点击@计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
1.【基础网络架构:Transformer】Split & Merge: Unlocking the Potential of Visual Adapters via Sparse Training

2.【基础网络架构:Transformer】(NeurIPS2023)Are Vision Transformers More Data Hungry Than Newborn Visual Systems?

3.【基础网络架构:Transformer】Class-Discriminative Attention Maps for Vision Transformers

4.【语义分割】SAM-Assisted Remote Sensing Imagery Semantic Segmentation with Object and Boundary Constraints

5.【点云3D目标检测】Diffusion-SS3D: Diffusion Model for Semi-supervised 3D Object Detection

6.【多模态】GPT4Point: A Unified Framework for Point-Language Understanding and Generation
-
工程主页:GPT4Point
-
代码即将开源

7.【多模态】BenchLMM: Benchmarking Cross-style Visual Capability of Large Multimodal Models

8.【多模态】Machine Vision Therapy: Multimodal Large Language Models Can Enhance Visual Robustness via Denoising In-Context Learning

9.【多模态】Lenna: Language Enhanced Reasoning Detection Assistant

10.【多模态】CLIPDrawX: Primitive-based Explanations for Text Guided Sketch Synthesis

11.【多模态】A Contrastive Compositional Benchmark for Text-to-Image Synthesis: A Study with Unified Text-to-Image Fidelity Metrics

12.【多模态】PixelLM: Pixel Reasoning with Large Multimodal Model
-
开源代码(即将开源):https://github.com/MaverickRen/PixelLM

13.【多模态】Behind the Magic, MERLIM: Multi-modal Evaluation Benchmark for Large Image-Language Models
-
开源代码(即将开源):https://github.com/ojedaf/MERLIM

14.【数字人】FlashAvatar: High-Fidelity Digital Avatar Rendering at 300FPS
-
工程主页:FlashAvatar
-
代码即将开源

15.【自监督学习】Local Masking Meets Progressive Freezing: Crafting Efficient Vision Transformers for Self-Supervised Learning

16.【数据增强】GeNIe: Generative Hard Negative Images Through Diffusion
-
开源代码(即将开源):https://github.com/UCDvision/GeNIe

17.【深度估计】PatchFusion: An End-to-End Tile-Based Framework for High-Resolution Monocular Metric Depth Estimation

18.【自动驾驶】WoVoGen: World Volume-aware Diffusion for Controllable Multi-camera Driving Scene Generation

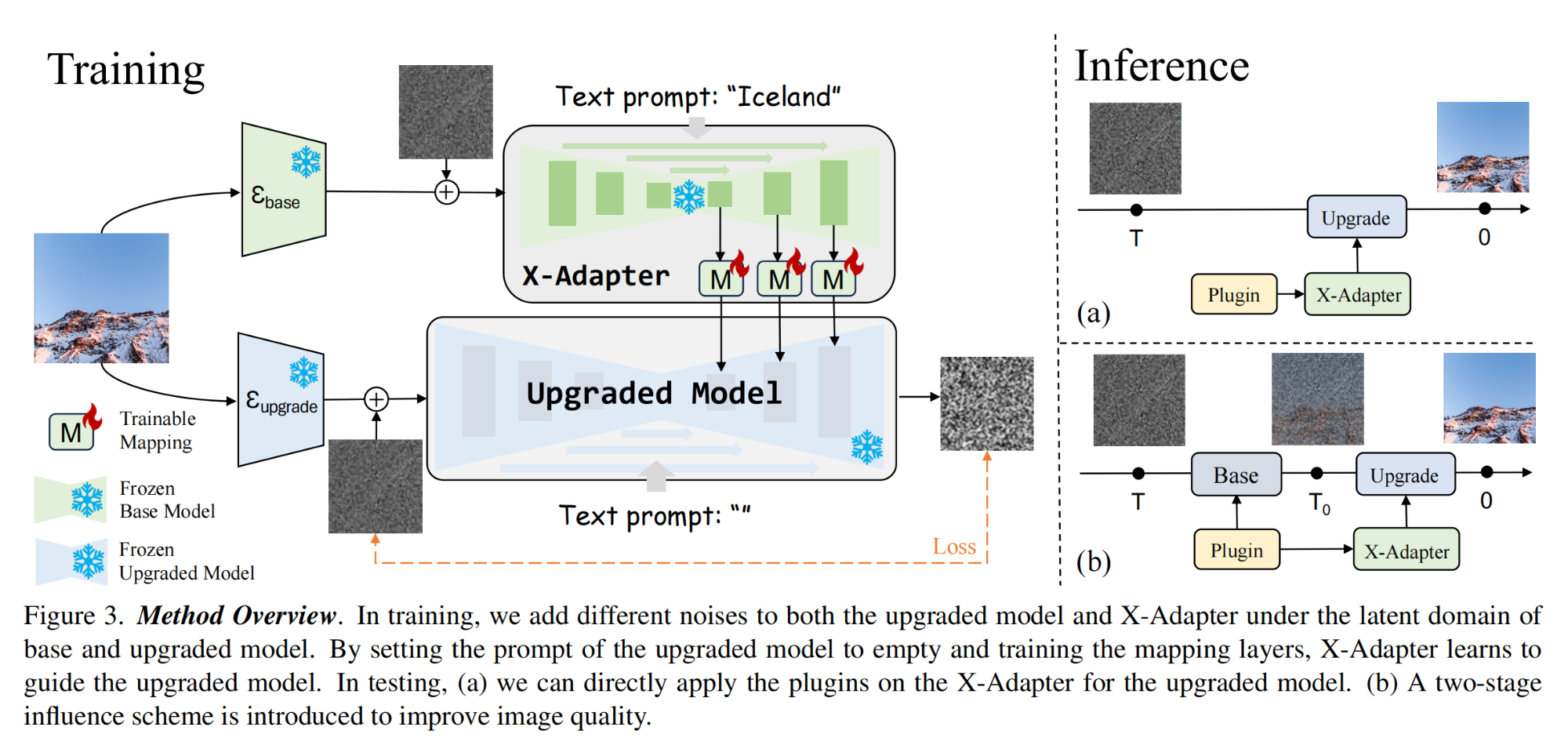
19.【Diffusion】X-Adapter: Adding Universal Compatibility of Plugins for Upgraded Diffusion Model
-
工程主页:X-Adapter
-
开源代码(即将开源):https://github.com/showlab/X-Adapter
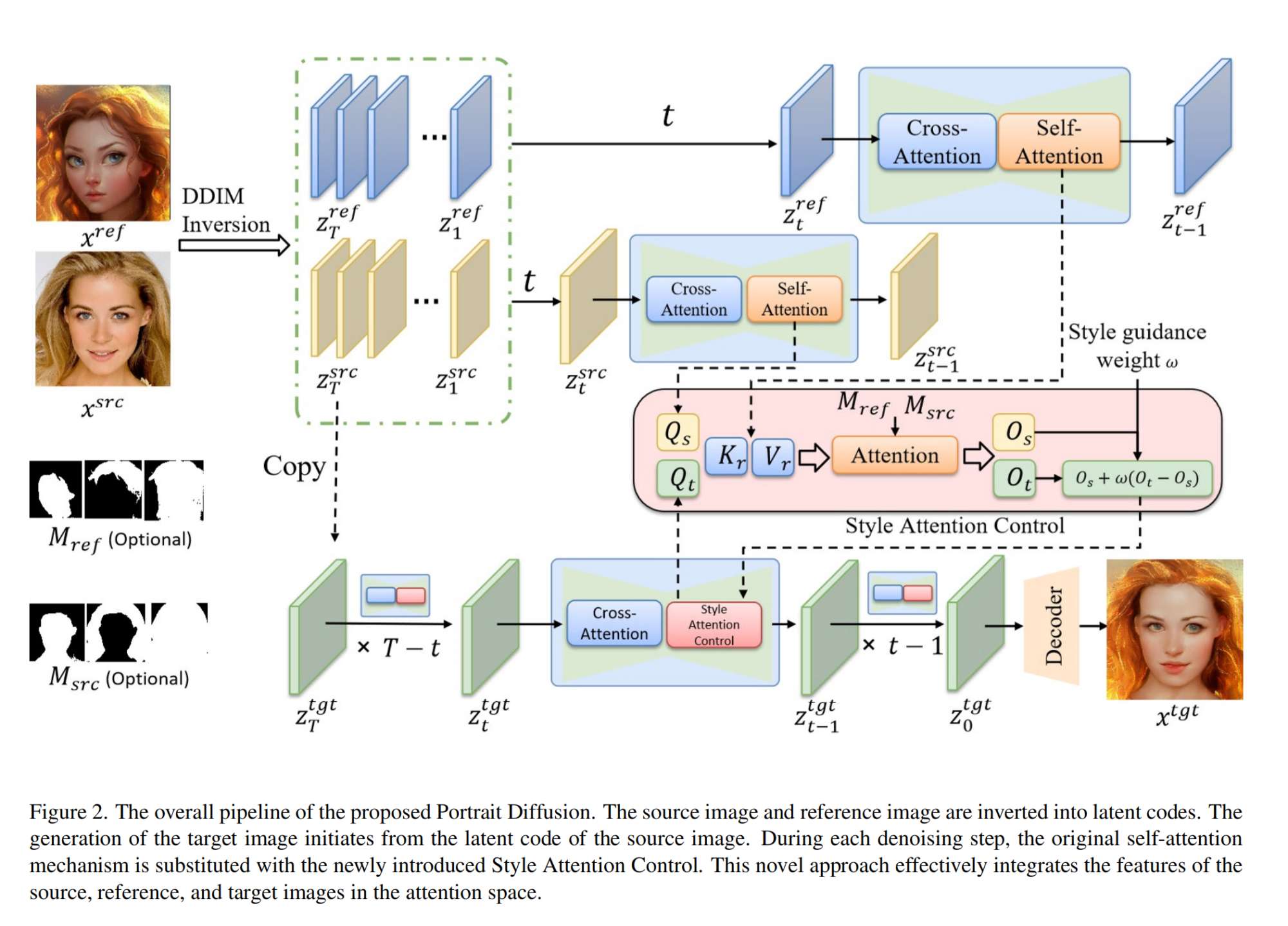
20.【Diffusion】Portrait Diffusion: Training-free Face Stylization with Chain-of-Painting
21.【视频编辑】Drag-A-Video: Non-rigid Video Editing with Point-based Interaction
-
工程主页:Drag-A-Video
-
代码即将开源

22.【视频编辑】SAVE: Protagonist Diversification with Structure Agnostic Video Editing
-
工程主页:SAVE: Protagonist Diversification with Structure Agnostic Video Editing
-
开源代码(即将开源):https://github.com/ldynx/SAVE

23.【视频编辑】DragVideo: Interactive Drag-style Video Editing

24.【人体运动生成】Generating Fine-Grained Human Motions Using ChatGPT-Refined Descriptions

25.【人体运动生成】EMDM: Efficient Motion Diffusion Model for Fast, High-Quality Motion Generation

26.【NeRF】PointNeRF++: A multi-scale, point-based Neural Radiance Field

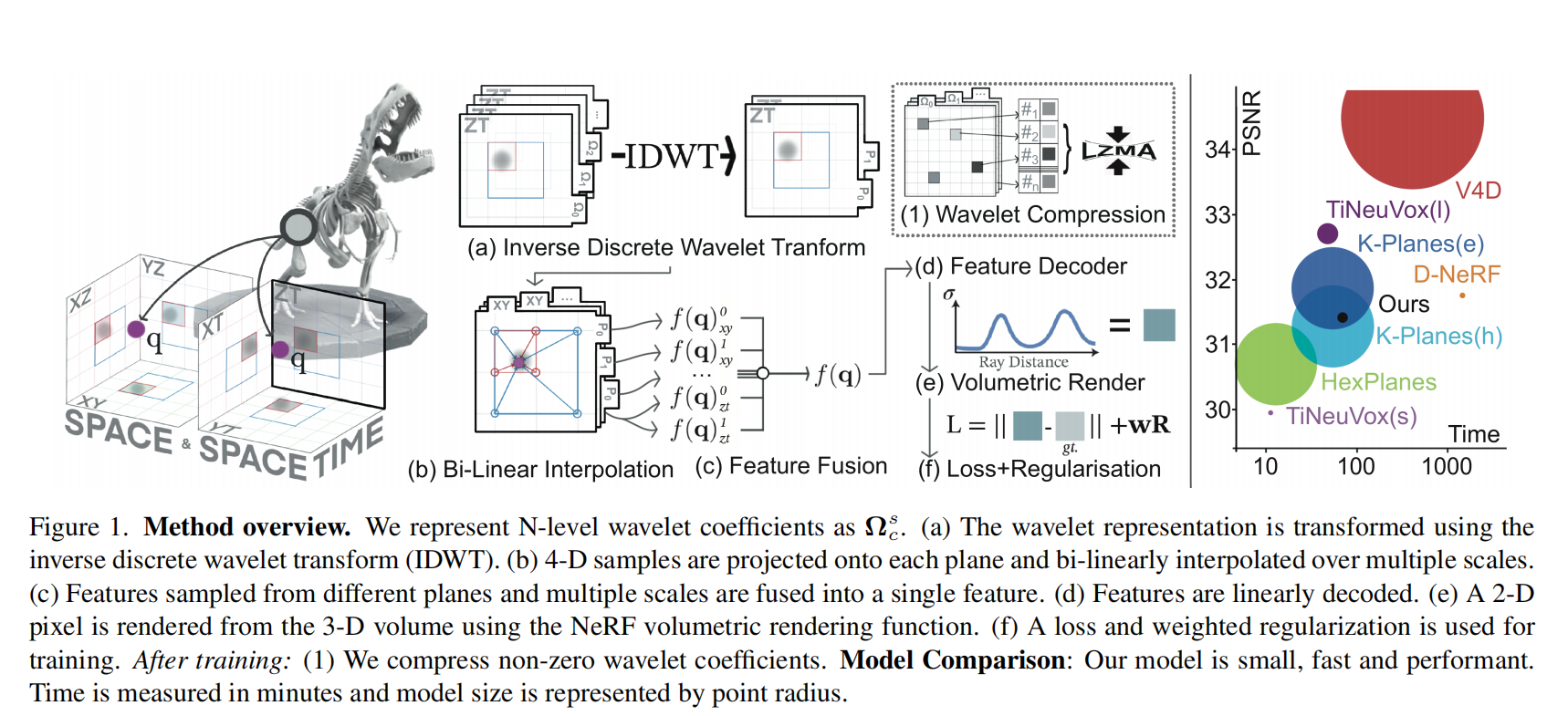
27.【NeRF】WavePlanes: A compact Wavelet representation for Dynamic Neural Radiance Fields
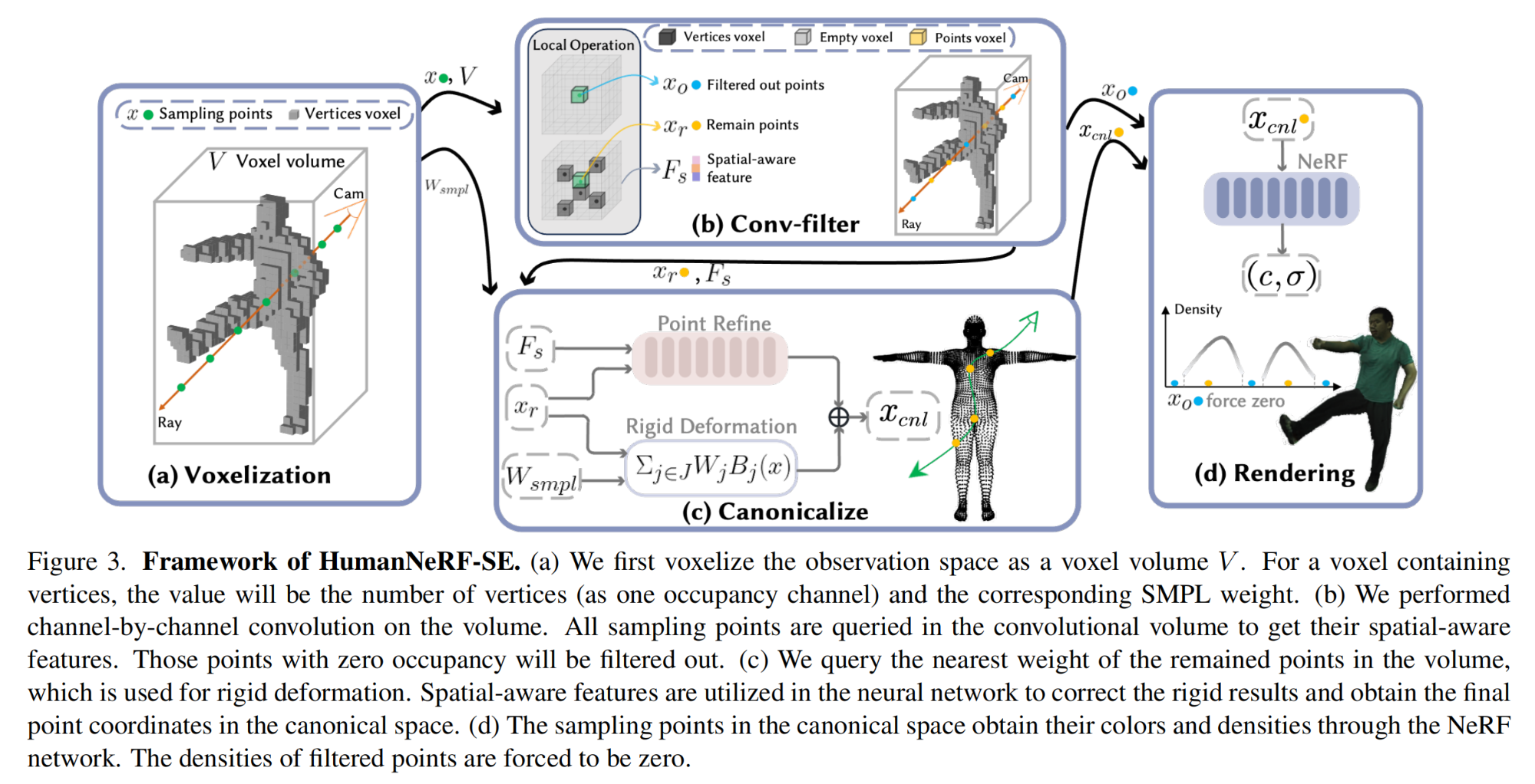
28.【人体重建】HumanNeRF-SE: A Simple yet Effective Approach to Animate HumanNeRF with Diverse Poses
-
工程主页:HumanNeRF-SE
-
开源代码(即将开源):https://github.com/Miles629/HumanNeRF-SE
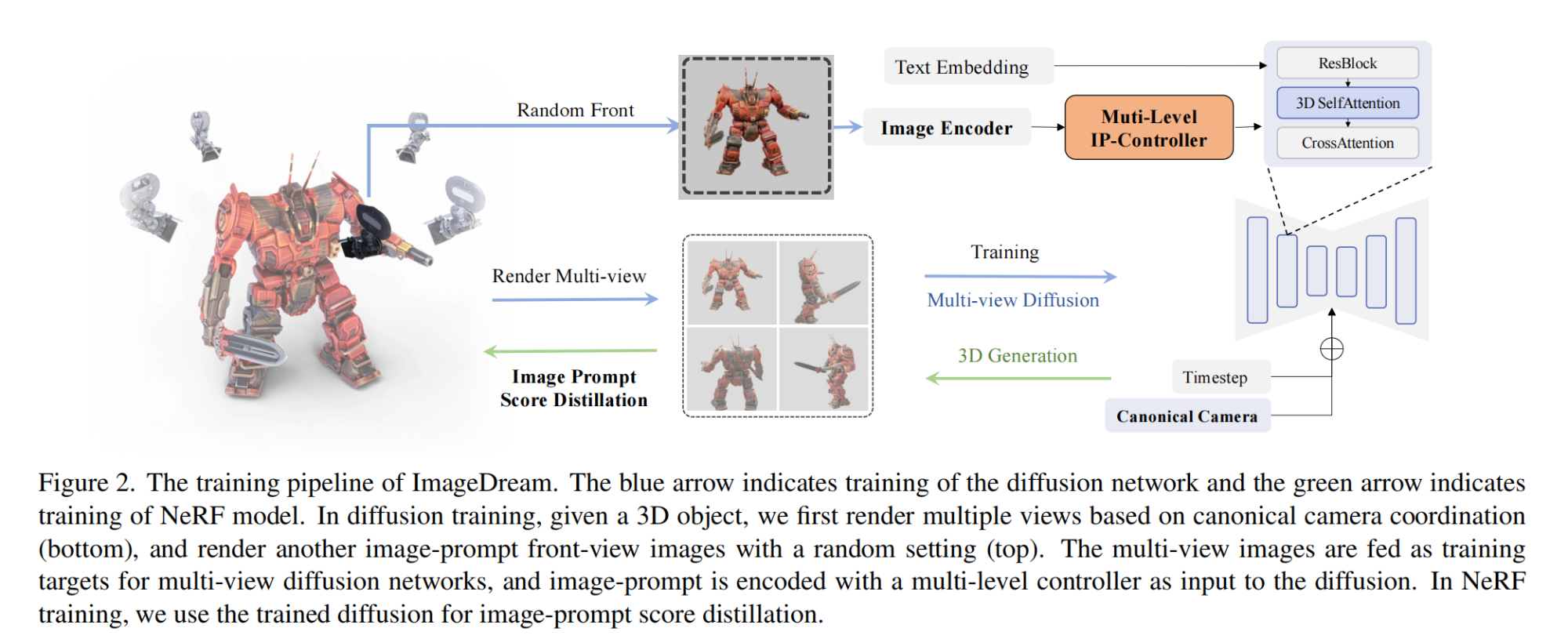
29.【三维重建】ImageDream: Image-Prompt Multi-view Diffusion for 3D Generation
论文已打包,下载链接
CV计算机视觉交流群
群内包含目标检测、图像分割、目标跟踪、Transformer、多模态、NeRF、GAN、缺陷检测、显著目标检测、关键点检测、超分辨率重建、SLAM、人脸、OCR、生物医学图像、三维重建、姿态估计、自动驾驶感知、深度估计、视频理解、行为识别、图像去雾、图像去雨、图像修复、图像检索、车道线检测、点云目标检测、点云分割、图像压缩、运动预测、神经网络量化、网络部署等多个领域的大佬,不定期分享技术知识、面试技巧和内推招聘信息。
想进群的同学请添加微信号联系管理员:PingShanHai666。添加好友时请备注:学校/公司+研究方向+昵称。
推荐阅读:
CV计算机视觉每日开源代码Paper with code速览-2023.12.6
CV计算机视觉每日开源代码Paper with code速览-2023.12.5