1. paper Reading
A Neural Model for Generating Natural Language Summaries of Program Subroutines ICSE 2019
- Problem define:creat a sentence to decribing subroutines in a program.
Sub problem: how to represent source code - Big Background:source code summaries, NMT(Neural Machine Translation)
- Pros and cons of previous work:
3.1. JavaDoc 等Tools需要按照一定的format写注释,生成HTML形式的documentation.本质是programmar在写summary.
3.2. 基于content selection 和 sentence templates,需要人们去设计规则,效果好坏取决与人的设计。
3.3. 受NMT启发,source code to summary 也是seq2seq,不同的是code token的命名对code behavior不会有太大的影响,代码的语义通常是和structure 和 control flow和data flow有关,在采用相似seq2seq model。codenn,SBT(Structure-based traversal), 本文的FunCom 以及 ICLR2019的不同主要在code 不同表示上。 - Improved point(s):
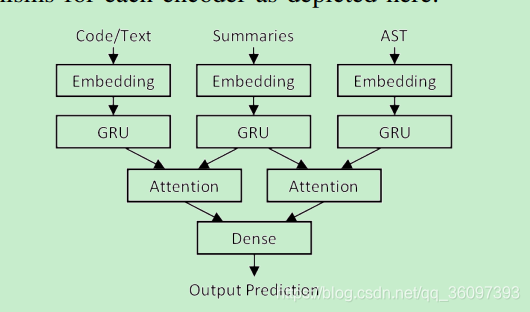
4.1 在code 和其相应的 AST都可以获取的时候,采用code stream 和按AST两种输入.
4.2 就是在"no code words"的情况下,利用AST做code summaries。 - Our methods:
输入为code stream和AST两部分,采用带有attention机制的seq2seq model. Attention的计算有codenn,和SBT(稍有不同。
2. terms的理解
internal documentation, code documentation,
- documentation
paper中提到internal documentation对于code summary的有影响。我首先查了下document和documentation的区别,
Documentation is a set of documents provided on paper. It has more denotations than "document". wiki
Documentation is also the activity of creating documents.link - internal documentation
paper里指的是meaningful variable name;
按wike上说的,这个值得是meaningful variable name 和 useful comments - code documentation 和 code summary 这两个领域?
对code生成相应documentation是code documentation;
对code生成相应自然语言描述是 code summary ;
这么说来 。code summary 算在code documentation里? 我在读paper的时候一直这么认为不知道对不对
3. 基于NMT的code summary的一些paper
这四篇文章都是用NLP中的seq2seq model来解决code summary的问题,不同之处在于对代码的表示。
- codenn用token stream, one-hot进行编码,meaningful的variable name和key wors if,for, while表示调用的 dot .可以体现代码的结构
- SBT 用的AST结合了代码的structure,
- 本文的FunCo的input结合前面的两者展成seq的AST和token stream
code2seq的input是将AST展成 a set of path
3.1 codenn
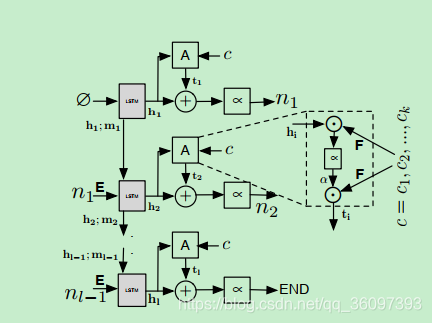
input c=c1c2c3...是token stream
output n= n1n2... End是a sentence
3.2 SBT
它的遍历AST的方式,其实就是把AST的tree格式用类似于XML格式的sequence表示。
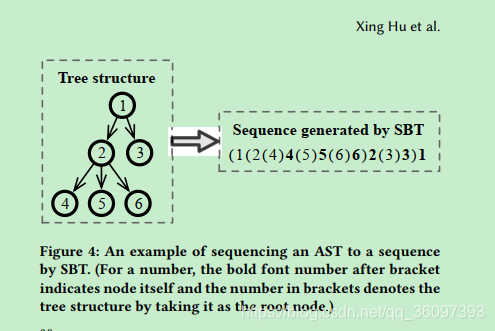
model
3.3 本文的FunCom
3.4 code2seq
input,a set of AST path,
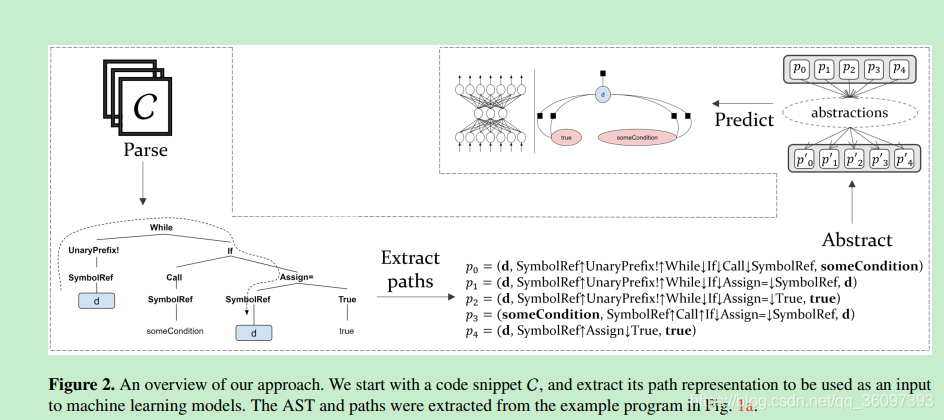
AST path是个三元组<起点,路径,终点>
path是从一个non-terminal / terminal 到另一个 non-terminal / terminal 的path,paper认为每条path可以express一些fact。
下图p1 express !d 是while循坏的终止条件
p4,express 将d的值改为true,结合p1, d = true后,while循环终止。
4. Question
- FunCom中对于AST和Code中相同的变量名进行embedding后的vector不是同一个?
ans: 一个是两者的embedding空间不一样,另一个他将原来code中的变量的名字name改成了type_name - 实验过程中的attengru(输入不含有AST)和ast-attentiongru(输入中既有code也有txt)的在统计意义上效果大致相同,但是对于个例,各有所长,这一点的原因是什么论文没有做解释。但这个现象表明有些AST对于Code summary有时有作用,又是作用不是很大,有时甚至有副作用。
- 对于AST或许用recursive NN得到vector作为输入中 code/Text那部分的initial state是否有一定合理性。
- AST将叶子节点去掉按SBT提的方法序列化,将其用GRU得到的output作为code/Text那部分initial state
ans:我之前又提到理解一个项目的代码,是想看框架,函数之间的调用,后关注细节。 将AST的信息非叶子用起来便是先关注整体,后来关注所有的代码. 这样做AST这部分首先不存在OOV,能从这里获取主要信息,code中的OOV去问题对结果的影响便不是很大。
5. Next plan
- 将上述4篇文章的model在一个数据集合上进行跑分得到结果。
- 现在可以跑通代码,了解代码的输入,输出,以及和模型相关的那部分的框架,具体的细节不太清楚,接下来我希望搞清楚,代码执行时生成文件的数据怎么得到,可以达到修改模型的地步。
- 编译原理语法分析和抽象语法树部分,接下来两周可以完成。
机器学习:学校课程+西瓜书+李航的统计机器学习 两个月可以过第一遍,
课表
周一周三周天全天没课,周二周四下午可以讨论。