上进行细节比较。两项初步的案例研究证明了其功能和实用性。 |
| From Visual Place Recognition to Navigation: Learning Sample-Efficient Control Policies across Diverse Real World Environments Authors Marvin Chanc n, Michael Milford 现实环境中的视觉导航任务通常需要自我运动和位置识别反馈。尽管深度强化学习已经成功地以端到端的方式解决了这些感知和决策问题,但这些算法需要大量经验才能从高维输入中学习导航策略,由于样本的复杂性,这对于实际的机器人通常是不切实际的。在本文中,我们通过两个主要贡献解决了这些问题。我们首先将地点识别和深度学习技术与目标目的地反馈相结合,以生成紧凑的双峰图像表示,然后可以从少量经验中有效地学习公里级别的控制策略。其次,我们提出了一个名为CityLearn的交互式,现实的框架,该框架首次使在极端环境变化的情况下,可以在城市规模的真实环境中训练导航算法。 CityLearn拥有10多个基准现实世界数据集,这些数据集经常用于场所识别研究,遍历了100个遍历遍及全球60个城市。我们在两个CityLearn环境中评估我们的方法,在这些环境中,我们的导航策略是使用一次遍历进行训练的。结果表明,与使用原始图像相比,我们的方法可以快2个数量级以上,并且还可以推广到极端的视觉变化,包括从白天到夜晚以及从夏天到冬天的过渡。 |
| Agent with Warm Start and Active Termination for Plane Localization in 3D Ultrasound Authors Haoran Dou, Xin Yang, Jikuan Qian, Wufeng Xue, Hao Qin, Xu Wang, Lequan Yu, Shujun Wang, Yi Xiong, Pheng Ann Heng, Dong Ni 标准平面定位对于超声US诊断至关重要。在美国产前,使用2D探针手动获取数十个标准飞机。这是耗时的并且取决于操作员。相比之下,一次包含多个标准平面的3D US具有固有的优点,即减少了对用户的依赖性,并提高了效率。但是,由于巨大的搜索空间和较大的胎儿姿势变化,手动定位飞机在美国的体积中具有挑战性。在这项研究中,我们提出了一种新颖的强化学习RL框架,可以在3D US中自动定位胎脑标准平面。我们的贡献是双重的。首先,我们为RL框架配备了具有里程碑意义的对齐模块,以为代理行为提供热启动和强大的空间界限,从而确保其有效性。其次,代替主动和经验地终止代理推理,我们提出了一种基于递归神经网络的主动终止代理交互过程的策略。这提高了定位系统的准确性和效率。在我们的内部大型数据集中进行了广泛验证,我们的方法对于小脑和丘脑平面定位分别达到3.4mm 9.6和2.7mm 9.1的精度。我们提出的RL框架是通用的,具有提高美国扫描效率和标准化的潜力。 |
| Removing input features via a generative model to explain their attributions to classifier's decisions Authors Chirag Agarwal, Dan Schonfeld, Anh Nguyen 可解释性方法通常通过例如通过启发式地删除输入特征来测量输入特征对图像分类器的决策的贡献。模糊,增加噪声或变灰,通常会导致样本不真实。相反,我们建议将生成的Inpainter集成到三种代表性的归因方法中,以删除输入特征。与原始副本相比,我们的方法1在真实数据生成过程下生成了更合理的反事实样本2对超参数设置更健壮,并且3更精确地定位了对象。我们的发现在ImageNet和Places365数据集以及两对不同的分类器和修补程序上都是一致的。 |
| Image Quality Assessment for Rigid Motion Compensation Authors Alexander Preuhs, Michael Manhart, Philipp Roser, Bernhard Stimpel, Christopher Syben, Marios Psychogios, Markus Kowarschik, Andreas Maier 使用C型臂锥束计算机断层扫描CBCT诊断性卒中影像可减少血管内手术的治疗时间。但是,与螺旋CT相比,延长的采集时间增加了患者僵硬运动的可能性。刚性运动会破坏在重建过程中假定的几何对齐方式,从而导致图像模糊或出现伪影。为了重建几何形状,我们通过基于神经网络的自动聚焦方法来估计运动轨迹,该方法被训练为基于重构切片的图像信息来回归重投影误差。该网络接受了来自19位患者的CBCT扫描的培训,并使用了另一位测试患者进行了评估。与常用的基于熵的方法相比,它可以很好地适应看不见的运动幅度,并在运动估计基准中获得出色的结果。 |
| Chinese Abs From Machine Translation |


{kind=link}