AI视野·今日CS.CV 计算机视觉论文速览
Mon, 21 Oct 2019
Totally 34 papers
?上期速览✈更多精彩请移步主页

Interesting:
?****基于立体视觉的三维重建方法, (from 哈工大 商汤)
?***环境重光照数据集, (from CSAIL adobe)

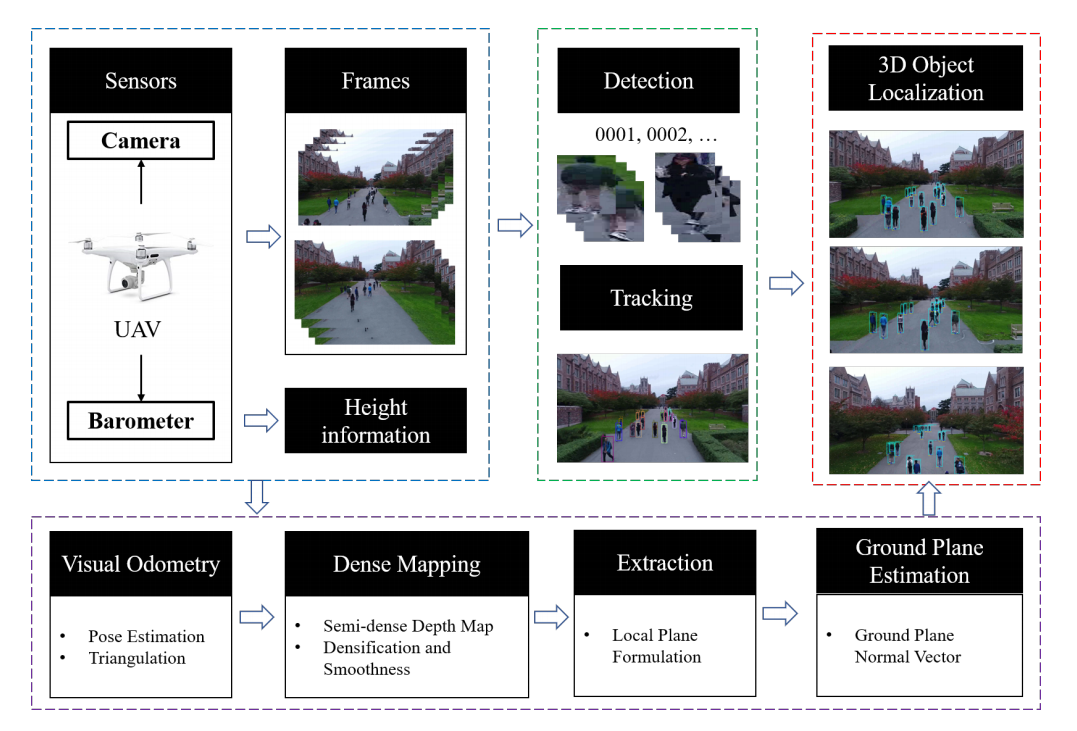
?基于无人机的目标追踪和三维定位, (from 华盛顿大学)
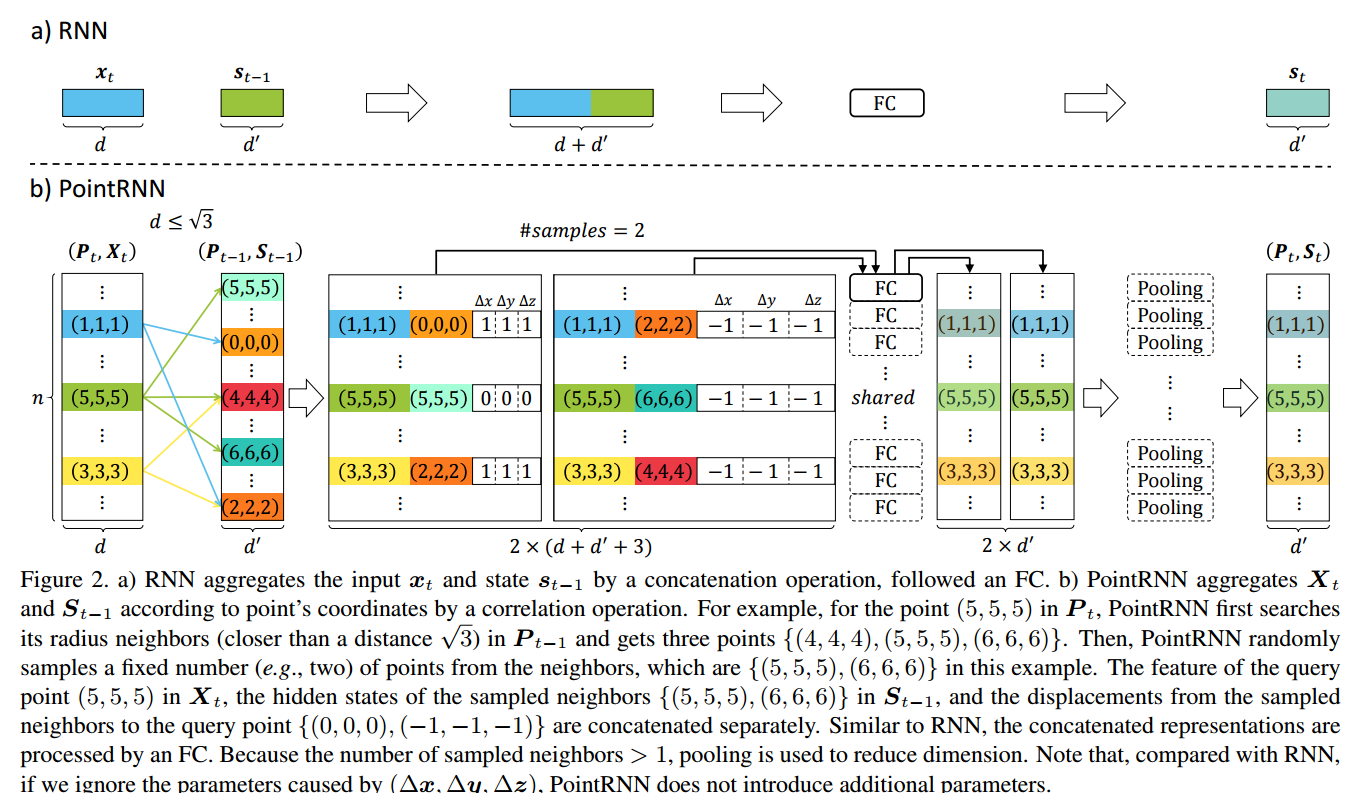
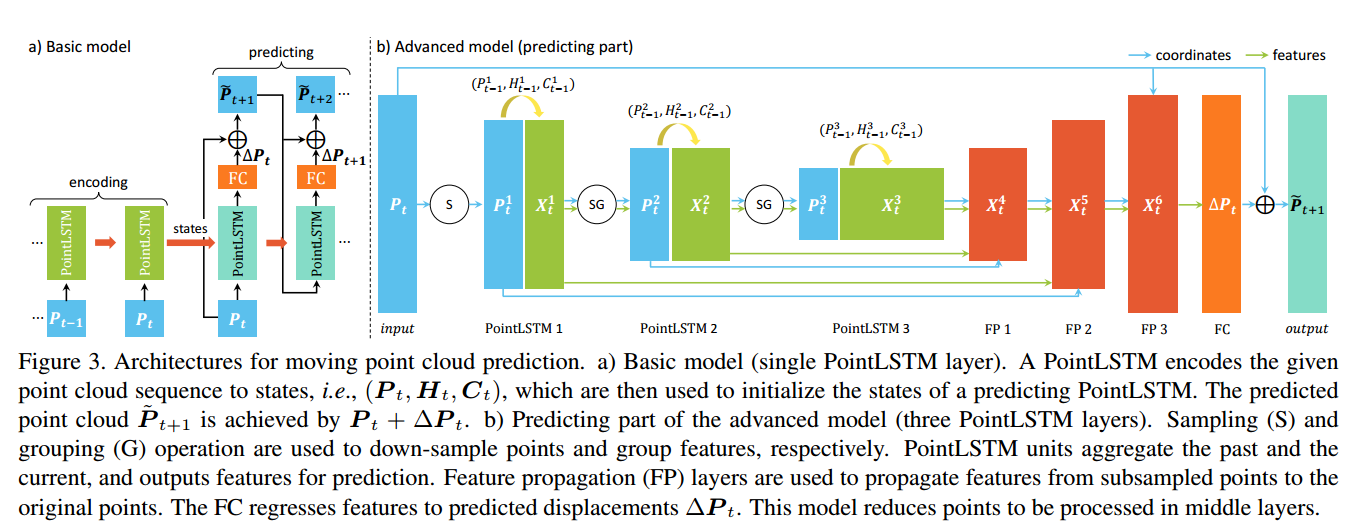
?PointRNN运动点云的预测新方法, (from 悉尼科技大学 ReLER Lab)
code:https://github.com/hehefan/PointRNN
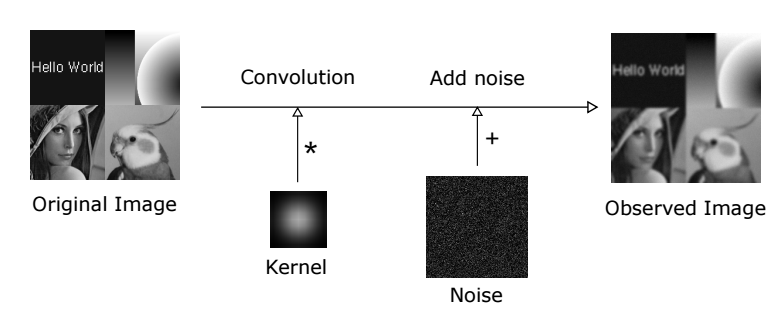
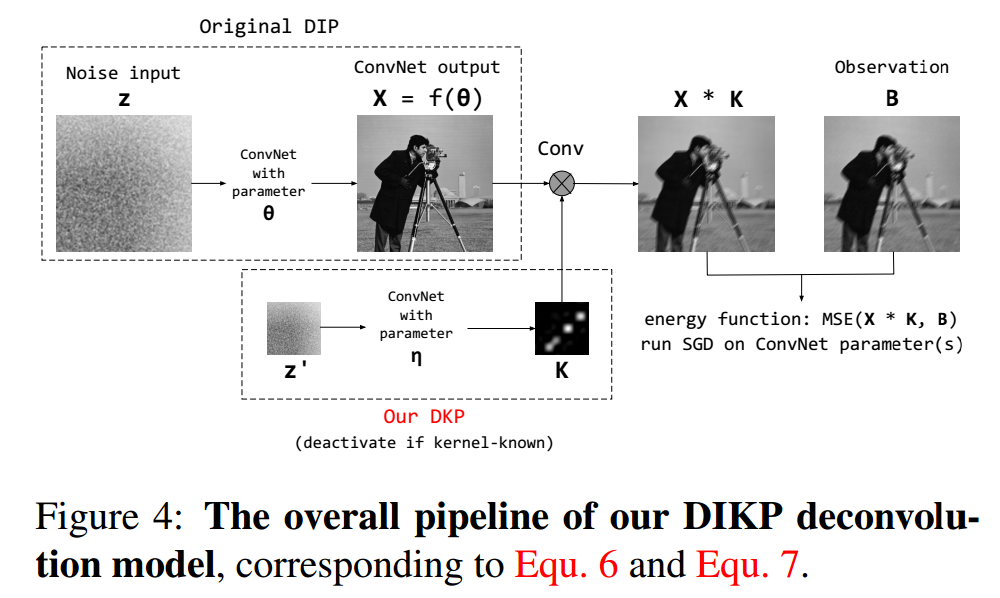
?***基于图像及核先验的解卷积方法用于图像逆问题求解, (from 爱丁堡大学信息学院)
1013-1020拾遗:
****基于稀疏lidar和深度法向量约束的深度补全方法,(from 商汤 港中文 浙大CAD CG实验室)
***上下文门控卷积,(from 哥伦比亚大学 腾讯AI lab)
***基于卫星图像的建筑损伤检测,(from google)
基于端到端多视角融合的点云三维检测模型,(from google waymo)
微型视频网络,(from,谷歌 机器人组)
**基于深度学习的光场合成技术
利用学习的艺术决策实现自动航拍摄影,(from cmu)
基于激光雷达和相机的低光照目标检测
KonIQ-10k审美评价数据集
数据驱动的机器人末端执行器位置估计
Daily Computer Vision Papers
| Single and Cross-Dimensional Feature Detection and Description: An Evaluation Authors Odysseas Kechagias Stamatis, Nabil Aouf, Mark A. Richardson 三维局部特征检测和描述技术已广泛用于对象注册和识别应用。尽管已经发布了3D局部特征检测和描述方法的几种评估方法,但这些评估方法都局限于一维方案,即应用于3D数据多个投影的3D或2D方法。但是,尚未对多维混合2D和3D特征检测和描述进行研究。在这里,我们评估了几个3D数据集上的单维和跨维特征检测和描述方法的性能,并证明了跨维优于单维方案。 |
| Understanding Deep Networks via Extremal Perturbations and Smooth Masks Authors Ruth Fong, Mandela Patrick, Andrea Vedaldi 归因问题与确定输入中负责模型输出的部分有关。一个重要的归因方法系列基于测量对输入施加扰动的影响。在本文中,我们讨论了现有扰动分析方法的一些缺点,并通过介绍极端扰动的概念来解决这些缺点,这些概念在理论上是可以理解的。我们还引入了许多技术创新来计算极端扰动,包括新的面积约束和平滑扰动的参数族,这使我们能够从优化问题中删除所有可调超参数。我们分析了微扰作为其面积的函数的影响,表明对刺激下的深度神经网络的空间特性具有出色的敏感性。我们还将扰动分析扩展到网络的中间层。此应用程序使我们能够识别分类所必需的显着通道,当使用特征反转将其可视化时,这些显着通道可用于阐明模型行为。最后,我们介绍TorchRay,这是一个基于PyTorch构建的可解释性库。 |
| Illumination-Based Data Augmentation for Robust Background Subtraction Authors Dimitrios Sakkos, Hubert P. H. Shum, Edmond S. L. Ho 背景减法BGS的核心挑战是处理连续帧中照明突然变化的视频。在本文中,我们使用数据增强从数据的角度解决了这个问题。我们的方法执行的数据增强不仅可以动态创建无尽的数据,而且还具有照明的语义转换功能,可以增强模型的通用性。通过在随机生成的二进制蒙版上应用欧几里德距离变换,它成功地模拟了闪光和阴影。这样的数据使我们能够有效地为BGS训练光照不变深度学习模型。实验结果表明,即使发生明显的光照变化,合成材料也对模型执行BGS的能力做出了贡献。该项目的源代码在以下位置公开可用 |
| A novel centroid update approach for clustering-based superpixel method and superpixel-based edge detection Authors Houwang Zhang, Chong Wu, Le Zhang, Hanying Zheng 超像素广泛用于图像处理。在用于超像素生成的方法中,基于聚类的方法同时具有较高的速度和良好的性能。但是,大多数基于聚类的超像素方法对噪声都很敏感。为了解决这些问题,本文首先分析噪声的特征。然后根据噪声的统计特征,提出一种新颖的质心更新方法,以增强基于聚类的超像素方法的鲁棒性。此外,我们提出了一种新颖的基于超像素的边缘检测方法。 BSD500数据集上的实验表明,我们的方法可以在嘈杂的环境中显着提高基于聚类的超像素方法的性能。此外,我们还表明,我们提出的边缘检测方法优于其他经典方法。 |
| Image Deconvolution with Deep Image and Kernel Priors Authors Zhunxuan Wang, Zipei Wang, Qiqi Li, Hakan Bilen 图像去卷积是恢复卷积退化图像的过程,由于其数学不适定的性质,这始终是一个困难的逆问题。基于最近提出的深度图像先验DIP的成功,我们建立了具有深度图像和核先验DIKP的图像反卷积模型。 DIP是一种无学习的表示形式,它使用神经网络结构来表达图像先验信息,并且在许多基于能量的模型(例如,能量模型)中显示出了巨大的成功。去噪,超分辨率,修复。相反,我们的DIKP模型在图像反卷积中使用了这种先验知识,不仅对图像建模,而且还对内核建模,将传统的免费学习反卷积方法的思想与神经网络相结合。在本文中,我们证明了DIKP可以提高学习自由图像反卷积的性能,并在PSNR和视觉效果方面在六张标准测试图像的标准基准上进行实验证明。 |
| Deformable Kernel Networks for Joint Image Filtering Authors Beomjun Kim, Jean Ponce, Bumsub Ham 在增强空间分辨率和抑制噪声等任务中,联合图像滤镜用于从目标图像之前的引导图片中传输结构细节。以前基于卷积神经网络CNN的方法结合了空间不变核的非线性激活来估计结构细节并回归过滤结果。在本文中,我们改为明确学习稀疏和空间变异的内核。我们提出了一种CNN体系结构及其有效实现,称为可变形内核网络DKN,该结构可为每个像素自适应地输出邻居集和相应的权重。然后将滤波结果计算为加权平均值。我们还提出了DKN的快速版本,对于640 x 480尺寸的图像,它的运行速度快约17倍。我们演示了我们的模型在深度图上采样,显着图上采样,跨模态图像恢复,纹理上的有效性和灵活性删除和语义分割。特别是,我们表明,在所有情况下,使用稀疏采样的3 x 3内核的加权平均过程的性能均优于现有技术。 |
| Automatic Data Augmentation by Learning the Deterministic Policy Authors Yinghuan Shi, Tiexin Qin, Yong Liu, Jiwen Lu, Yang Gao, Dinggang Shen 为了产生足够的和多样化的训练样本,数据增强已经证明了其在训练深度模型中的有效性。关于最佳扩充的标准难以定义,我们在本文中提出了一种新颖的基于学习的扩充方法,称为DeepAugNet,它将最终的扩充数据表述为几个顺序扩充子集的集合。具体地,通过使用深度增强学习来学习确定性增强策略,需要当前增强子集以与上一个增强子集相比最大化性能改进。通过引入统一的优化目标,DeepAugNet打算以端到端的训练方式将数据扩充和深度模型训练相结合,这是通过同时训练双重深度Q学习算法和替代深度模型的混合架构来实现的。我们在各种基准数据集(包括Fashion MNIST,CUB,CIFAR 100和WebCaricature)上广泛评估了我们提议的DeepAugNet。与当前的技术水平相比,我们的方法可以在小规模数据集上实现显着改进,并在大规模数据集上具有可比的性能。代码即将推出。 |
| KerCNNs: biologically inspired lateral connections for classification of corrupted images Authors Noemi Montobbio, Laurent Bonnasse Gahot, Giovanna Citti, Alessandro Sarti 卷积神经网络CNN代表了许多计算机视觉任务中的最新技术。尽管它们的层次结构和局部特征提取受到灵长类动物视觉系统的结构的启发,但此类体系结构中缺乏横向连接,使它们的分析与生物对象处理区别开来。近年来,以卷积类型的循环侧向连接来丰富CNN的想法已经实现,其形式是没有几何约束的学习型循环核。在当前的工作中,我们介绍了生物学上可行的横向核,该核对每层CNN前馈滤波器之间的相关性进行了编码,相关的核充当了激活空间上的过渡核。横向核是根据滤波器定义的,因此提供了一种无参数的方法来基于前馈结构评估水平连接的几何形状。然后,我们将对这种称为KerCNN的新体系结构进行测试,以应对与全局形状分析和图案完成相关的泛化任务,一旦完成了对进行基本图像分类的培训,就可以对损坏的测试图像进行网络评估。所检查的图像扰动旨在破坏通过局部特征对图像的识别,因此需要整合上下文信息,该上下文信息在生物视觉中与横向连接性至关重要。事实证明,我们的KerCNN比CNN更加稳定,并且对于此类降解,CNN经常发生,因此验证了这种在生物学上受启发的方法,可以在挑战性条件下增强目标识别能力。 |
| Multimodal Image Super-resolution via Deep Unfolding with Side Information Authors Iman Marivani, Evaggelia Tsiligianni, Bruno Cornelis, Nikos Deligiannis 深度学习方法已成功应用于各种计算机视觉任务。但是,现有的神经网络体系结构本身并没有包含有关已解决问题的领域知识,因此,了解模型学到的知识是一个开放的研究主题。在本文中,我们依赖于迭代算法的展开以实现带有辅助信息的稀疏近似,并设计了一种多模式图像超分辨率的深度学习架构,该架构融合了稀疏先验并有效地利用了来自另一图像模态的信息。我们开发了两个深层模型,借助第二种模态的高分辨率图像,可以从其低分辨率变量中重建目标图像模态的高分辨率图像。我们将建议的模型用于高分辨率高分辨率RGB图像作为辅助信息来近分辨近红外图像。实验结果证明了所提出的模型相对于包括单峰和多峰方法在内的最新方法的优越性能。 |
| Diversity in Fashion Recommendation using Semantic Parsing Authors Sagar Verma, Sukhad Anand, Chetan Arora, Atul Rai 由于与用户所看的标准相关的内在含混性,为时尚图像开发推荐系统具有挑战性。在不同特征或部分的基础上建议每个输出图像与查询图像相似的多个图像是缓解问题的一种方法。现有的时尚推荐作品已经使用连体或三联体网络来学习相似对和相似异种三联体之间的特征。但是,这些方法没有提供基本信息,例如,两个服装图像如何相似,或者两个图像中存在哪些部分使它们相似。在本文中,我们建议通过显式学习和利用基于零件的相似性来推荐图像。我们提出了一种新颖的方法,通过在零件上使用视觉注意力和纹理编码网络,从弱监督数据中学习区分特征。我们显示,在DeepFashion数据集的检索任务中,学习到的特征超越了现有技术。然后,我们使用提出的模型来推荐时尚图像,这些图像在任何部分的相似性方面都有明显的变化。 |
| PointRNN: Point Recurrent Neural Network for Moving Point Cloud Processing Authors Hehe Fan, Yi Yang 点云正在社区中吸引越来越多的关注。但是,很少有研究动态点云。在本文中,我们介绍了一种用于移动点云处理的点递归神经网络PointRNN单元。为了保持空间结构,PointRNN而不是像RNN那样将mathbb R d中的唯一一维矢量粗体符号x作为输入,而是将点坐标在mathbb R n中乘以3的粗体符号P,并将其特征在Mathbb R n n d中作为输入的粗体符号X。 n和d分别表示点数和特征尺寸。相应地,RNN中mathbb R d中的状态粗体符号s扩展为boldsymbol P,PointRNN d中mathbb R n中的n d的粗体符号S表示状态维数。由于点云是无序的,因此无法直接操作两个相邻时间步的特征和状态。因此,PointRNN用相关运算代替RNN中的级联运算,该运算根据点坐标汇总输入和状态。为了评估PointRNN,我们将其变体之一即Point Long短期记忆PointLSTM应用于移动点云预测,该移动点云预测旨在根据给定的历史运动来预测云中点的未来轨迹。实验结果表明,PointLSTM能够在合成数据集和现实世界数据集上产生正确的预测,证明了其对点云序列建模的有效性。该代码已在发布 |
| BOBBY2: Buffer Based Robust High-Speed Object Tracking Authors Keifer Lee, Jun Jet Tai, Swee King Phang 在这项工作中,一种名为BOBBY2的新型高速单目标跟踪器具有很强的抵抗非语义干扰样本的能力。它集成了新颖的示例缓冲模块,可在整个时间间隔内稀疏地缓存目标的外观,使其能够适应潜在的目标变形。至于训练,将增强的ImageNet VID数据集与单周期策略结合使用,使其能够以不到2个纪元的数据达到收敛。为了验证,该模型在GOT 10k数据集和其他小型但具有挑战性的定制UAV数据集(使用TU 3 UAV收集)上进行了基准测试。我们证明了示例缓冲区能够在意外目标漂移的情况下提供冗余,这是任何中长期跟踪中的理想特性。即使缓冲区中主要是分散器而不是有效样本,BOBBY2仍能够保持接近最佳的准确性。 BOBBY2设法在GOT 10k数据集上取得了非常有竞争力的结果,而在具有挑战性的定制TU 3数据集上却取得了较小的竞争,而没有进行微调,这证明了它的通用性。在速度方面,BOBBY2使用精简的AlexNet作为特征提取器,其参数比普通AlexNet少63个,因此能够以具有竞争力的85 FPS运行。 |
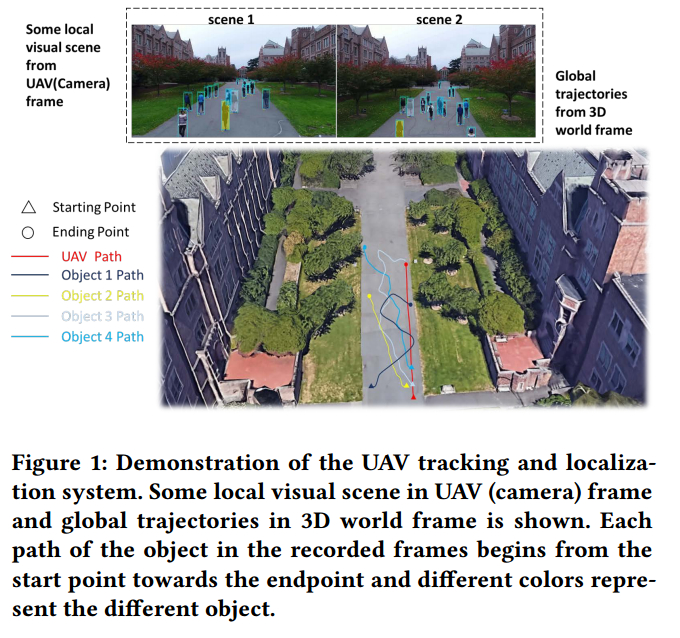
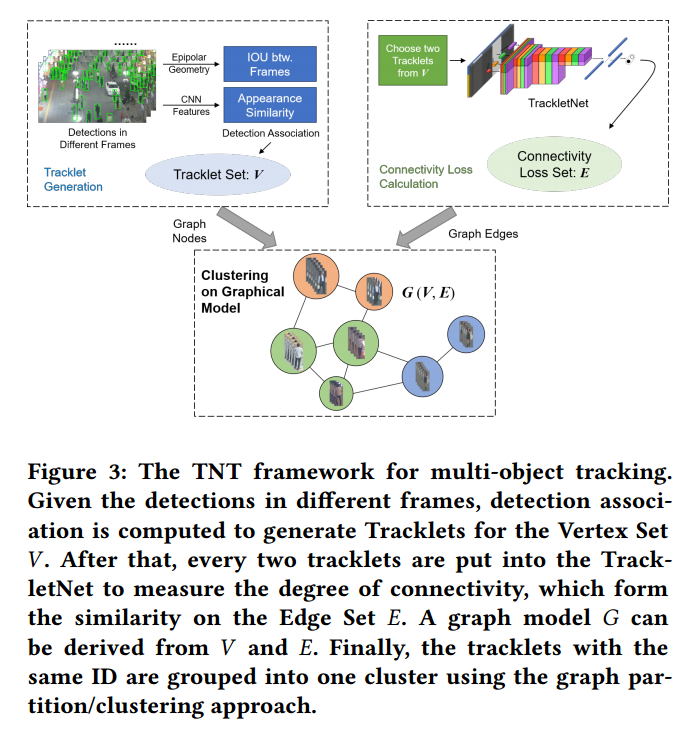
| Eye in the Sky: Drone-Based Object Tracking and 3D Localization Authors Haotian Zhang, Gaoang Wang, Zhichao Lei, Jenq Neng Hwang 配备有单个摄像头的无人机或通用无人机已广泛部署到广泛的应用中,例如航空摄影,快速交货和最重要的监视。尽管在计算机视觉算法中取得了巨大进步,但是由于各种挑战(例如遮挡,快速摄像机运动和姿势变化),这些算法通常并未针对处理无人机获取的图像或视频序列进行优化。在本文中,基于基于深度学习的目标检测,提出了一种基于无人机的多目标跟踪和3D定位方案。我们首先结合了一种称为TrackletNet Tracker TNT的多对象跟踪方法,该方法利用时间和外观信息来跟踪检测到的无人机上地面物体。然后,我们还能够根据从多视图立体技术估计的组平面来定位跟踪的地面对象。部署在无人机上的系统不仅可以检测和跟踪场景中的对象,还可以相对于无人机摄像机以米为单位定位其3D坐标。实验证明,与现有方法相比,我们的跟踪器可以可靠地处理大多数无人机捕获的检测对象,并具有良好的3D定位性能。 |
| AFO-TAD: Anchor-free One-Stage Detector for Temporal Action Detection Authors Yiping Tang, Chuang Niu, Minghao Dong, Shenghan Ren, Jimin Liang 时间动作检测是视频理解中一项基本但具有挑战性的任务。许多现有技术方法基于类似于二维物体检测检测器的预定锚来预测动作实例的边界。但是,很难检测到具有预定时间尺度的所有动作实例,因为未修剪视频中的实例持续时间可能会从几秒钟到几分钟不等。在本文中,我们提出了一种新颖的动作检测架构,称为无锚一级临时动作检测器AFO TAD。 AFO TAD可以更好地检测具有任意长度和高时间分辨率的动作实例,这可以归因于两个方面。首先,我们设计了一个接收场自适应模块,该模块可以动态调整接收场,以进行精确的动作检测。其次,AFO TAD在没有预定锚点的情况下直接预测每个时间位置的类别和边界。大量实验表明,AFO TAD改善了THUMOS 14的最新性能。 |
| Investigating Task-driven Latent Feasibility for Nonconvex Image Modeling Authors Risheng Liu, Pan Mu, Jian Chen, Xin Fan, Zhongxuan Luo 适当地对潜像分布进行建模在各种低级视觉问题中始终起着关键作用。大多数现有方法(例如“最大后验MAP”)旨在通过事先进行正则化来建立优化模型来解决此任务。然而,设计复杂的先验可能会导致挑战性的优化模型和耗时的迭代过程。最近的研究试图将可学习的网络体系结构嵌入MAP方案。不幸的是,对于先验训练有素的MAP模型,确切的行为和推理过程实际上是难以研究的,因为它们不精确且不受控制。在这项工作中,通过研究基于任务的基于MAP的模型的潜在可行性,我们提供了一个新的视角来强制将领域知识和数据分布应用于基于MAP的图像建模。具体来说,我们首先将基于能量的可行性约束引入给定的MAP模型。通过将近端梯度更新方案引入目标并执行自适应平均过程,我们获得了用于图像建模的全新MAP推理过程,称为近邻平均优化PAO。由于PAO的灵活性,我们还可以将经过深度培训的体系结构合并到可行性模块中。最后,我们提供了一个简单的基于单调下降的控制机制来指导PAO的传播。我们从理论上证明,由我们的PAO及其基于学习的扩展生成的序列可以成功地收敛到原始MAP优化任务的关键点。我们演示了如何应用我们的框架来解决不同的视觉应用。大量实验验证了理论结果,并表明了我们的方法相对于现有技术水平的优势。 |
| Spatially-Aware Graph Neural Networks for Relational Behavior Forecasting from Sensor Data Authors Sergio Casas, Cole Gulino, Renjie Liao, Raquel Urtasun 在本文中,我们解决了根据传感器数据预测关系行为的问题。为了实现这一目标,我们提出了一种新颖的空间感知图神经网络SpAGNN,该模型对场景中智能体之间的交互进行建模。具体来说,我们利用卷积神经网络来检测参与者并计算其初始状态。图神经网络然后通过消息传递过程迭代地更新参与者状态。受高斯信念传播的启发,我们将消息设计为来自相邻代理的输出分布的空间变换参数。我们的模型是完全可区分的,因此可以进行端到端培训。重要的是,我们的概率预测可以在轨迹水平上对不确定性进行建模。通过在两个真实世界的自动驾驶数据集ATG4D和nuScenes上对现有技术进行重大改进,我们展示了我们方法的有效性。 |
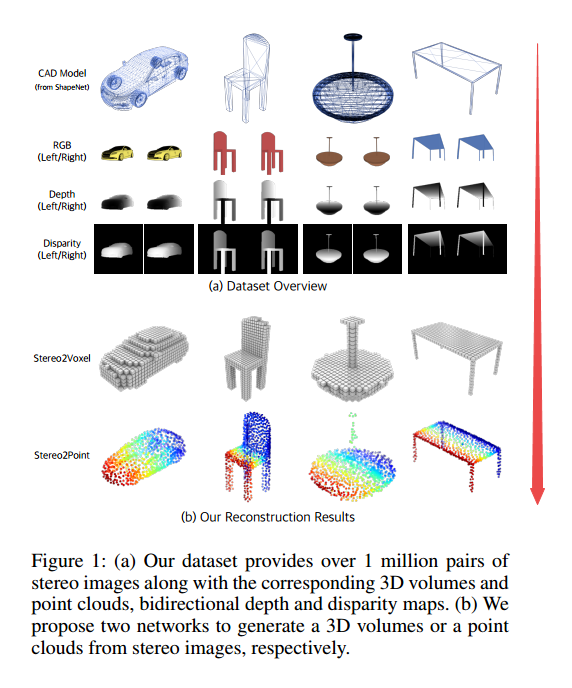
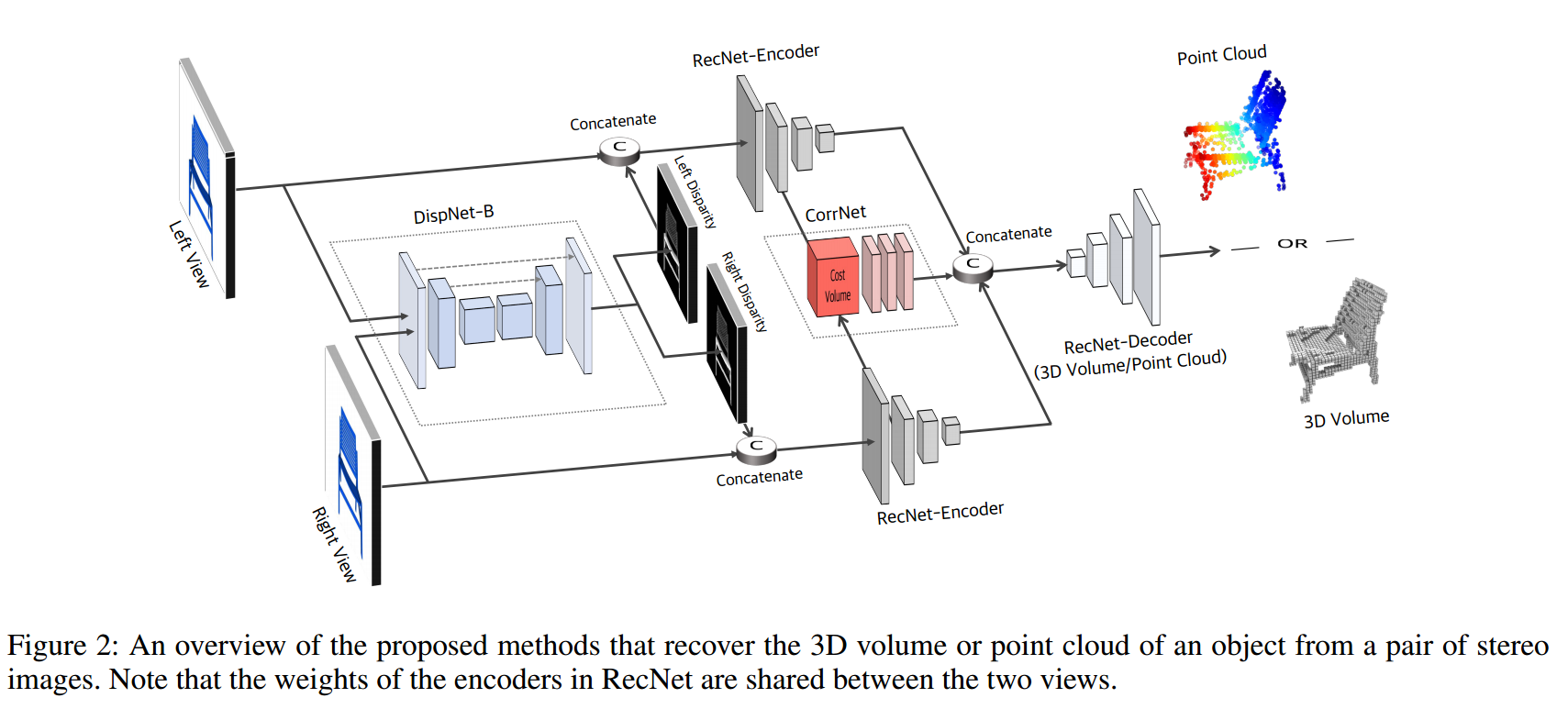
| Toward 3D Object Reconstruction from Stereo Images Authors Haozhe Xie, Hongxun Yao, Shangchen Zhou, Shengping Zhang, Xiaoshuai Sun, Wenxiu Sun 从RGB图像推断对象的3D形状已显示出令人印象深刻的结果,但是,现有方法主要依赖于从训练集中识别出最相似的3D模型来解决问题。这些方法的概括性很差,并且可能导致看不见的对象的重建质量较低。如今,立体相机在双镜头智能手机和机器人等新兴设备中无处不在,这使得能够利用立体图像的两种视图特性来探索3D结构,从而提高重建性能。在本文中,我们提出了一种新的深度学习框架,用于从一对立体图像中重建对象的3D形状,该框架通过考虑双向视差和两个视图之间的特征对应关系来说明对象的3D结构。此外,我们提出了一个大规模的综合基准数据集,即StereoShapeNet,其中包含从ShapeNet渲染的1,052,976对立体图像,以及相应的双向深度和视差图。在StereoShapeNet基准上的实验结果表明,提出的框架优于最新方法。 |
| Unsupervised Multi-Task Feature Learning on Point Clouds Authors Kaveh Hassani, Mike Haley 我们引入了无监督的多任务模型,以共同学习点云上的点和形状特征。我们定义了三个非监督任务,包括聚类,重构和自我监督分类,以训练基于多尺度图的编码器。我们评估形状分类和细分基准的模型。结果表明,它优于现有的无监督模型。在ModelNet40分类任务中,它的准确度为89.1,在ShapeNet分割任务中,其mIoU为68.2,准确度为88.6。 |
| Deep Weakly-Supervised Domain Adaptation for Pain Localization in Videos Authors Gnana Praveen R, Eric Granger, Patrick Cardinal 自动疼痛评估对于难以表达其疼痛经历的人们具有重要的潜在诊断价值。面部表情作为引发疼痛表达事件的主要非语言渠道之一,起着至关重要的作用,它已被广泛用于估算单个视频的疼痛强度。但是,在现实世界中的疼痛评估应用程序中使用最先进的深度学习DL模型提出了一些挑战,这些挑战涉及面部表情的主观变化,操作捕捉条件以及缺乏带有标签的代表性培训视频。考虑到为每个视频帧注释强度级别的代价,提出了一种弱监督的域自适应WSDA技术来训练DL模型,以便从视频中估计时空疼痛强度。对操作条件的深域适应依赖于目标域视频,这些目标域视频会定期为每个视频序列提供针对疼痛强度级别的弱标记标签。尤其是,WSDA将多实例学习集成到对抗性的深域适应框架中,以训练膨胀的3D CNN I3D模型,从而可以准确地估计目标操作域中的疼痛强度。训练机制利用弱的监督损失以及域损失和源监督损失来进行I3D模型的域适应。使用来自RECOLA数据集的标记源域视频和弱标记目标域UNBC McMaster视频获得的实验结果表明,与相关技术水平相比,建议的深度WSDA方法可以实现更高水平的序列袋级和帧实例级疼痛定位精度方法。 |
| RPBA -- Robust Parallel Bundle Adjustment Based on Covariance Information Authors Helmut Mayer Motion SfM方法中所有“结构”的核心组件是捆绑调整。由于后者是较大块的计算瓶颈,因此并行束调整已成为研究的活跃领域。特别地,基于共识的优化方法已被证明适用于此任务。我们使用通过调整各个3D 3D点(即三角剖分或相交)得出的协方差信息扩展了它们。这不仅导致更好的收敛行为,而且避免了摆弄基于标准共识方法的惩罚参数。相应的新颖方法也可以看作是后方交集方案的一种变体,其中我们在交集期间调整子块的数量,这些子块与计算机上可用线程的数量直接相关,每个线程包含该块相机的一部分。我们展示了我们的新颖方法适用于健壮的并行束调整,并展示了其与基于基本共识方法以及束调整的最新并行执行方式相比的功能。 GitHub上提供了我们新颖方法的代码 |
| A Dataset of Multi-Illumination Images in the Wild Authors Lukas Murmann, Michael Gharbi, Miika Aittala, Fredo Durand 在单一不受控制的照明条件下收集图像已使诸如分类,检测和分割之类的核心计算机视觉任务得以快速发展。但是即使采用现代学习技术,涉及照明和材料理解的许多逆问题仍然病得很严重,以至于无法通过单个照明数据集解决。为了填补这一空白,我们引入了一个新的多照明数据集,其中包含1000多个真实场景,每个场景都是在25个光照条件下捕获的。我们通过训练三个具有挑战性的应用程序的最先进模型来证明此数据集的丰富性,这些应用程序包括单个图像照明估计,图像重新照明和混合光源白平衡。 |
| Fast Local Planning and Mapping in Unknown Off-Road Terrain Authors Timothy Overbye, Srikanth Saripalli 在本文中,我们提出了一种快速的在线制图和计划解决方案,用于未知,越野环境中的操作。我们将障碍物检测与地形梯度图结合在一起,以制作简单且可调整的成本图。可以以10 Hz的频率创建和更新该图。 A规划人员在地图上找到最佳路径。最后,我们在控制输入空间上进行多个采样,并进行运动学正演模拟以生成可行的轨迹。然后,选择由成本图和与A路径的接近程度确定的最佳轨迹,并将其发送给控制器。我们的方法允许以30 Hz的速率进行实时操作。我们证明了我们的方法在各种越野地形中的有效性。 |
| Texture Bias Of CNNs Limits Few-Shot Classification Performance Authors Sam Ringer, Will Williams, Tom Ash, Remi Francis, David MacLeod 鉴于少量的标记数据,准确的图像分类几乎没有镜头分类仍然是计算机视觉中的一个开放问题。在这项工作中,我们研究了卷积神经网络CNN的已知纹理偏差如何影响少数镜头分类性能。尽管纹理偏差可以帮助标准图像分类,但在这项工作中,我们证明了它严重损害了很少的镜头分类性能。在纠正了这种偏差之后,我们使用一种比目前性能最佳的少数镜头学习方法简单得多的方法,证明了竞争性miniImageNet任务的最新性能。 |
| Detecting intracranial aneurysm rupture from 3D surfaces using a novel GraphNet approach Authors Z. Ma, L. Song, X. Feng, G. Yang, W.Zhu, J. Liu, Y. Zhang, X. Yang, Y. Yin 颅内动脉瘤IA如果破裂并引起脑出血,则是威胁生命的人脑血斑。要检测IA是否已从医学图像破裂就具有挑战性。在本文中,我们提出了一种新颖的基于图形的神经网络GraphNet来从3D表面数据中检测IA破裂。 GraphNet基于图卷积网络GCN,设计用于图级别分类和节点级别分割。该网络使用GCN块来提取表面局部特征并汇集到全局特征。从诊所收集了1250例患者数据,包括385例破裂的IA和865例未破裂的IA。报告了随机选择的234位测试患者数据的表现。使用拟议的GraphNet进行的实验在分类任务中的接收器工作特性ROC曲线的曲线AUC下方的面积为0.82,准确度为0.82,在不使用基于图的网络的情况下明显优于基线方法。该模型的分割输出实现了基于均值图节点的骰子系数DSC得分0.88。 |
| SDCNet: Smoothed Dense-Convolution Network for Restoring Low-Dose Cerebral CT Perfusion Authors Peng Liu, Ruogu Fang 由于医学成像中累积的辐射暴露引起公众对潜在的癌症风险和健康危害的广泛关注,因此减少基于X射线的医学成像(例如计算机断层扫描灌注CTP)中的辐射剂量已引起了广泛的研究兴趣。在本文中,我们采用了基于深层卷积神经网络CNN的方法,并引入了平滑密集卷积神经网络SDCNet来从低剂量图像中恢复高剂量质量的CTP图像。 SDCNet由通过跳过连接级联的子网模块组成,以从成对的低高剂量CT扫描中推断出噪声差异。 SDCNet可以有效地消除真正的低剂量CT扫描中的噪声并提高医学图像的质量。我们在数千个CT灌注框架上对所提出的体系结构进行评估,以进行重建图像去噪和灌注图量化,包括脑血流CBF和脑血体积CBV。与最先进的方法相比,SDCNet在视觉和定量结果方面均具有出色的性能,并具有令人满意的计算效率。该代码可从url获得 |
| OpenDenoising: an Extensible Benchmark for Building Comparative Studies of Image Denoisers Authors Florian Lemarchand, Eduardo Fernandes Montesuma, Maxime Pelcat, Erwan Nogues 由于机器学习,图像去噪最近取得了飞跃。但是,图像去噪器,无论是基于专家还是基于学习的,都大多是针对行为良好的生成噪声(通常是高斯噪声)进行测试,而不是针对现实生活中的噪声进行测试,因此在现实世界中很难进行性能比较。对于基于学习的降噪器尤其如此,其性能取决于训练数据。因此,很难选择用于特定降噪问题的方法。 |
| Attention Mechanism Enhanced Kernel Prediction Networks for Denoising of Burst Images Authors Bin Zhang, Shenyao Jin, Yili Xia, Yongming Huang, Zixiang Xiong 基于深度学习的图像去噪方法已被广泛研究。本文提出了一种针对突发图像去噪的关注机制增强核预测网络AME KPN,其中,采用几乎免费的关注模块来首先细化特征图,并进一步充分利用帧间和帧内冗余在整个图像爆炸中。提出的AME KPN每像素空间自适应内核,残差图和相应权重图的输出,其中,预测内核通过自适应卷积运算将粗略像素恢复到其相应位置,然后对残差进行加权和求和以补偿有限预测内核的接受域。进行仿真和真实世界实验以说明所提出的AME KPN在突发图像去噪中的鲁棒性。 |
| Mirror Descent View for Neural Network Quantization Authors Thalaiyasingam Ajanthan, Kartik Gupta, Philip H. S. Torr, Richard Hartley, Puneet K. Dokania 由于内存和时间的减少,对于资源受限的设备,在保持性能的同时对大型神经网络NN进行量化非常合乎需要。 NN量化通常被公式化为一个约束优化问题,并通过梯度下降的修改版本进行优化。在这项工作中,通过将不受约束的连续参数解释为量化参数的对偶,我们引入了Mirror Descent MD框架Bubeck 2015用于NN量化。具体来说,我们在投影上提供了条件,即从连续投影到量化投影的映射,这将使我们能够导出有效的镜像映射,进而获得相应的MD更新。此外,我们通过存储另一组连续的辅助对偶变量来讨论MD的数值稳定实现。此更新非常类似于流行的基于直通估计器STE的方法,该方法通常被视为避免梯度消失的技巧,但在这里我们展示了它是针对某些投影的MD的一种实现方法。我们在具有卷积和残差架构的标准分类数据集CIFAR 10 100,TinyImageNet上进行的实验表明,我们的MD变体获得了完全量化的网络,其精度非常接近浮点网络。 |
| A Deep Learning-based Framework for the Detection of Schools of Herring in Echograms Authors Alireza Rezvanifar, Tunai Porto Marques, Melissa Cote, Alexandra Branzan Albu, Alex Slonimer, Thomas Tolhurst, Kaan Ersahin, Todd Mudge, Stephane Gauthier 跟踪水下物种的丰富度对于了解气候变化对海洋生态系统的影响至关重要。生物学家通常使用回声测深仪监测水下地点,并将数据可视化为2D图像回声图,他们以人工或半自动方式解释这些数据,这既耗时又容易出现不一致的情况。本文提出了一种深度学习框架,用于根据回波图自动检测鲱鱼。实验表明,我们的方法优于使用手工特征的传统机器学习算法。我们的框架可以轻松扩展,以发现更多可持续渔业感兴趣的物种。 |
| Bilinear Constraint based ADMM for Mixed Poisson-Gaussian Noise Removal Authors Jie Zhang, Yuping Duan, Yue Lu, Michael K. Ng, Huibin Chang 在本文中,我们为总变化正则化的小卷积电视IC模型提出了新的算子分裂算法,以消除混合的泊松高斯MPG噪声。在现有的电视集成电路分割算法中,一个非线性优化子问题必须采用牛顿法的内环,这增加了每个外环的计算成本。通过引入新的双线性约束并应用乘数ADMM的交替方向方法,可以非常有效地解决所提出算法的所有子问题,这些子问题分别是基于双线性约束的ADMM算法的BCA short和完全分解形式的BCA变体的BCAf short。对于建议的BCAf,无需任何内部迭代即可计算它们。在温和的条件下,对建议的BCA的收敛性进行了研究。在数值上,与现有的用于TV IC模型的原始对偶算法相比,所提出的算法具有更少的可调参数,收敛速度更快,同时产生可比的结果。 |
| Deep Sub-Ensembles for Fast Uncertainty Estimation in Image Classification Authors Matias Valdenegro Toro 许多健壮的机器人应用需要快速估计模型不确定性。 Deep Ensembles无需使用贝叶斯方法即可提供最先进的不确定性,但计算量仍然很大。在本文中,我们提出了深度子集成,它是深度集成的一种近似方法,其核心思想是仅对靠近输出的图层进行集成。我们的结果表明,这种想法可以在误差和不确定性质量与计算性能之间进行权衡。 |
| An Update on Machine Learning in Neuro-oncology Diagnostics Authors Thomas Booth 神经肿瘤学中的成像生物标志物用于诊断,预后和治疗反应监测。磁共振成像通常用于整个患者路径,因为常规的结构成像可提供详细的解剖和病理信息,而先进的技术则可提供其他生理细节。提取图像特征后,机器学习可以在各种情况下进行准确分类。机器学习还可以从头开始提取图像特征,尽管脑肿瘤的低患病率使这种方法具有挑战性。在患者首次出现脑肿瘤时,许多研究用于确定分子谱,组织学肿瘤分级和预后。治疗后,将治疗反应与治疗后相关效应区分开在临床上很重要,也是一个研究领域。多数证据是在单个中心回顾性获得的。 |
| Enforcing Linearity in DNN succours Robustness and Adversarial Image Generation Authors Anindya Sarkar, Nikhil Kumar Gupta, Raghu Iyengar 关于神经网络的对抗性脆弱性的最新研究表明,以最小化所有可能的对抗性扰动的最坏情况损失上限为目标而训练的模型,提高了对抗对抗性攻击的鲁棒性。除了利用对抗训练框架外,我们还表明,通过在转换后的输入和特征空间中强制将深度神经网络DNN线性化,可以显着提高鲁棒性。我们还证明,通过使用局部Lipschitz正则化器扩展目标函数,可以进一步提高模型的鲁棒性。我们的方法优于最先进的对抗训练方法,并在MNIST,CIFAR10和SVHN数据集上达到了最先进的对抗精度。在本文中,我们还利用对抗训练的深度神经网络分类器的逆表示学习和线性方面,提出了一种新颖的对抗图像生成方法。 |
| Mapper Based Classifier Authors Alexander Georges, David Meyer, Jacek Cyranka 拓扑数据分析旨在从数据中提取拓扑量,这些拓扑量往往侧重于数据的更广泛的全局结构,而不是本地信息。具体地说,Mapper方法概括了聚类方法,以识别重要的全局数学结构,这是许多其他方法无法实现的。我们基于将Mapper算法应用于投影到潜在空间的数据,提出了一种分类器。我们通过使用PCA或自动编码器获得潜在空间。值得注意的是,基于Mapper方法的分类器不受任何基于梯度的攻击的影响,并且比传统的CNN卷积神经网络提高了鲁棒性。我们报告理论依据和一些数值实验证实了我们的主张。 |
| Chinese Abs From Machine Translation |


{kind=link}