AI视野·今日CS.CV 计算机视觉论文速览
Thu, 26 Sep 2019
Totally 37 papers
?上期速览✈更多精彩请移步主页

Interesting:
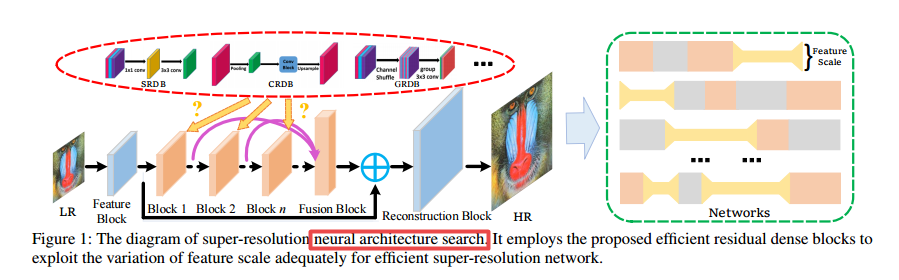
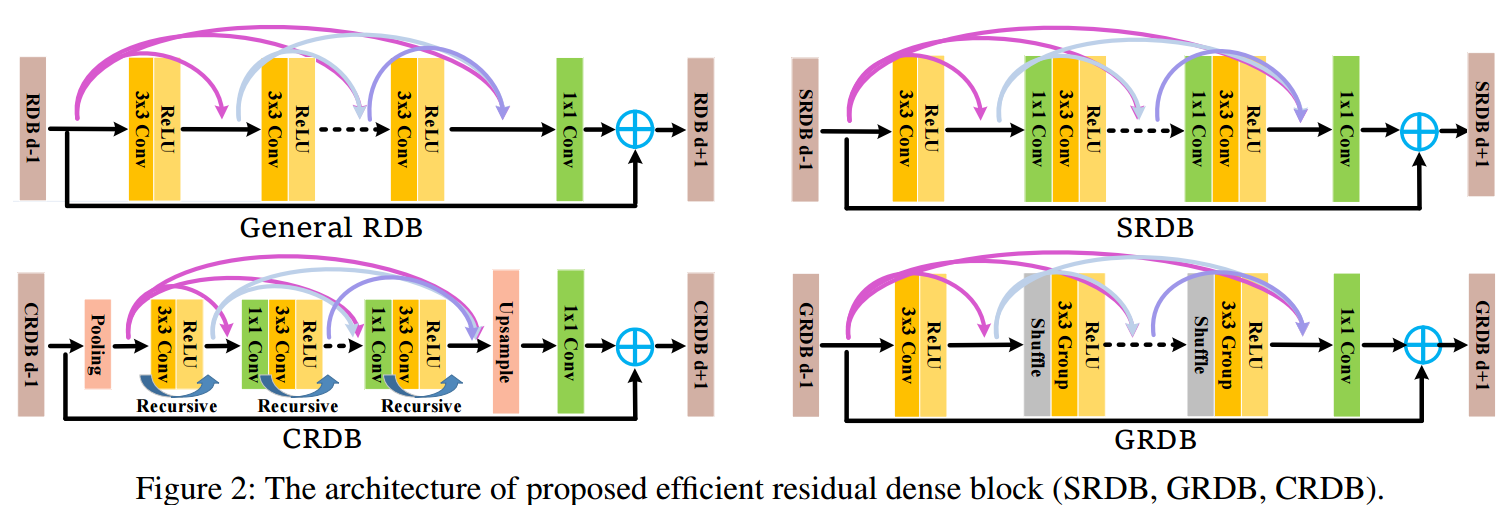
?高效地残差稠密搜索用于图像超分辨, (from 华为诺亚 悉尼大学)

?***为深度学习合成数据, (from Steklov Institute of Mathematics Synthesis.ai )






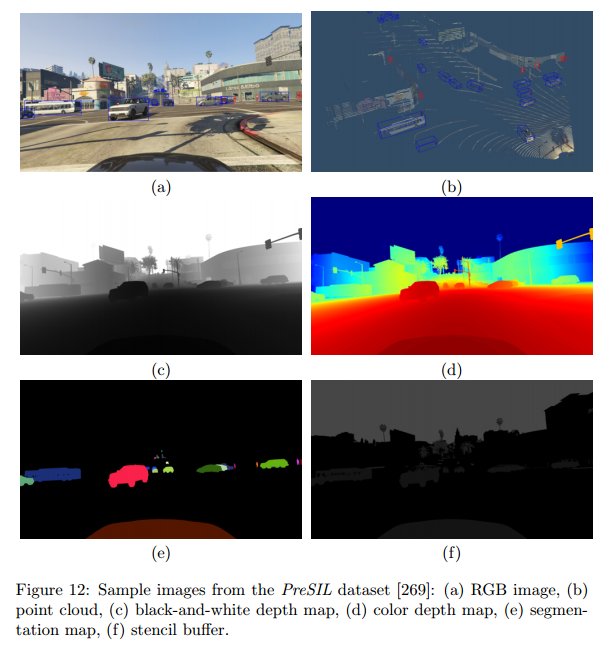


TODO(RJJ):基于这个写一个合成数据集的总结帖子
?单图像单元实现视觉感知任务, (from 北理工)
?X射线安检, (from Durham University)
dataset:GDXray SIXray
?DeepFakes的构建和检测方法, (from Deakin University, Victoria, Australia )
Daily Computer Vision Papers
| Deep Predictive Motion Tracking in Magnetic Resonance Imaging: Application to Fetal Imaging Authors Ayush Singh, Seyed Sadegh Mohseni Salehi, Ali Gholipour 胎儿磁共振成像MRI受到无法控制的,大的和不规则的胎儿运动的挑战。胎儿MRI以完全互动的方式执行,其中技术人员监视运动以相对于感兴趣的解剖结构以直角指定切片。当前的实践涉及重复获取以确保获取诊断质量的图像,并逐层地回顾性地记录扫描以重建3D图像。但是,基于显示的2D切片进行手动3D胎儿监视以及在切片(而不是切片)堆栈级别进行导航是次佳且效率低下的。当前的过程高度依赖于操作员,需要进行广泛的培训,并且显着增加了胎儿MRI扫描的时间,这使孕妇难以进行扫描,而且费用昂贵。出于这一动机,我们提出了一种使用深度学习的MRI中基于实时图像的新运动跟踪技术,该技术可以显着改善现有技术。通过将空间和时间编码器解码器网络相结合,我们的系统将学习如何基于直接从获取的切片序列中推断出的运动动态来预测胎儿头部的3D姿势。与最近的从片段中估计对象的静态3D姿势的作品相比,我们的方法学会了预测3D运动的动态。我们在保留的测试集中比较了我们训练有素的网络,其中包括具有不同特征的数据,例如不同的年龄范围,并使用旨在估计的网络以及采用的预测方法从志愿者受试者记录的运动轨迹。所有估计和预测任务的结果表明,我们在胎儿MRI中实现了可靠的运动跟踪。可以使用基于深度学习的快速解剖结构检测,分割和图像配准技术来增强此技术,以构建实时运动跟踪和导航系统。 |
| A closer look at domain shift for deep learning in histopathology Authors Karin Stacke, Gabriel Eilertsen, Jonas Unger, Claes Lundstr m 域移位是组织病理学中的重要问题。在医疗中心和扫描仪之间,整个幻灯片图像的数据特性可能会有很大差异,这使得很难将深度学习推广到看不见的数据。为了更好地理解该问题,我们提出了一项针对卷积神经网络的研究,该卷积神经网络针对H E染色的整个幻灯片图像的肿瘤分类进行了训练。我们分析了增强和规范化策略如何影响性能和学习的表示形式,以及经过训练的模型对功能的响应。最重要的是,我们提出了一种新方法,用于在学习到的特定模型表示的背景下评估域之间的距离。该度量可以揭示模型对域变化的敏感程度,并且可以用于检测模型将普遍存在问题的新数据。结果表明,训练数据的准备如何对学习产生重大影响,并且用于分类的潜在表示对数据分布的变化非常敏感,尤其是在没有扩充或归一化训练的情况下。 |
| MIC: Mining Interclass Characteristics for Improved Metric Learning Authors Karsten Roth, Biagio Brattoli, Bj rn Ommer 度量学习试图嵌入对象的图像,以使嵌入空间捕获类定义的关系。但是,图像的可变性不仅是由于所描绘的对象类别不同,而且还取决于其他潜在特征,例如视点或照明。除了这些结构化特性之外,随机噪声还阻碍了所关注的视觉关系。度量学习的常用方法是强制执行在所有因素(感兴趣的因素除外)下不变的表示。相反,我们建议显式学习对象类共享的潜在特征。然后,我们可以直接解释结构化的视觉可变性,而不用假定它是未知的随机噪声。我们提出了一种新颖的替代任务,以使用单独的编码器学习跨类共享的视觉特征。通过减少编码器的相互信息,可以与编码器一起针对类信息进行训练。在五个标准的图像检索基准上,该方法大大改进了现有技术。 |
| Deep Learning for Deepfakes Creation and Detection Authors Thanh Thi Nguyen, Cuong M. Nguyen, Dung Tien Nguyen, Duc Thanh Nguyen, Saeid Nahavandi 深度学习已成功应用于解决各种复杂问题,从大数据分析到计算机视觉和人的水平控制。然而,深度学习的进步也已被用于创建可以对隐私,民主和国家安全造成威胁的软件。 Deepfake是最近出现的那些由深度学习驱动的应用程序之一。 Deepfake算法可以创建伪造的图像和视频,人类无法将它们与真实图像区分开。因此,必须提出一种能够自动检测和评估数字视觉媒体完整性的技术。本文介绍了用于创建深造假的算法的调查,更重要的是,迄今为止,文献中提出了检测深造假的方法。我们对与Deepfake技术相关的挑战,研究趋势和方向进行了广泛的讨论。通过回顾深层仿冒的背景和最新的深层仿冒检测方法,本研究提供了深层仿冒技术的全面概述,并有助于开发新的,更强大的方法来应对日益严峻的深层仿冒。 |
| Dual Adaptive Pyramid Network for Cross-Stain Histopathology Image Segmentation Authors Xianxu Hou, Jingxin Liu, Bolei Xu, Bozhi Liu, Xin Chen, Mohammad Ilyas, Ian Ellis, Jon Garibaldi, Guoping Qiu 监督语义分割通常假定测试数据与训练数据位于相似的数据域中。但是,实际上,训练和看不见的数据之间的域不匹配可能会导致性能显着下降。为不同域中的图像获得准确的逐像素标签是繁琐且费力的,尤其是对于组织病理学图像。在本文中,我们提出了一种用于组织病理学腺体分割的双重自适应金字塔网络DAPNet,它可以从一个染色域转移到另一个染色域。我们在两个级别上解决域适应问题:1图像级别考虑了图像颜色和样式的差异; 2特征级别解决了两个域之间的空间不一致问题。这两个组件通过对抗训练作为领域分类器实现。我们使用分别具有H E和DAB H染色的两个腺体分割数据集来评估我们的新方法。广泛的实验和消融研究证明了我们的方法对领域自适应分割任务的有效性。我们表明,所提出的方法与其他现有技术方法相比具有良好的性能。 |
| Gated Channel Transformation for Visual Recognition Authors Zongxin Yang, Linchao Zhu, Yu Wu, Yi Yang 在这项工作中,我们提出了一种适用于深度卷积神经网络的视觉识别通用转换单元。该转换显式地使用可解释的控制变量对通道关系进行建模。这些变量确定竞争或合作的神经元行为,并通过卷积权重对其进行优化,以实现更准确的识别。在Squeeze和Excitation SE网络中,通道关系是由完全连接的层隐式学习的,并且SE块在块级别集成。相反,我们引入了通道归一化层以减少参数数量和计算复杂度。这个轻量级的层合并了一个简单的L2归一化,使我们的转换单元适用于操作员级别,而无需过多增加其他参数。广泛的实验证明了我们装置的有效性,在许多视觉任务上都有明显的余量,即ImageNet上的图像分类,COCO上的对象检测和实例分割,Kinetics上的视频分类。 |
| The Good, the Bad and the Ugly: Evaluating Convolutional Neural Networks for Prohibited Item Detection Using Real and Synthetically Composited X-ray Imagery Authors Neelanjan Bhowmik, Qian Wang, Yona Falinie A. Gaus, Marcin Szarek, Toby P. Breckon 检测X射线安全图像中的违禁物品对于维护边界和运输安全以应对各种威胁情况至关重要。卷积神经网络CNN在大量数据的支持下,在这种自动禁止对象检测和分类方面取得了进步。但是,整理如此大量的X射线安全图像仍然是一个巨大的挑战。这项工作开辟了使用合成图像的可能性,而无需整理如此大量的带有手注释的真实世界图像。在这里,我们调查了使用实际和合成X射线训练图像对CNN架构检测杂乱而复杂的X射线安全行李图像中的三个示例性违禁物品(枪支,枪械零件,刀具)所实现的检测性能的差异。对于使用真实X射线图像进行的这3类目标检测,我们使用Faster R CNN和ResNet 101 CNN架构实现了0.88的平均平均精度mAP。虽然其性能可与0.78 mAP的合成X射线图像相媲美,但我们的扩展评估证明了使用合成图像来使X射线安全训练图像多样化以进行自动检测算法训练的挑战和希望。 |
| mustGAN: Multi-Stream Generative Adversarial Networks for MR Image Synthesis Authors Mahmut Yurt, Salman Ul Hassan Dar, Aykut Erdem, Erkut Erdem, Tolga ukur 多对比度MRI协议提高了可用于诊断的形态学信息的水平。然而,实际上,造影剂的数量和质量受到包括扫描时间和患者运动的各种因素的限制。合成缺失或损坏的对比度可以减轻这种局限性,从而提高临床实用性。多对比度MRI的常用方法涉及一对一和多对一的合成方法。一对一方法将单个源的对比度作为输入,并且他们学习了对源的独特功能敏感的潜在表示。同时,多对一方法会收到多个不同的来源,并且他们会学习一种共享的潜在表示形式,这些表示形式对各个来源之间的共同特征更为敏感。对于增强的图像合成,我们提出一种多流方法,该方法通过将多个一对一流和联合多对一流混合在一起,跨多个源图像聚合信息。在多对一流中生成的共享特征图和在一对一流中生成的互补特征图与融合块组合。融合块的位置被自适应地修改以最大化任务特定的性能。对T1,T2,PD加权图像和FLAIR图像的定性和定量评估清楚地证明了与以前的现有技术一对一和多对一方法相比,该方法的优越性能。 |
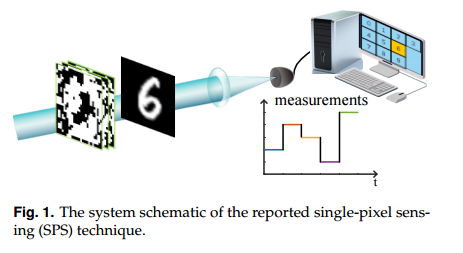
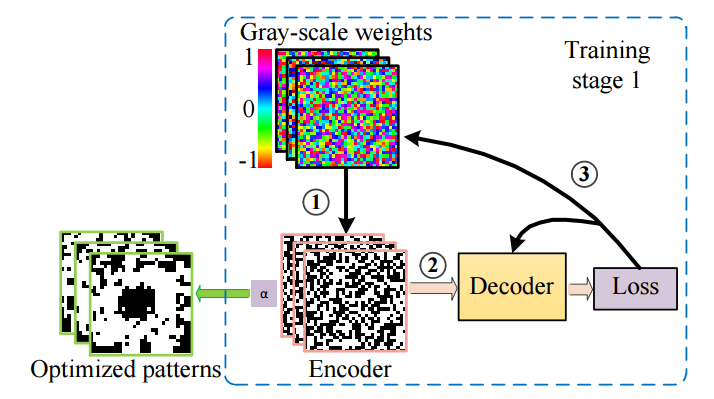
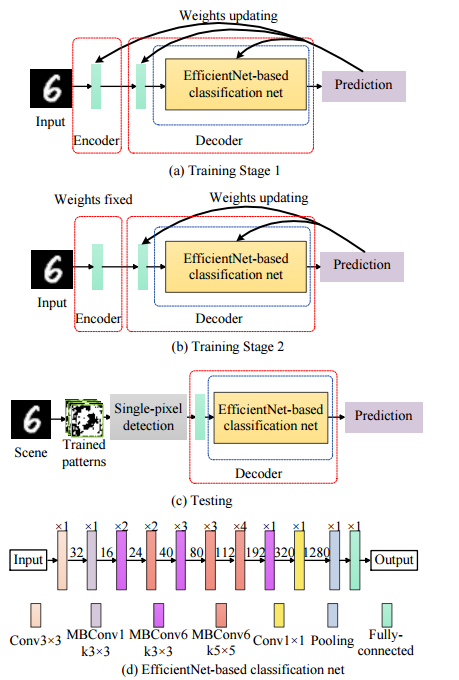
| Non-imaging single-pixel sensing with optimized binary modulation Authors Hao Fu, Liheng Bian, Jun Zhang 诸如图像分类之类的常规高级感测任务需要高保真度图像作为输入以提取目标特征,该目标特征由复杂的成像硬件或高复杂度的重建算法产生。在这封信中,我们提出了一种单像素传感SPS,该传感器直接从单个像素检测器的耦合测量结果执行传感任务,而无需常规的图像采集和重建过程。我们构建了一个深度卷积神经网络,其中包括目标编码器和感测解码器。该编码器模拟单个像素检测,并采用可在22kHz物理上实现的二进制调制。编码器和解码器都经过培训,以实现最佳感测精度。在手写MNIST数据集的分类任务上证明了SPS的有效性,并在1kHz时达到96.68的分类精度。与传统的成像传感框架相比,已报道的SPS技术需要较少的测量来实现快速的传感速率,保持较低的计算复杂性,较宽的工作频谱和较高的信噪比,并且进一步有利于通信和加密。 |
| CAT: Compression-Aware Training for bandwidth reduction Authors Chaim Baskin, Brian Chmiel, Evgenii Zheltonozhskii, Ron Banner, Alex M. Bronstein, Avi Mendelson 卷积神经网络CNN已成为解决视觉处理任务的主要神经网络体系结构。阻碍普遍使用CNN进行推理的主要障碍之一是其相对较高的内存带宽要求,这可能是主要的能源消耗和硬件加速器中的吞吐量瓶颈。因此,有效的特征图压缩方法可以导致实质性的性能提升。受量化意识训练方法的启发,我们提出了一种压缩意识训练CAT方法,该方法涉及以一种在推理过程中可以更好地压缩特征图的方式训练模型。我们的方法训练模型以实现低熵特征图,从而使用经典的变换编码方法在推理时实现有效压缩。 CAT显着改善了量化报告的最新技术水平。例如,在ResNet 34上,与基线相比,我们实现了73.1精度0.2降级,每个值的平均表示仅为1.79位。参考实现随附于 |
| Multi-modal segmentation with missing MR sequences using pre-trained fusion networks Authors Karin van Garderen, Marion Smits, Stefan Klein 数据丢失是机器学习中的常见问题,在回顾性成像研究中,它通常以丢失成像模态的形式遇到。我们建议在神经网络的设计和训练中考虑缺失的模态,以确保即使在没有多个图像的情况下,它们也能够提供最佳的预测。拟议的网络将对标准3D UNet架构的三种修改,具有模式退出功能的训练方案,最后阶段具有融合层的多路径架构以及这些路径的单独预训练相结合。使用BraTS多模式细分挑战,可以对完整和丢失数据的性能进行增量评估。最终模型相对于缺失数据的最新状态显示了显着改进,并且在训练过程中需要更少的内存。 |
| Efficient Residual Dense Block Search for Image Super-Resolution Authors Dehua Song, Chang Xu, Xu Jia, Chunjing Xu, Yunhe Wang 尽管由于深度卷积神经网络的兴起,单图像超分辨率取得了显着进步,但深度学习方法在实践中尤其是对于移动设备面临着计算和内存消耗的挑战。针对这个问题,我们提出了一种高效的具有多个目标的残差密集块搜索算法,以寻找快速,轻巧和准确的网络以实现图像超分辨率。首先,为了加速超分辨率网络,我们利用提出的有效残差密集块充分利用了特征尺度的变化。在提出的进化算法中,自动搜索合并和上采样算子的位置。其次,在大额信贷的指导下发展网络体系结构,以获取准确的超分辨率网络。大笔信用反映了当前大笔的影响,并在模型评估过程中获得。它通过权衡突变的采样概率来支持可钦佩的区块,从而指导进化。大量的实验结果证明了所提出的搜索方法的有效性,并且所发现的有效超分辨率模型比参数和FLOP数量有限的最新方法具有更好的性能。 |
| Beyond image classification: zooplankton identification with deep vector space embeddings Authors Ketil Malde, Hyeongji Kim 像许多其他现实世界中的数据类型一样,浮游动物图像具有固有的属性,这些属性使有效分类系统的设计变得困难。例如,在实际设置中遇到的类的数量可能非常大,并且类可能是模棱两可或重叠的。此外,研究人员之间和机构之间的分类选择通常不同。尽管使用标准分类器体系结构在基准测试中已经实现了高精度,但是当将输出用于生态系统评估和监测时,由不灵活的分类方案引起的偏差可能会产生深远的影响。 |
| Attention Convolutional Binary Neural Tree for Fine-Grained Visual Categorization Authors Ruyi Ji, Longyin Wen, Libo Zhang, Dawei Du, Ynajun Wu, Chen Zhao, Xianglong Liu, Feiyue Huang 细粒度的视觉分类FGVC由于变形,遮挡,照明等导致的类内差异高和类间差异小,是一项重要但具有挑战性的任务。提出了一种注意力卷积二叉神经树体系结构来解决弱监督FGVC的那些问题。具体来说,我们沿树结构的边缘合并了卷积运算,并在每个节点中使用路由功能来确定树中从根到叶的计算路径。将最终决策计算为来自叶节点的预测总和。深度卷积运算学习捕获对象的表示,并且树结构表征从粗糙到精细的层次特征学习过程。此外,我们使用注意转换器模块来强制网络捕获歧视性功能。负对数似然损失用于SGD通过反向传播以端到端的方式训练整个网络。在CUB 200 2011,斯坦福汽车和飞机数据集上进行的一些实验表明,所提出的方法在最新技术方面表现出色。 |
| Accurate and Compact Convolutional Neural Networks with Trained Binarization Authors Zhe Xu, Ray C. C. Cheung 尽管卷积神经网络CNN现在已广泛用于各种计算机视觉应用中,但其庞大的资源需要对参数进行存储和计算,这使得在移动和嵌入式设备上的部署变得困难。最近,人们探索了二进制卷积神经网络,以通过仅用1个位量化权重和激活来帮助缓解此问题。但是,与全精度模型相比,精度可能会明显下降。在本文中,我们提出了一种针对紧凑型二进制CNN的改进的训练方法,其准确性更高。引入了可训练的权重和激活比例因子,以增加值范围。这些缩放因子将通过反向传播与其他参数一起训练。此外,还开发了一种特定的训练算法,包括对不连续二值化函数的导数和作用于权重缩放因子的L 2正则化进行严格逼近。通过这些改进,二进制CNN在具有VGG Small Network的CIFAR 10上达到了92.3的精度。在ImageNet上,我们的方法在AlexNet上也获得了46.1最高的1精度,在Resnet 18上获得了54.2的精度,超过了先前的工作。 |
| Balancing Specialization, Generalization, and Compression for Detection and Tracking Authors Dotan Kaufman, Koby Bibas, Eran Borenstein, Michael Chertok, Tal Hassner 我们提出了一种将深度检测器和跟踪器专门用于受限设置的方法。设计我们的方法时要牢记以下目标:提高受限域的准确性b防止过度适应新域并忘记通用功能c积极的模型压缩和加速。为此,我们提出了一种新颖的损失,可以平衡深度学习模型的压缩和加速与泛化能力的损失。我们将我们的方法应用于现有的跟踪器和检测器模型。我们报告关于VIRAT和CAVIAR数据集的检测结果。这些结果表明,我们的方法可提供前所未有的压缩率以及改进的检测能力。我们会在测试时将其损失用于跟踪器压缩,因为它会处理每个视频。我们对OTB2015基准的测试表明,在测试期间应用压缩实际上会提高跟踪性能。 |
| FALCON: Fast and Lightweight Convolution for Compressing and Accelerating CNN Authors Chun Quan, Jun Gi Jang, Hyun Dong Lee, U Kang 如何在保留分类任务精度的同时有效压缩卷积神经网络CNN的一个有前途的方向是基于深度可分离卷积,它用深度卷积和点式卷积代替了标准卷积。但是,以前基于深度可分离卷积的工作是有限的,因为1它们大多是启发式方法,没有准确了解它们与标准卷积的关系,并且2其准确性与标准卷积不匹配。在本文中,我们提出了FALCON,这是一种压缩CNN的准确,轻巧的方法。 FALCON是通过使用EHP解释基于深度可分离卷积的现有卷积方法而得出的,EHP是我们提出的近似标准卷积核的数学公式。这样的解释导致开发了通用版本等级k FALCON,其进一步提高了准确性,同时牺牲了一点压缩和计算减少率。另外,我们通过将FALCON装配到最先进的卷积单元ShuffleUnitV2中来建议FALCON分支,从而提供更高的精度。实验表明,FALCON和FALCON分支在确保相似精度的同时,性能高达8倍压缩和8倍计算精简,性能优于1种基于深度可分离卷积的现有方法和2种标准CNN模型。我们还证明,在许多情况下,秩k FALCON的精度甚至比标准卷积更好,同时使用较少数量的参数和浮点运算。 |
| Cross-View Kernel Similarity Metric Learning Using Pairwise Constraints for Person Re-identification Authors T M Feroz Ali, Subhasis Chaudhuri 人员识别是在不重叠的摄像机之间匹配行人图像的任务。在本文中,我们提出了一种非线性交叉视图相似性度量学习,用于处理实际re ID系统中的小尺寸训练数据。该方法采用非线性映射,并结合基于成对相似性约束的交叉视图判别子空间学习和交叉视图距离度量学习。它是使用内核从线性映射到非线性映射的XQDA的自然扩展,并且学习了非线性转换,可以有效地处理摄像机视图之间人员外观的复杂非线性。重要的是,提出的方法在计算上非常有效。在四个具有挑战性的数据集上进行的广泛实验表明,我们的方法与最先进的方法相比具有竞争优势。 |
| Conditional Transferring Features: Scaling GANs to Thousands of Classes with 30% Less High-quality Data for Training Authors Chunpeng Wu, Wei Wen, Yiran Chen, Hai Li 生成对抗网络GAN大大提高了无监督图像生成的质量。先前的基于GAN的方法通常需要大量高质量的训练数据,同时产生少量例如数十个类。这项工作旨在将GAN的规模扩大到数千个课程,同时减少培训中对高质量数据的使用。我们提出一种基于条件传递特征的图像生成方法,该方法可以在将低质量图像转换为高质量图像时捕获像素级语义变化。此外,自我监督学习已集成到我们的GAN架构中,以提供从培训数据中观察到的更多无标签的语义监督信息。因此,训练我们的GAN架构所需的高质量图像要少得多,而附加的少量低质量图像也要少得多。在CIFAR 10和STL 10上进行的实验表明,即使从训练集中删除了30张高质量的图像,我们的方法仍然可以胜过以前的图像。对象类的可扩展性已通过实验验证,我们的方法减少了30幅高质量图像,在生成1,000个ImageNet类以及生成所有3,755类CASIA HWDB1.0中文手写字符方面获得了最佳的质量。 |
| Guided Attention Network for Object Detection and Counting on Drones Authors Yuanqiang Cai, Dawei Du, Libo Zhang, Longyin Wen, Weiqiang Wang, Yanjun Wu, Siwei Lyu 对象检测和计数是相关但具有挑战性的问题,尤其是对于具有小对象和杂乱背景的基于无人机的场景而言。在本文中,我们提出了一个新的引导式注意力网络GANet,用于处理基于特征金字塔的对象检测和计数任务。与以前的依赖非监督注意力模块的方法不同,我们通过在背景和对象之间使用拟议的弱监督背景注意力BA融合不同比例的特征图,以实现更多的语义特征表示。然后,开发了前景注意FA模块,以考虑对象的全局外观和局部外观,以促进准确的定位。此外,新的数据论证策略旨在在各种复杂场景中训练鲁棒模型。在三个具有挑战性的基准(即UAVDT,CARPK和PUCPR)上进行的广泛实验表明,与现有方法相比,该方法的检测和计数性能为最新水平。 |
| Stochastic Conditional Generative Networks with Basis Decomposition Authors Ze Wang, Xiuyuan Cheng, Guillermo Sapiro, Qiang Qiu 尽管生成对抗网络GAN彻底改变了机器学习,但仍有许多悬而未决的问题可以充分理解它们并发挥其功能。这些问题之一是如何有效地实现多模式数据空间的适当分集和采样。为了解决这个问题,我们介绍了BasisGAN,一种随机条件多模式图像生成器。通过利用卷积滤波器可以很好地近似为一小组基本元素的线性组合的观察,我们学习了即插即用的基本生成器,可以随机生成仅具有数百个参数的基本元素,以完全嵌入随机性到卷积滤波器。通过采样基本元素而不是过滤器,我们在不牺牲图像多样性或保真度的情况下,大大降低了建模参数空间的成本。为了说明此提议的即插即用框架,我们基于最先进的条件图像生成网络构造了BasisGAN的变体,并通过简单地插入基础生成器来训练网络,而无需其他辅助组件,超参数或训练目标。实验成功与理论结果相辅相成,这些理论结果表明所提议的基本元素采样所引入的扰动如何传播到生成图像的外观。 |
| Towards Automated Biometric Identification of Sea Turtles (Chelonia mydas) Authors Irwandi Hipiny, Hamimah Ujir, Aazani Mujahid, Nurhartini Kamalia Yahya 被动生物特征识别可以在最小干扰的情况下监控野生生物。我们使用抬高的动作摄像头并面向下,收集了海龟甲壳的图像,每个图像都属于十六种Chelonia mydas幼体之一。然后,我们从这些图像中学习了共变和鲁棒的图像描述符,从而实现了索引和检索。在这项工作中,我们使用学习到的图像描述符介绍了海龟甲壳的几个分类结果。我们发现,基于模板的描述符,即“定向梯度直方图” HOG在分类期间的性能要比基于关键点的描述符好得多。对于我们的数据集,由于甲壳图像中的渐变和颜色信息最少,因此必须具有高维描述符。使用HOG,我们获得了65的平均分类精度。 |
| Rescan: Inductive Instance Segmentation for Indoor RGBD Scans Authors Maciej Halber, Yifei Shi, Kai Xu, Thomas Funkhouser 在从家用机器人技术到AR VR的深度感测应用中,通常会以稀疏的时间间隔重复获取内部空间的3D扫描,例如作为日常日常使用的一部分。我们提出了一种算法,该算法分析这些重新扫描以推断带有语义实例信息的场景的时间模型。我们的算法通过使用过去观察到的时间模型来归纳地操作,以推断新扫描的实例分割,然后将其用于更新时间模型。该模型包含跨时间的对象实例关联,因此即使只有稀疏的观察结果,也可用于跟踪单个对象。在针对新任务使用新基准进行实验的过程中,我们的算法优于基于最新网络的语义实例细分的替代方法。 |
| Learning Propagation for Arbitrarily-structured Data Authors Sifei Liu, Xueting Li, Varun Jampani, Shalini De Mello, Jan Kautz 处理包含任意结构(例如,超像素和点云)的输入信号,仍然是计算机视觉中的一大挑战。线性扩散是一种有效的图像处理模型,最近已与深度学习算法集成在一起。在本文中,我们建议通过空间广义传播网络SGPN以全局方式学习数据点之间的成对关系,以改进对任意结构化数据的语义分割。网络通过学习的线性扩散过程,在代表任意结构化数据的一组图形上传播信息。该模块可以灵活地嵌入和与多种类型的网络(例如CNN)一起接受培训。我们使用语义分割网络进行实验,在该网络中,我们使用传播模块来共同训练不同的数据图像,超像素和点云。我们显示,与不包含此模块的网络相比,SGPN不断提高了像素和点云分割的性能。我们的方法提出了一种对任意结构化数据的全局成对关系建模的有效方法。 |
| Pretraining boosts out-of-domain robustness for pose estimation Authors Alexander Mathis, Mert Y ksekg n l, Byron Rogers, Matthias Bethge, Mackenzie W. Mathis 深度神经网络是用于人类和动物姿态估计的高效工具。但是,对域外数据的鲁棒性仍然是一个挑战。在这里,我们使用在ImageNet上预训练的两个体系结构类MobileNetV2s和ResNets探索姿势估计的传递和泛化能力。我们生成了一个包含30匹马的新颖数据集,该数据集允许在域内和域外进行看不见的马测试。我们发现在ImageNet上进行预培训可以大大提高域外性能。此外,我们表明,对于预训练和从头开始训练的网络,性能更好的ImageNet架构在姿态估计方面表现更好,并且在进行预训练时对域外数据有显着改善。总的来说,我们的结果表明,迁移学习对于域外鲁棒性特别有益。 |
| Intelligent image synthesis to attack a segmentation CNN using adversarial learning Authors Liang Chen, Paul Bentley, Kensaku Mori, Kazunari Misawa, Michitaka Fujiwara, Daniel Rueckert 基于卷积神经网络CNN的深度学习方法已成功解决了医学成像中的许多问题,包括图像分割。近年来,已经显示出CNN容易受到攻击,在这种攻击中,输入图像受到相对少量的噪声干扰,因此CNN不再能够以足够的精度对被干扰的图像进行分割。因此,探索有关如何攻击基于CNN的模型以及如何保护模型免受攻击的方法已成为热门话题,因为这也提供了对CNN的性能和泛化能力的见识。但是,大多数现有工作都采用了不切实际的攻击模型,即预先指定了产生的攻击。在本文中,我们提出了一种新颖的方法来生成对抗性示例,以攻击基于CNN的医学图像分割模型。我们的方法具有三个关键特征1生成的对抗示例在变形和外观扰动方面表现出解剖上的变化2对抗示例攻击分割模型,因此Dice得分降低了预先指定的数量3不需要指定攻击预先。我们已经评估了基于CNN的2D CT图像中多器官分割问题的方法。我们表明,所提出的方法可用于攻击基于CNN的不同细分模型。 |
| Anchor Loss: Modulating Loss Scale based on Prediction Difficulty Authors Serim Ryou, Seong Gyun Jeong, Pietro Perona 我们提出了一种新颖的损失函数,该函数根据关于样本的预测难度来动态地重新缩放交叉熵。图像分类任务中的深度神经网络架构难以消除视觉上相似的对象的歧义。同样,在人体姿态估计中,对称的身体部位经常使网络分配无差别的分数,从而使网络混乱。这是由于输出预测,其中仅选择了最高置信度标签,而未考虑不确定性的度量。在这项工作中,我们将预测难度定义为来自正负标签之间的置信度得分差距的相对属性。更精确地,所提出的损失函数对网络进行惩罚,以避免错误预测的分数显着。为了证明损失函数的功效,我们在两个不同的领域图像分类和人体姿势估计上对其进行了评估。与基线方法相比,通过实现更高的准确性,我们发现两种应用程序都有改进。 |
| Mixup Inference: Better Exploiting Mixup to Defend Adversarial Attacks Authors Tianyu Pang, Kun Xu, Jun Zhu 众所周知,对抗性示例可以很容易地制作成愚弄深度网络,其主要源于输入示例附近的局部非线性行为。在训练中应用混合可以提供一种有效的机制来提高泛化性能和模型对抗鲁棒性摄动的鲁棒性,从而在训练示例之间引入全局线性行为。但是,在先前的工作中,经过混合训练的模型只能通过直接分类输入来被动地抵御对抗性攻击,在这种情况下,不能很好地利用诱发的全局线性。即,由于对抗性扰动的局部性,因此通过模型预测的全局性主动地破坏局部性将更加有效。受简单的几何直觉启发,我们为混合训练模型开发了一个名为混合推理MI的推理原理。 MI将输入与其他随机干净样本混合,如果输入是对抗性的,则可以缩小并传递等效扰动。我们在CIFAR 10和CIFAR 100上的实验表明,MI可以进一步提高由混合及其变体训练的模型的对抗鲁棒性。 |
| Synthetic Data for Deep Learning Authors Sergey I. Nikolenko 合成数据是一种用于训练深度学习模型的越来越流行的工具,尤其是在计算机视觉以及其他领域。在这项工作中,我们尝试对合成数据的开发和应用中的各个方向进行全面的调查。首先,我们讨论用于基本计算机视觉问题的合成数据集,包括低级别(例如光流估计)和高级级别(例如语义分割),合成环境以及用于室外和城市场景自动驾驶的数据集,室内场景,室内导航,空中导航,模拟环境对于机器人技术,计算机视觉之外的合成数据在神经程序设计,生物信息学,NLP等领域的应用,我们还调查了有关改进合成数据开发和替代方法(例如GAN)的工作。其次,我们详细讨论了在合成数据的应用中不可避免出现的合成到实际领域的适应问题,包括使用基于GAN的模型进行的合成到实际精炼以及在没有显式数据转换的情况下在特征模型级别进行领域自适应。第三,我们转向合成数据的隐私相关应用程序,并回顾在生成具有不同隐私保证的合成数据集方面的工作。最后,我们着重介绍了在综合数据研究中开展进一步工作的最有希望的方向。 |
| Towards continuous learning for glioma segmentation with elastic weight consolidation Authors Karin van Garderen, Sebastian van der Voort, Fatih Incekara, Marion Smits, Stefan Klein 在对来自新域的数据进行卷积神经网络CNN调整时,灾难性的遗忘会降低原始训练数据的性能。弹性重量合并EWC是防止这种情况的最新技术,我们在训练和重新训练CNN以在两个不同的数据集上分割神经胶质瘤时进行了评估。该网络在公共BraTS数据集上进行了训练,并在内部数据集上进行了微调,这些数据集均包含非增强型低级别神经胶质瘤。在这种情况下,EWC被发现可以减少灾难性的遗忘,但同时也被发现可以限制对新领域的适应。 |
| Message Scheduling for Performant, Many-Core Belief Propagation Authors Mark Van der Merwe, Vinu Joseph, Ganesh Gopalakrishnan Belief Propagation BP是一种消息传递算法,用于对概率图形模型PGM进行近似推断,可以找到许多应用程序,例如计算机视觉,纠错码和蛋白质折叠。虽然一般而言,该算法的收敛性和速度限制了其在困难推理问题上的实际应用。作为高度适合并行化的算法,许多核心图形处理单元GPU可以显着提高BP性能。通过许多核心系统改善BP并非易事,算法中消息的调度强烈影响性能。我们对GPU上的BP消息调度进行了研究。我们证明了BP在并行性的基础上展现了速度和收敛之间的折衷,并表明现有消息调度无法利用这种折衷。为此,我们提出了一种新颖的随机消息调度方法,即Randomized BP RnBP,它优于GPU上的现有方法。 |
| Deep learning vessel segmentation and quantification of the foveal avascular zone using commercial and prototype OCT-A platforms Authors Morgan Heisler, Forson Chan, Zaid Mammo, Chandrakumar Balaratnasingam, Pavle Prentasic, Gavin Docherty, MyeongJin Ju, Sanjeeva Rajapakse, Sieun Lee, Andrew Merkur, Andrew Kirker, David Albiani, David Maberley, K. Bailey Freund, Mirza Faisal Beg, Sven Loncaric, Marinko V. Sarunic, Eduardo V. Navajas 在光学相干断层扫描血管造影OCT中自动量化小凹周围血管密度OCT A图像面临挑战,例如可变的内部和内部图像信噪比,来自外部脉管系统层的投影伪像以及运动伪像。这项研究证明了深度神经网络在健康和糖尿病眼中自动量化小凹无血管区FAZ参数和OCT A图像的小凹周围血管密度的实用性。使用三个OCT A系统(1060nm扫频光源SS OCT原型),RTVue XR Avanti Optovue Inc.(位于加利福尼亚州弗里蒙特)和蔡司Angioplex Carl Zeiss Meditec(加利福尼亚州都柏林),获取三个中央凹区的OCT A图像。然后使用深度神经网络执行自动分割。四个FAZ形态参数面积,最小最大直径,偏心率和小凹周围血管密度用作结果指标。在所有三个设备平台上,DNN血管分割的准确性,敏感性和特异性均相当。对于任何系统上的任何结果度量,在自动和手动分割的度量方法之间均未发现显着差异。对于所有测量,组内相关系数ICC也为0.51。 OCT A的自动深度学习血管分割可能适用于商业和研究目的,以更好地量化视网膜循环。 |
| Domain-invariant Learning using Adaptive Filter Decomposition Authors Ze Wang, Xiuyuan Cheng, Guillermo Sapiro, Qiang Qiu 在现实世界中经常遇到域转移。在本文中,我们通过在卷积神经网络CNN中仅使用少量领域特定参数对领域转移进行显式建模来考虑领域不变深度学习的问题。通过观察到卷积滤波器可以很好地近似为一组基本元素的线性组合的观察结果,我们首次从经验和理论上表明,通过将常规卷积层分解为领域特定基础层和领域共享基础系数层,同时保持卷积。现在,输入通道将首先仅在空间上与每个特定领域特定基础卷积以吸收领域变化,然后使用经过训练可促进跨领域共享语义的公共基础系数对输出通道进行线性组合。我们使用玩具示例,严格的分析和真实的示例来说明框架在跨域性能和域适应方面的有效性。使用建议的体系结构,我们只需要少量基础元素即可对每个附加域进行建模,这带来了可忽略的附加参数数量,通常为数百个。 |
| Sign Language Recognition Analysis using Multimodal Data Authors Al Amin Hosain, Panneer Selvam Santhalingam, Parth Pathak, Jana Kosecka, Huzefa Rangwala 语音控制的个人和家庭助理(例如Amazon Echo和Apple Siri)在各种应用程序中正变得越来越流行。但是,聋哑或听力障碍DHH用户无法轻松获得这些技术的优势。这项研究的目的是使用DHH签名者可以用来与语音控制设备进行交互的多种方式来开发和评估一种符号识别系统。随着深度传感器的发展,骨骼数据被用于视频分析和活动识别等应用。尽管与经过充分研究的人类活动识别相似,但在手语识别中很少使用3D骨架数据。这是因为与活动识别不同,手语主要取决于手的形状模式。在这项工作中,我们研究了结合使用不同深度学习架构将骨骼和RGB视频数据用于手语识别的可行性。我们在12个用户和跨越51个标志的13107个样本的大规模美国手语ASL数据集中验证了我们的结果。它被命名为GMUASL51。我们在6个月内收集了该数据集,并将其公开发布,以期推动进一步的机器学习研究,以改善数字助理的可访问性。 |
| Carving out the low surface brightness universe with NoiseChisel Authors Mohammad Akhlaghi NoiseChisel是一个程序,用于以极少的形态假设来检测极低的信噪比S N特征。它于2015年推出,并在一系列数据分析程序和称为GNU Astronomy Utilities Gnuastro的库中发布。在Gnuastro的最近十个稳定版本中,NoiseChisel大大改善了检测甚至更微弱的信号的能力,从而使用户可以更好地控制其内部工作,并修复了许多错误。最重要的变化可能是,NoiseChisel的分割功能已移至名为“分段”的新程序中。另一个重大变化是其真正检测的最终增长策略,例如,NoiseChisel能够在单个曝光的SDSS图像r波段上检测出M51的外翼,直至S N为0.25或28.27 mag arcsec2。段也能够成功地检测到局部的HII区域。最后,为了组织受控分析,讨论了可复制纸张的概念,本文本身就是可复制快照v4 0 g8505cfd。 |
| Augmenting the Pathology Lab: An Intelligent Whole Slide Image Classification System for the Real World Authors Julianna D. Ianni, Rajath E. Soans, Sivaramakrishnan Sankarapandian, Ramachandra Vikas Chamarthi, Devi Ayyagari, Thomas G. Olsen, Michael J. Bonham, Coleman C. Stavish, Kiran Motaparthi, Clay J. Cockerell, Theresa A. Feeser, Jason B. Lee 可疑皮肤癌的护理诊断程序的标准是由病理学家对苏木精曙红染色的组织进行显微镜检查。病理学家之间的高度不一致和活检率上升的地区需要更高的效率和诊断的可重复性。我们提出并验证了一种深度学习系统,该系统将数字化皮肤病理学幻灯片分为4类。该系统使用来自单个实验室的5,070张图像进行开发,并使用3家不同供应商制造的整体幻灯片扫描仪在来自3个测试实验室的未经固化的13,537张图像上进行了测试。该系统使用基于深度学习的置信度评分作为将结果视为准确的标准,可产生高达98的准确度,并使其可在现实环境中采用。在没有置信度评分的情况下,该系统的准确性为78。我们预计,我们的深度学习系统将成为基础,可以更快地诊断皮肤癌,确定病例以进行专科医生审查以及针对性的诊断分类。 |
| Accept Synthetic Objects as Real: End-to-End Training of Attentive Deep Visuomotor Policies for Manipulation in Clutter Authors Pooya Abolghasemi, Ladislau B l ni 最近的研究表明,利用示范LfD和强化学习RL的学习变异来端到端地训练机器人操作的多任务深视觉运动策略是可行的。在本文中,我们将端到端LfD架构的功能扩展到混乱中的对象操作。我们首先介绍称为“接受合成对象作为真实ASOR”的数据增强过程。使用ASOR,我们开发了两种网络体系结构:隐式注意ASOR IA和显式注意ASOR EA。两种架构在整洁的环境中都使用与以前的方法相同的训练数据演示。实验结果表明,在杂乱的环境中,ASOR IA和ASOR EA在相当多的试验中都取得了成功,而以前的方法从未成功。此外,我们发现,即使在整洁的环境中,ASOR IA和ASOR EA的性能也比以前的方法好,即使在整洁的环境中,ASOR EA的性能也比以前的最佳基准要好。 |
| Chinese Abs From Machine Translation |


{kind=link}