AI视野·今日CS.CV 计算机视觉论文速览
Fri, 18 Oct 2019
Totally 30 papers
?上期速览✈更多精彩请移步主页

Interesting:
?****医学图像语义分割综述, (from Mila NeuroPoly Lab 蒙特利尔)
?基于自监督的单图像视角获取和外形重建模型, (from 弗莱堡大学)
实验得到的位姿分布:

?机器人躲猫猫, (from 哥伦比亚大学 )

基于Unity游戏引擎、ML-Agents、Pytorch
code:http://www.cs.columbia.edu/~bchen/visualhideseek/
?使用了Context Less-Aware的RGBD个体分割, (from SJTU)

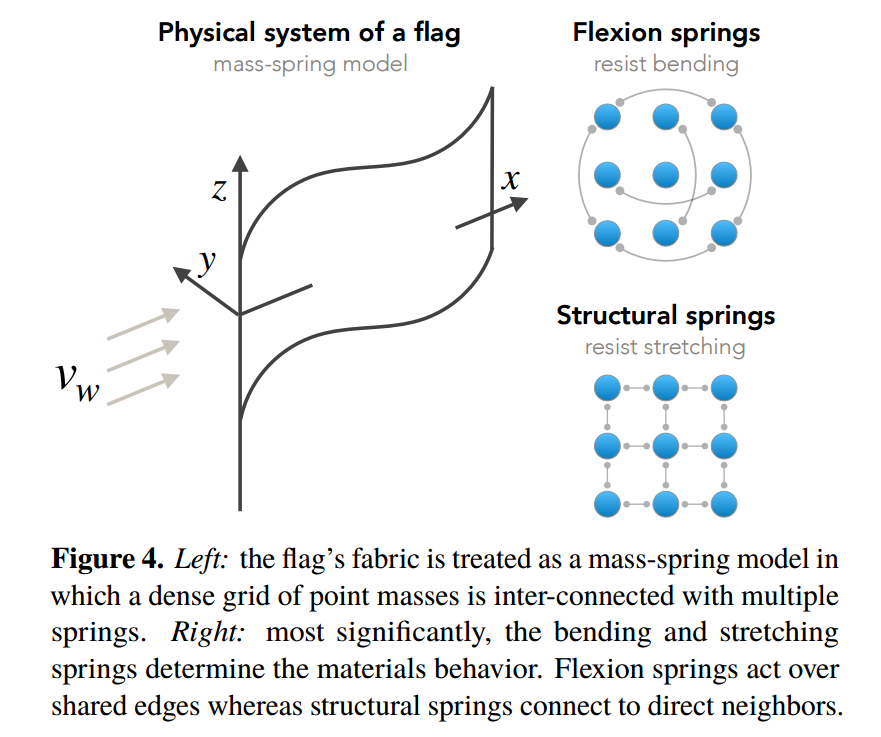
?基于感知的物理模型获取,通过观测对仿真结果进行监督来更新物理模型参数, (from QUVA Deep Vision Lab阿姆斯特丹大学)

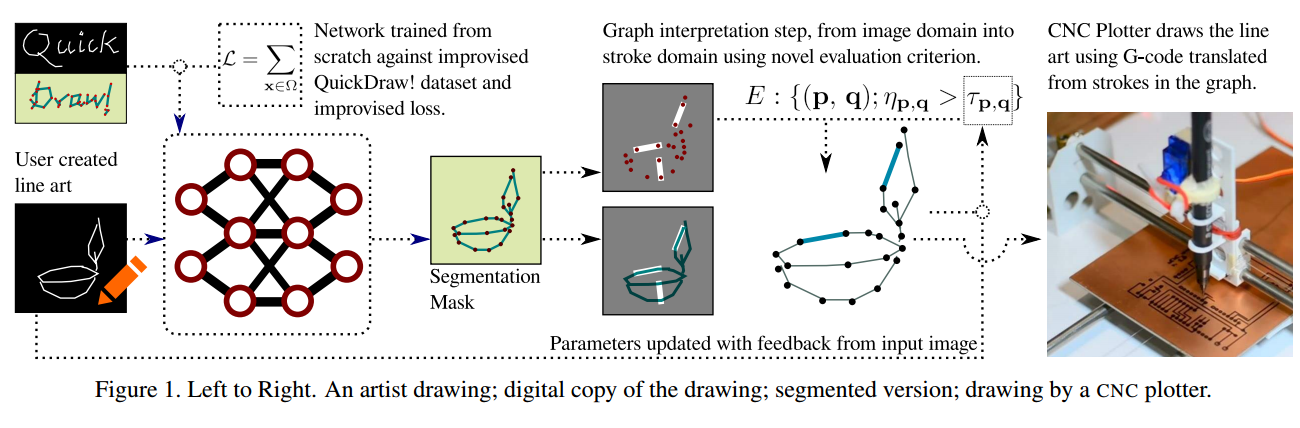
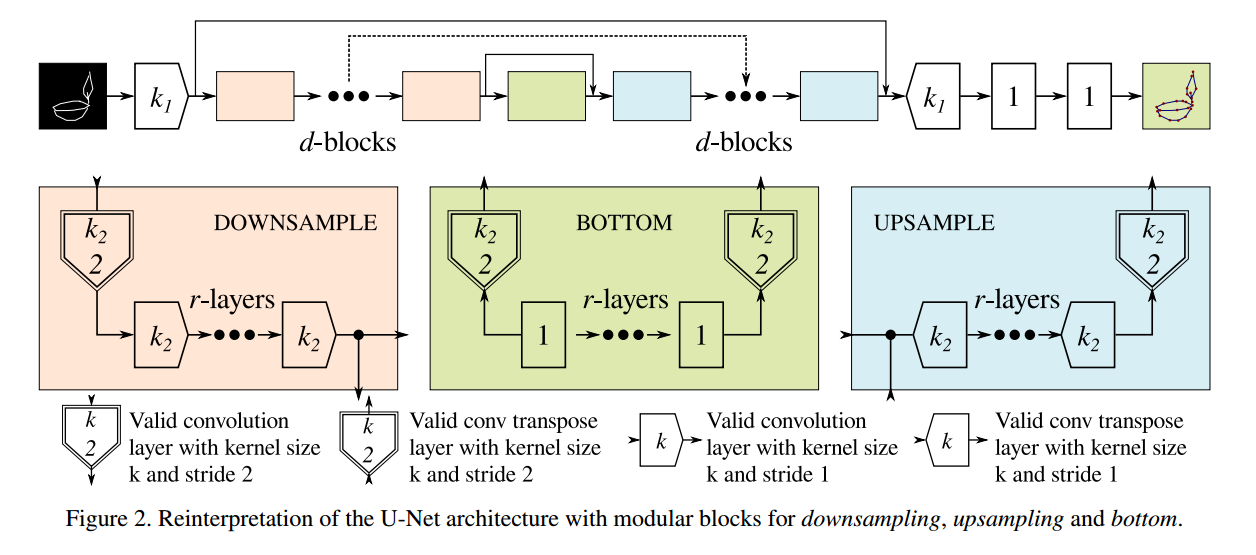
?教机器人画画, (from Indian Institute of Technology Kanpur)
Daily Computer Vision Papers
| Context-Aware Saliency Detection for Image Retargeting Using Convolutional Neural Networks Authors Mahdi Ahmadi, Nader Karimi, Shadrokh Samavi 图像重新定向是使图像能够显示在不同尺寸的屏幕上的任务。应当进行这项工作,以使高级视觉信息和低级特征(例如纹理)对人类视觉系统保持尽可能完整,而输出图像可能具有不同的尺寸。因此,简单的方法(例如缩放和修剪)不足以实现此目的。近年来,研究人员试图改进现有的重新定向方法并引入新的方法。但是,不能使用特定方法来重新定位所有类型的图像。换句话说,不同的图像需要不同的重定目标方法。图像重新定向与图像显着性检测有着密切的关系,而图像显着性检测是相对较新的图像处理任务。较早的显着性检测方法是基于局部和全局但低级图像信息。这些方法称为自下而上的方法。另一方面,较新的方法是自顶向下的混合方法,这些方法也考虑了图像的高级信息和语义信息。在本文中,我们介绍了在显着性检测和重新定向中提出的方法。对于显着性检测,研究了图像上下文和语义分割的使用,并提出了一种新的自下而上和自上而下的显着性混合检测方法。在显着性检测之后,利用现有重定向方法的修改版本对图像进行重定向。结果表明,与其他测试方法相比,所提出的图像重新定向管道具有出色的性能。此外,对Pascal数据集的主观评估可以用作重新定位质量评估数据集以进行进一步研究。 |
| Meta-learning for fast classifier adaptation to new users of Signature Verification systems Authors Luiz G. Hafemann, Robert Sabourin, Luiz S. Oliveira 脱机手写签名验证提出了一个具有挑战性的模式识别问题,其中仅正面课程的知识可用于培训。虽然分类者可以使用一些真实的签名进行训练,但在泛化期间,他们还需要区分伪造品。对于熟练的伪造而言,这尤其具有挑战性,在伪造中,伪造者练习模仿用户的签名,并且通常能够在视觉上创建接近原始签名的伪造。文献中的大多数工作都是通过训练替代目标来区分用户的真实签名和其他用户的随机伪造签名来解决此问题的。在这项工作中,我们提出了一个基于元学习的解决方案,其中有两个学习任务级别的层次,其中一个任务是学习给定用户的分类器,一个跨任务学习的元层次。特别地,元学习器为每个用户指导分类器的适应性学习,这是仅需要真实签名的轻量级操作。元学习过程可了解不同用户之间进行分类的共同点。在来自用户子集的熟练伪造可用的情况下,即使分类器本身不使用熟练伪造进行学习,元学习者也可以指导分类器区分熟练伪造。在GPDS 960数据集上进行的实验表明,与独立于书写器的系统相比,性能有所提高,并且在每用户5个样本签名很少的情况下,可达到与先进的与书写器相关的系统相当的结果。 |
| Video Person Re-Identification using Learned Clip Similarity Aggregation Authors Neeraj Matiyali, Gaurav Sharma 我们解决了基于视频的人员识别的艰巨任务。最近的工作表明,将视频序列分成片段,然后基于片段的相似度进行聚合适合该任务。我们表明,使用学习的片段相似度聚合功能可以过滤出硬片段对,例如无法清楚看到该人的位置,具有挑战性的姿势或两个剪辑中的姿势差异太大而无法提供信息的位置。这使得该方法可以专注于对任务更具信息性的剪辑对。我们还介绍了将3D CNN用于基于视频的重新识别的方法,并通过执行与以前的工作等效的方法来显示其效果,这些工作除了使用RGB输入外还使用了光流,而仅使用RGB输入。我们根据三个具有挑战性的公共基准给出定量结果,并显示出更好或具有竞争力的表现。我们还定性地验证了我们的方法。 |
| Discrete Residual Flow for Probabilistic Pedestrian Behavior Prediction Authors Ajay Jain, Sergio Casas, Renjie Liao, Yuwen Xiong, Song Feng, Sean Segal, Raquel Urtasun 自动驾驶汽车围绕静态和动态物体进行规划,应用行为的预测模型来估计物体在环境中的未来位置。但是,未来的行为本质上是不确定的,并且产生确定性输出的运动模型仅限于较短的时间范围。预测人类行为尤其困难。在这项工作中,我们提出了离散残差流网络DRF Net,这是一种用于人类运动预测的卷积神经网络,可捕获远程运动预测中固有的不确定性。特别是,我们的学习网络通过预测和更新空间位置上的离散分布,有效地捕获了未来人类运动的多模式后验。我们将我们的模型与几个强大的竞争对手进行了比较,并表明我们的模型优于所有基准。 |
| Convolutional Character Networks Authors Linjie Xing, Zhi Tian, Weilin Huang, Matthew R. Scott 在开发用于在自然图像中进行联合文本检测和识别的统一框架方面,最近取得了进展,但是现有的联合模型主要是通过涉及ROI合并在两个阶段的框架上构建的,这会降低识别任务的性能。在这项工作中,我们提出了卷积字符网络,称为CharNet,这是一个单阶段模型,可以一次处理两个任务。 CharNet直接输出单词和字符的边界框以及相应的字符标签。我们将字符作为基本元素,从而使我们能够克服现有方法的主要困难,这些方法试图与基于RNN的识别分支一起优化文本检测。此外,我们开发了一种迭代字符检测方法,该方法可以将从合成数据中学到的字符检测功能转换为现实世界图像。这些技术改进产生了一个简单,紧凑但功能强大的一级模型,该模型可以可靠地在多方向和弯曲文本上运行。我们在三个标准基准上对CharNet进行了评估,它们在总体上始终领先于最新方法25、24,例如,在ICDAR 2015上使用通用词典改进了65.33 71.08,在Total Text上最终改进了54.0 69.23。结束文字识别。代码位于 |
| Go with the Flow: Perception-refined Physics Simulation Authors Tom F.H. Runia, Kirill Gavrilyuk, Cees G.M. Snoek, Arnold W.M. Smeulders 对于我们周围的许多物理现象,我们开发了复杂的模型来解释它们的行为。然而,由于存在大量因果关系的物理参数(包括材料属性和外力),因此从视觉观察中推断具体细节是一项挑战。本文讨论了从观察结果推断这种潜在物理性质的问题。我们的解决方案是一个以仿真为核心的迭代优化程序。该算法通过运行观察到的现象的模拟并将当前模拟与真实世界的观察进行比较,从而逐步更新物理模型参数。使用嵌入函数计算物理相似度,该函数将物理相似的示例映射到附近的点。作为一个明显的例子,我们将注意力集中在随风飘扬的旗帜上,这是一种看似简单的现象,但在物理上却非常复杂。基于其潜在的物理模型和视觉表现,我们提出了嵌入功能的实例化。对于建模为深层网络的这种映射,我们引入了一个频谱分解层,该层将视频量分解为其时间频谱功率和相应的频率。在实验中,我们证明了我们的方法能够从模拟和真实世界的视频中恢复内部和外部物理参数的能力。 |
| Can I teach a robot to replicate a line art Authors Raghav Brahmadesam Venkataramaiyer, Subham Kumar, Vinay P. Namboodiri 艺术线条可以说是基本的,通用的表达方式之一。我们为机器人提出了一种管线,以查看灰度线条并进行重画。我们管道的主要新颖元素是a我们提出了模仿线条图的新任务,b解决了管道我们修改了Quick draw数据集以获得将线条图转换为一系列笔画的监督训练c我们提出了一个多阶段分割和图形解释管道来解决问题。生成的方法也已部署在CNC绘图仪和机械臂上。我们已经训练了所提出方法的几种变体,并在从Quick draw获得的数据集上进行了评估。通过最好的方法,我们观察到此任务的准确性约为98,这比我们改编的基准体系结构显着改善。因此,这允许将方法部署在机器人上以可靠的方式复制线条。我们还表明,尽管基于规则的矢量化方法足以满足简单图形的需要,但对于更复杂的草图却无法实现,这与我们的方法可以将其很好地推广到更复杂的分布不同。 |
| NAMF: A Non-local Adaptive Mean Filter for Salt-and-Pepper Noise Removal Authors Houwang Zhang, Chong Wu, Hanying Zheng, Le Zhang 本文提出了一种非局部自适应均值滤波器NAMF,它可以消除所有水平的盐和胡椒SAP噪声。 NAMF可以分为两个阶段1 SAP噪声检测2 SAP噪声消除。对于给定的像素,首先,将其与噪点图像的最大或最小灰度值进行比较,如果等于,则使用具有自适应大小的窗口进一步确定其是否有噪点,并且将保留无噪点像素。其次,噪声像素将被其相邻像素的组合所代替。最后,我们使用基于SAP噪声的非局部均值滤波器来进一步恢复它。我们的实验结果表明,在所有SAP噪声水平下,NAMF的图像质量均优于最新方法。 |
| Detecting Urban Changes with Recurrent Neural Networks from Multitemporal Sentinel-2 Data Authors Maria Papadomanolaki, Sagar Verma, Maria Vakalopoulou, Siddharth Gupta, Konstantinos Karantzalos 摘要像Copernicus Sentinel 2这样的多时间高分辨率数据的出现大大增强了监视地球表面和环境动力学的潜力。在本文中,我们提出了一种新颖的深度学习框架,用于城市变化检测,该框架结合了类似于U Net的先进全卷积网络(用于特征表示)和强大的递归网络(如LSTM)用于时间建模。我们在最近公开提供的双时间Onera卫星变化检测OSCD前哨2数据集上报告了我们的结果,从而利用不同日期的相同区域的其他图像增强了时间信息。此外,我们使用整体交叉验证策略评估循环网络的性能以及在看不见的测试集上使用其他日期。在验证阶段,所有开发的模型的总体准确度均超过95,而LSTM和更多时间信息的使用将变更类别的F1率提高了1.5。 |
| On the Reliability of Cancelable Biometrics: Revisit the Irreversibility Authors Xingbo Dong, Zhe Jin, Andrew Beng Jin Teoh, Massimo Tistarelli, KokSheik Wong 多年来,已经提出了许多主要基于可取消生物特征的生物特征模板保护方案。可取消的生物特征算法需要满足四个生物特征模板保护标准,即不可逆性,可撤销性,不可链接性和性能保持。但是,对不可逆性的系统分析经常被忽略。在本文中,分析了可取消生物识别技术的常见距离相关特性。接下来,在Kerckhoffs假设下制定了基于相似度的攻击,以打破可取消生物特征的不可逆性,在这种假设下,攻击者知道可取消生物特征的算法和参数。还重新定义了基于互信息的不可逆性,并提出了一种基于距离相关特性来度量信息泄漏的框架。在面部,虹膜和指纹上获得的结果证明,从理论上讲很难满足完全的不可逆性。为了拥有一个良好的生物识别系统,必须在准确性和安全性之间取得平衡。 |
| Making Third Person Techniques Recognize First-Person Actions in Egocentric Videos Authors Sagar Verma, Pravin Nagar, Divam Gupta, Chetan Arora 我们专注于以自我为中心的视频进行的第一人称动作识别。与第三人称领域不同,研究人员将第一人称动作分为涉及手对象交互的类别和没有涉及对象互动的类别,并针对这两种动作类别开发了单独的技术。此外,已经有人争论,用于第三人称动作识别的传统线索是不够的,并且以自我为中心的特定特征,例如头部动作和被处理的物体已经被用于这种动作。与现有技术不同,我们表明具有长短期记忆LSTM架构的常规两流卷积神经网络CNN具有针对对象和运动的独立流,可以推广到所有第一人称动作类别。所提出的方法统一了所有动作类别所学习的功能,从而使所提出的体系结构更加实用。在一个重要的观察中,我们注意到以自我为中心的视频中可见的对象的大小要小得多。我们表明,在裁剪和调整框架大小以使对象的大小与ImageNet的对象大小可比之后,所提出模型的性能得以提高。我们对标准数据集GTEA,EGTEA Gaze,HUJI,ADL,UTE和Kitchen进行的实验证明,我们的模型明显优于各种最新技术。 |
| Deep Contextual Attention for Human-Object Interaction Detection Authors Tiancai Wang, Rao Muhammad Anwer, Muhammad Haris Khan, Fahad Shahbaz Khan, Yanwei Pang, Ling Shao, Jorma Laaksonen 人体对象交互检测是一种重要的且相对较新的视觉关系检测任务,对于更深入的场景理解至关重要。大多数现有的方法将问题分解为对象定位和交互识别。尽管取得了进展,但这些方法仅依靠人和物体的外观,而忽略了可用的上下文信息,这对于捕获它们之间的微妙交互至关重要。我们提出了一个用于人类对象交互检测的上下文关注框架。我们的方法通过学习人和对象实例的上下文感知外观特征来利用上下文。提出的注意力模块然后自适应地选择相关的以实例为中心的上下文信息,以突出显示可能包含人类对象交互的图像区域。实验在三个基准V COCO,HICO DET和HCVRD上进行。我们的方法在所有数据集上的表现均优于最新技术。在V COCO数据集上,与现有最佳方法相比,我们的方法在角色平均平均精度mAP角色方面实现了4.4的相对增益。 |
| Cross Attention Network for Few-shot Classification Authors Ruibing Hou, Hong Chang, Bingpeng Ma, Shiguang Shan, Xilin Chen 很少有镜头分类的目的是在仅标记了几个样本的情况下,从看不见的类别中识别出未标记的样本。看不见的类别和数据不足问题使很少的镜头分类非常具有挑战性。许多现有方法都是独立地从标记和未标记的样本中提取特征,因此,这些特征还没有足够的区分性。在这项工作中,我们提出了一个新颖的交叉注意网络,以解决少数镜头分类中的难题。首先,引入交叉注意模块来处理看不见的类问题。该模块为每对类特征和查询样本特征生成交叉注意图,以突出显示目标对象区域,从而使提取的特征更具区分性。其次,提出了一种转导推理算法来缓解低数据问题,该算法反复利用未标记的查询集来增加支持集,从而使类特征更具代表性。在两个基准上进行的大量实验表明,我们的方法是一种简单,有效且计算效率高的框架,其性能优于现有技术。 |
| Wasserstein Distance Guided Cross-Domain Learning Authors Jie Su 域适应旨在通过利用来自源域丰富的标签数据的知识(来自不同但相关的分布),在目标域非标签数据上推广高性能学习者。假设源域和目标域数据例如图像来自联合分布,但遵循不同的边际分布,域自适应工作旨在从源域和目标域推断联合分布,以学习域不变特征。因此,在这项研究中,我扩展了现有技术水平的方法来解决域自适应问题。特别是,我提出了一种从不同分布推断图像联合分布的新方法,即Wasserstein距离引导跨域学习WDGCDL。 WDGCDL应用Wasserstein距离来估计源分布和目标分布之间的差异,这提供了良好的梯度性质和有希望的泛化边界。此外,为了解决所提出框架的培训困难,我提出了两种不同的培训方案来进行稳定的培训。定性结果表明,这种新方法优于标准域自适应基准中的现有技术。 |
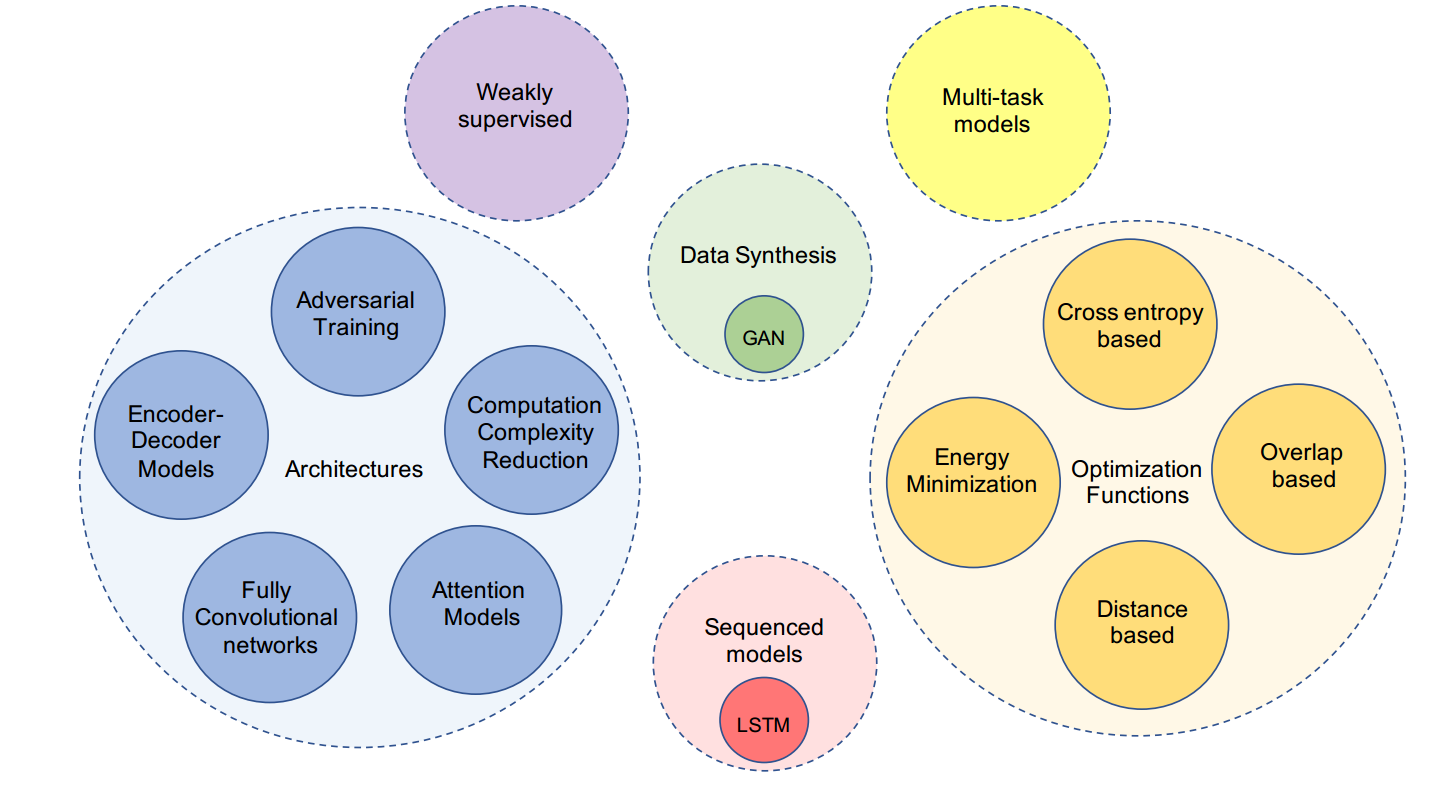
| Deep Semantic Segmentation of Natural and Medical Images: A Review Authors Saed Asgari Taghanaki, Kumar Abhishek, Joseph Paul Cohen, Julien Cohen Adad, Ghassan Hamarneh 医学图像语义分割任务包括将图像的每个像素或仅几个像素分类为一个实例,其中每个实例或类别对应一个类。此任务是场景理解概念的一部分,或者更好地解释图像的全局上下文。在医学图像分析领域,图像分割可用于图像引导干预,放射疗法或改进的放射学诊断。在这篇综述中,我们将基于深度学习的主要医学和非医学图像分割解决方案分为六大类,分别是深度架构改进,基于数据综合,基于损失函数的改进,排序模型,弱监督和多任务方法,以及每种方法的进一步分类我们分析了这些组的每个变体,并讨论了语义图像分割的当前方法和未来研究方向的局限性。 |
| RGB-D Individual Segmentation Authors Wenqiang Xu, Yanjun Fu, Yuchen Luo, Chang Liu, Cewu Lu 细粒度识别任务处理子类别分类问题,这对于实际应用很重要。在这项工作中,我们对Emph最细粒度的细分任务特别感兴趣,该细分任务专门称为个人细分。换句话说,个人级别类别下没有子类别。个体层面的分割问题揭示了一些新特性,单个个体对象的训练数据有限,背景未知以及深度使用困难。为了解决这些新问题,我们提出了一种上下文无关的CoLA管道,该管道可生成具有较少背景上下文的RGB D对象为主的图像,并能够使用3D信息进行规模感知的训练和测试。大量实验表明,所提出的CoLA策略在性能上大大优于YCB视频数据集和我们提出的Supermarket 10K数据集的基线方法。代码,训练有素的模型和新的数据集将与本文一起发布。 |
| A Combined Deep Learning-Gradient Boosting Machine Framework for Fluid Intelligence Prediction Authors Yeeleng S. Vang, Yingxin Cao, Xiaohui Xie ABCD神经认知预测挑战赛是一项由社区推动的竞赛,要求参赛者开发从T1 w MRI预测流体智力得分的算法。在这项工作中,我们提出了结合梯度提升机框架的深度学习来解决此任务。我们训练卷积神经网络来压缩高维MRI数据,并通过预测每个MRI提供的123个连续值的派生数据来学习有意义的图像特征。然后将这些提取的特征用于训练可预测残留流体智能得分的梯度增强机。对于训练,验证和测试集,我们的方法分别获得了18.4374、68.7868和96.1806的均方误差MSE评分。 |
| Global Saliency: Aggregating Saliency Maps to Assess Dataset Artefact Bias Authors Jacob Pfau, Albert T. Young, Maria L. Wei, Michael J. Keiser 在机器学习模型的高风险应用中,可解释性方法可确保模型因正确的原因而正确。在医学成像中,显着图已成为确定神经模型是否已学会相关健壮特征而非人工噪声的标准工具。但是,显着图仅限于局部模型解释,因为它们会逐个图像地解释预测。我们建议使用语义分割掩码在全球范围内汇总显着性,以提供整个数据集中模型偏差的定量度量。为了评估全局显着性方法,我们提出了两个指标来量化显着性解释的有效性。我们将全局显着性方法应用于皮肤病变诊断,以确定诸如油墨等伪影对模型偏差的影响。 |
| Instance adaptive adversarial training: Improved accuracy tradeoffs in neural nets Authors Yogesh Balaji, Tom Goldstein, Judy Hoffman 到目前为止,对抗训练是提高神经网络对对抗攻击的鲁棒性的最成功策略。尽管对抗训练取得了成功,但对抗训练却无法很好地推广到不受干扰的测试系统。我们假设这种较差的概括性是对抗训练的结果,该训练在每个训练样本周围均具有统一的摄动半径。在很小的扰动预算下,接近决策边界的样本可以变成不同的类别,并且在这些样本周围强制使用较大的边距会产生差的决策边界,从而导致泛化能力差。受此假设的启发,我们提出了实例自适应对抗训练技术,该技术可在每个训练样本周围实施样本特定的扰动余量。我们表明,使用我们的方法,在不受干扰的样本上的测试准确性会随着鲁棒性的下降而提高。在CIFAR 10,CIFAR 100和Imagenet数据集上的大量实验证明了我们提出的方法的有效性。 |
| Adaptive Curriculum Generation from Demonstrations for Sim-to-Real Visuomotor Control Authors Lukas Hermann, Max Argus, Andreas Eitel, Artemij Amiranashvili, Wolfram Burgard, Thomas Brox 我们建议从演示ACGD中生成自适应课程,以在存在稀疏奖励的情况下进行强化学习。 ACGD不是设计形状的奖励函数,而是通过控制从演示轨迹的采样位置以及要使用的仿真参数集来自适应地为学习者设置适当的任务难度。我们表明,在模拟中训练基于视觉的控制策略,同时通过ACGD逐渐增加任务的难度,可以改善向现实世界的策略转移。通过任务难度,域随机化程度也逐渐提高。我们演示了针对两个现实世界中的操纵任务拾取,存放和块堆叠的零击转移。 |
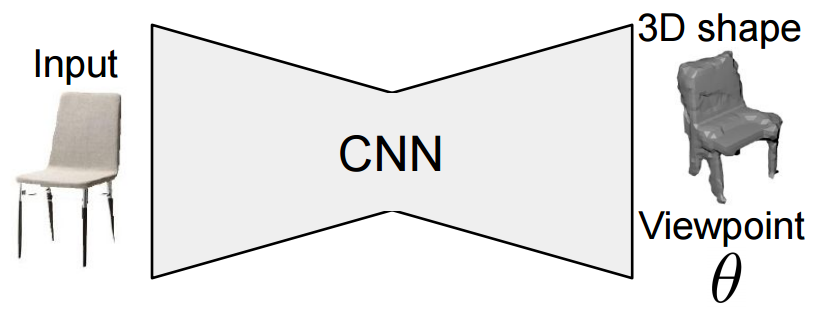
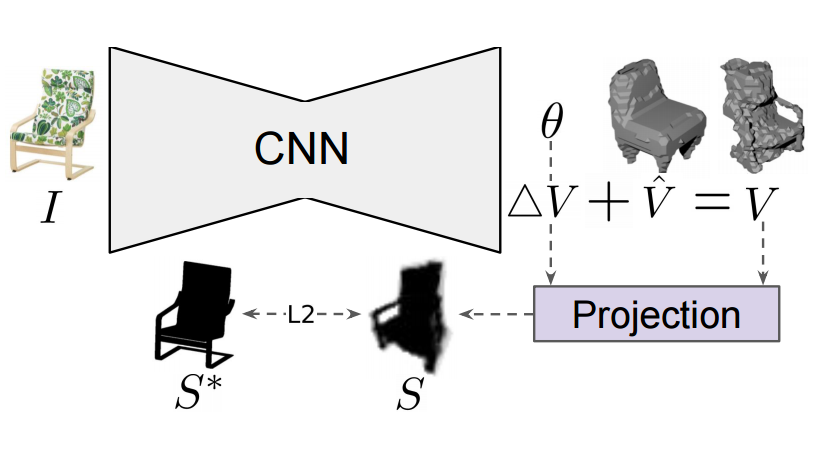
| Self-supervised 3D Shape and Viewpoint Estimation from Single Images for Robotics Authors Oier Mees, Maxim Tatarchenko, Thomas Brox, Wolfram Burgard 我们提出了用于从单个输入图像进行联合3D形状预测和视点估计的卷积神经网络。在训练期间,我们的网络从输入图像中的对象轮廓中获取学习信号,这是一种自我监督的形式。对于3D形状和视点,它不需要地面真实数据。因为它依赖于这种薄弱的监管形式,所以我们的方法可以轻松地应用于现实世界的数据。我们证明,我们的方法在形状估计和视点预测的自然图像上产生合理的定性和定量结果。与以前的方法不同,我们的方法不需要数据集中同一对象实例的多个视图,这大大扩展了在实际机器人场景中的适用性。我们通过使用幻觉形状来展示它,以提高在仿真和PR2机器人中抓取现实世界对象的性能。 |
| A New Three-stage Curriculum Learning Approach to Deep Network Based Liver Tumor Segmentation Authors Huiyu Li, Xiabi Liu, Said Boumaraf, Weihua Liu, Xiaopeng Gong, Xiaohong Ma 医学图像中肝肿瘤的自动分割对于计算机辅助诊断和治疗至关重要。这是一项具有挑战性的任务,因为相对于背景体素而言,肿瘤非常小。本文提出了一种新的三阶段课程学习方法,用于训练深度网络以解决此小对象分割问题。在第一阶段的学习是在整个输入上进行的,以获得用于肿瘤分割的初始深层网络。然后,第二阶段的学习通过继续在肿瘤斑块上训练网络,着重增强肿瘤特定特征的强度。最后,我们在第三阶段对整个输入进行重新训练,以便可以在分割目标下理想地整合肿瘤的特定特征和整体情况。受益于所提出的学习方法,我们只需要采用一个单一的网络就可以直接分割肿瘤。我们在2017年MICCAI肝肿瘤分割挑战数据集上评估了我们的方法。在实验中,与常用的级联方法相比,我们的方法显示出显着的改进。 |
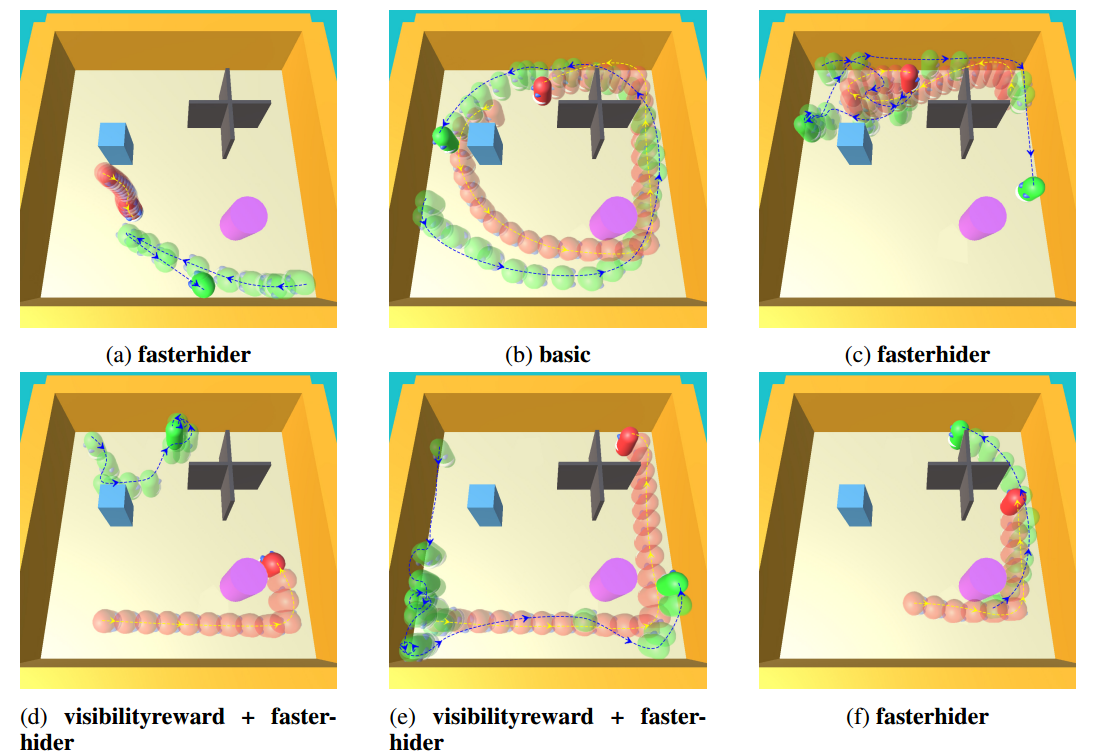
| Visual Hide and Seek Authors Boyuan Chen, Shuran Song, Hod Lipson, Carl Vondrick 我们训练有经验的特工玩“视觉捉迷藏”,在这种情况下,猎物必须在模拟环境中导航,以避免被捕食者捕获。我们在环境中放置各种障碍,以使猎物躲在后面,并且我们仅使用自我中心的视角为代理提供对其环境的部分观察。尽管我们训练模型从头开始玩这个游戏,但是实验和可视化显示该代理学会了预测自己在环境中的可见性。此外,我们定量分析了代理弱点(例如速度较慢)如何影响学习的策略。我们的结果表明,尽管代理弱点使学习问题更具挑战性,但它们也会导致学习更多有用的功能。我们的项目网站位于: |
| Introducing Hann windows for reducing edge-effects in patch-based image segmentation Authors Nicolas Pielawski, Carolina W hlby 可以使用诸如图像处理等计算要求高的方法来处理的图像的尺寸存在限制。卷积神经网络CNNs。一些成像方式,尤其是生物学和医学成像方式,可能会导致图像大小达到几千兆像素,这意味着必须将其分成较小的部分或小块进行处理。然而,当执行图像分割时,这可能导致不期望的伪像,例如最终的重新组合图像中的边缘效应。我们从信号处理中引入开窗方法,以有效减少此类边缘效应。假设图像补丁的中心部分通常比其侧面和角落拥有更丰富的上下文信息,我们通过重叠依赖于二维窗口加权的补丁来重建预测。我们比较了四个不同的Hann,Bartlett Hann,Triangular窗口以及Cui等人最近提出的窗口的结果,结果表明,基于余弦的Hann窗口通过结构相似性指数SSIM测得的效果最佳。所提出的加窗方法可以与任何CNN模型一起用于分割,而无需进行任何修改,并且可以显着改善网络预测。 |
| Organ At Risk Segmentation with Multiple Modality Authors Kuan Lun Tseng, Winston Hsu, Chun ting Wu, Ya Fang Shih, Fan Yun Sun 随着计算机视觉中图像分割技术的发展,生物医学图像分割技术在脑肿瘤分割和器官风险OAR分割方面取得了显着进展。但是,大多数研究仅使用诸如计算机断层扫描CT扫描之类的单一方式,而在现实世界中,医生通常使用多种方式来获得更准确的结果。为了更好地利用不同的方式,我们收集了一个由136例CT和MR图像诊断为鼻咽癌的大型数据集。在本文中,我们建议使用生成对抗网络执行CT到MR转换以合成MR图像,而不是将两种方式对齐。合成的MR可以与CT一起训练以获得更好的性能。此外,我们使用实例分割模型来扩展OAR分割任务,以分割器官和肿瘤区域。收集的数据集将很快公开。 |
| Annealed Denoising Score Matching: Learning Energy-Based Models in High-Dimensional Spaces Authors Zengyi Li, Yubei Chen, Friedrich T. Sommer 基于能量的模型EBM在给定数据样本的情况下输出未标准化的对数概率值。这种估计在各种应用中至关重要,例如样本生成,去噪,样本恢复,离群值检测,贝叶斯推理等。但是,由于需要对模型分布进行采样,因此标准最大似然训练的计算量很大。分数匹配可能会缓解此问题,降噪分数匹配是一个特别方便的版本。但是,以前的工作无法通过随机初始化在高维数据集中生成能够进行高质量样本合成的模型。我们认为这是因为分数仅在单个噪声标度上匹配,这对应于高维空间中的一小部分。为了克服此限制,在这里,我们改为在所有噪声标度上使用降噪得分匹配来学习能量函数。当使用退火的Langevin动力学和单步降噪跳跃从随机初始化中采样时,我们的模型会产生可与GAN等最新技术媲美的高质量样本。学习的模型还提供密度信息,并在基于能量的模型中设置新的样品质量基线。我们进一步证明了所提出的方法可以很好地概括图像修复任务。 |
| A Parametric Perceptual Deficit Modeling and Diagnostics Framework for Retina Damage using Mixed Reality Authors Prithul Aniruddha, Nasif Zaman, Alireza Tavakkoli, Stewart Zuckerbrod 与年龄相关的黄斑变性AMD是一种累及数百万个体的进行性视力障碍。由于目前尚无该疾病的治疗方法,因此改善患有该疾病的人的生活的唯一方法是通过辅助技术。在本文中,我们提出了一种新颖有效的方法,可以针对由AMD引起的患者视网膜生理退化所引起的知觉缺陷准确生成参数模型。基于模型的参数,开发了一种机制来模拟患者因疾病而产生的感知。这种模拟可以有效地将感知的影响及其进展传递给患者的眼科医生。此外,我们提出了一种混合现实的设备和界面,以使患者恢复功能性视力并补偿由于生理损伤而引起的知觉丧失。通过提议的方法获得的结果表明,我们的框架优于最新的低视力系统。 |
| CFEA: Collaborative Feature Ensembling Adaptation for Domain Adaptation in Unsupervised Optic Disc and Cup Segmentation Authors Peng Liu, Bin Kong, Zhongyu Li, Shaoting Zhang, Ruogu Fang 最近,在标注正确的数据集中,深层神经网络已证明与董事会认证的眼科医生具有可比甚至更好的性能。但是,视网膜成像设备的多样性带来了很大的挑战领域转移,这在将深度学习模型应用于新的测试领域时会导致性能下降。在本文中,我们提出了一种新型的无监督域自适应框架,称为协作特征集合自适应CFEA,以有效克服这一挑战。我们提出的CFEA是一种交互式范例,通过对抗性学习和综合权重呈现出精巧的协作适应。特别是,我们同时实现了领域不变性,并保持了历史预测的指数移动平均值,从而通过训练过程中的权重对未标记数据实现了更好的预测。在不注释来自目标域的任何样本的情况下,编码器和解码器层中的多个对抗损失指导域不变特征的提取,以混淆域分类器,同时有利于平滑权重的组合。全面的实验结果表明,我们的CFEA模型可以克服性能下降,并且在从眼底图像分割视网膜视盘和视盘方面优于现有方法。网址中提供了textit代码 |
| Optimal Transport Based Generative Autoencoders Authors Oliver Zhang, Ruei Sung Lin, Yuchuan Gou 生成对抗网络GAN主导着深度生成建模领域。但是,GAN的训练通常缺乏稳定性,无法收敛,并且遭受模型崩溃的困扰。解决这些问题需要各种技巧,对于寻求应用生成建模的人来说可能很难理解。相反,我们提出了两种新颖的生成自动编码器,AE OTtrans和AE OTgen,它们依赖于最佳传输方式而不是对抗训练。与VAE和WAE不同,AE OTtrans和AEOTgen保留了数据的多种形式,它们不会强制潜伏分布与正态分布匹配,从而获得了更高质量的图像。与其前身AE OT相比,AEOTtrans和AE OTgen还可以产生更高多样性的图像。我们显示,在MNIST和FashionMNIST数据集中,AE OTtrans和AE OTgen超过GAN。此外,我们表明AE OTtrans和AE OTgen在MNIST,FashionMNIST和CelebA图像集上具有与其他非对抗性生成模型共同映射的最新技术。 |
| Conditional Driving from Natural Language Instructions Authors Junha Roh, Chris Paxton, Andrzej Pronobis, Ali Farhadi, Dieter Fox 无人驾驶汽车的广泛采用不仅取决于其安全性,而且在很大程度上取决于其与人类用户互动的能力。就像人类驾驶员一样,自动驾驶汽车将能够理解并安全地遵循自然语言的指示,这些指示会根据用户的喜好或存在歧义而突然改变预先计划的路线,特别是在地图覆盖范围较差或过时的地方。为此,我们提出了一种基于语言的驾驶代理,该代理使用递归层和门控注意力来实现分层策略。分层方法使我们能够根据描述长时间视野的高级语言指令和实时控制自动驾驶汽车所需的低级,复杂,连续状态动作空间进行推理。我们从有条件的模仿学习中训练我们的政策,这些学习是从人类驾驶员和导航员那里收集的真实语言数据中进行的。通过在CARLA框架内进行定量和交互式实验,我们证明了我们的模型可以成功解释语言指令并安全地遵循它们,即使推广到以前看不见的环境中也是如此。可以在以下位置找到代码和视频 |
| Chinese Abs From Machine Translation |


{kind=link}