AI视野·今日CS.CV 计算机视觉论文速览
Fri, 27 Sep 2019
Totally 55 papers
?上期速览✈更多精彩请移步主页

Interesting:
TODO(rjj): details of1-2
?Learned-PCGC点云几何压缩算法, 提出了一种基于变分自编码对点云几何PCG进行有效压缩的方法。(from 南京大学)

?***多粒度注意力机制的图像超分辨, (from 密歇根)

?**基于多信息提炼网络的轻量级图像超分辨, (from 西安电子科大)
?COPHY物理动力学的反事实推理, 提出了一种可以学习物理因果关系的反事实推理模型来从视觉输入中进行学习,并在合成三维数据环境中实现了很好的预测能力。(from 1LIRIS, INSA-Lyon 2Facebook AI Research 3LIFAT, INSA-CVL4Simon Fraser University, Borealis AI 5CITI, INRIA)
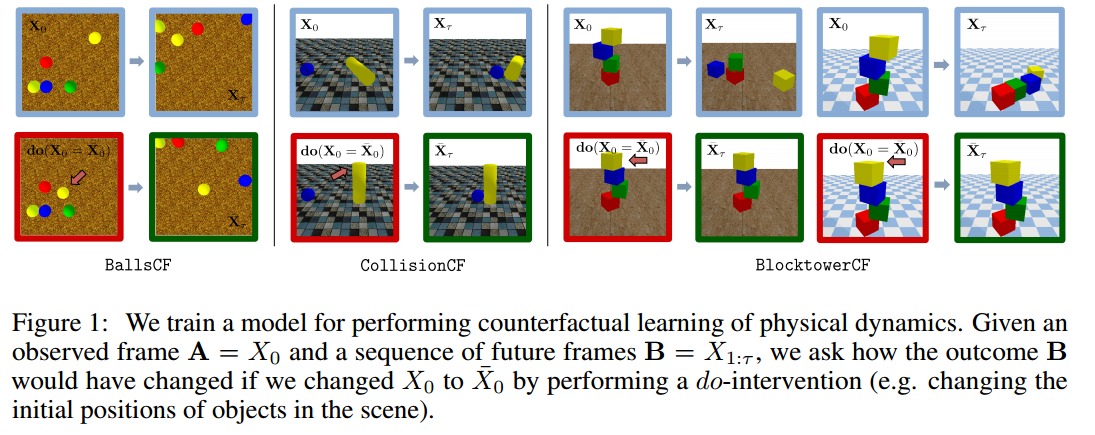
ref counterfactural, 1
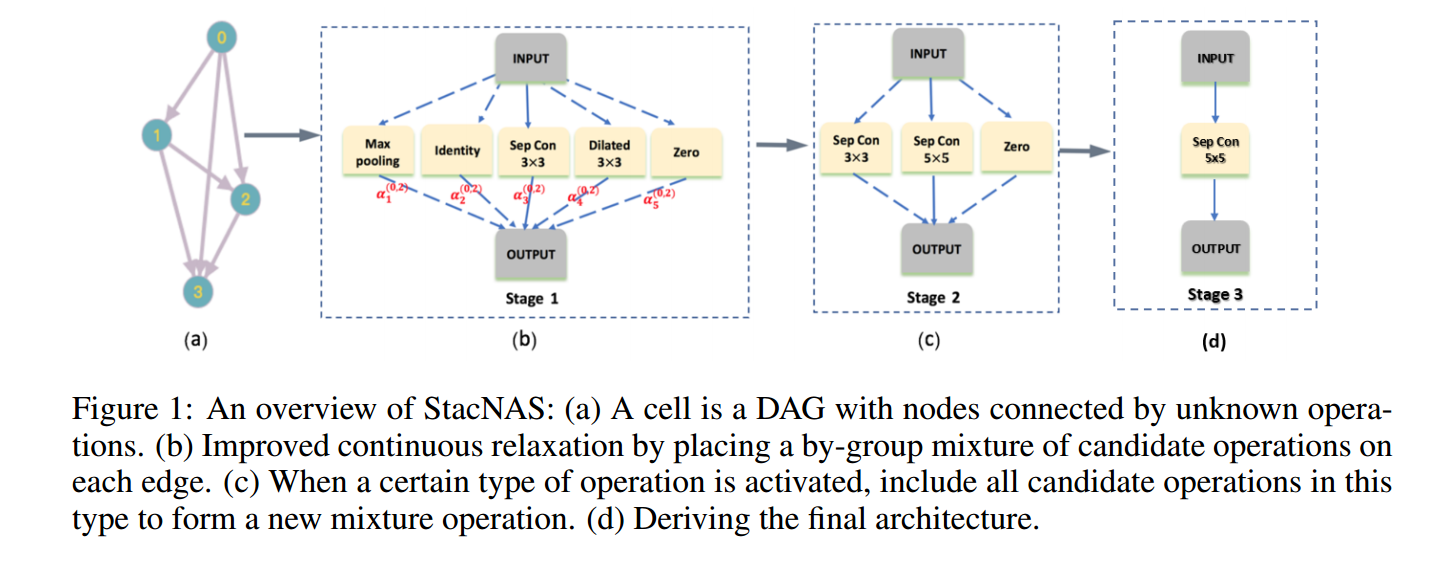
?**STACNAS稳定且连续的进行可微分的神经架构搜索, (from 华为 诺亚实验室)
?****Liquid Warping GAN人体运动合成,外表迁移和新视角合成, (from 上海科技大学)

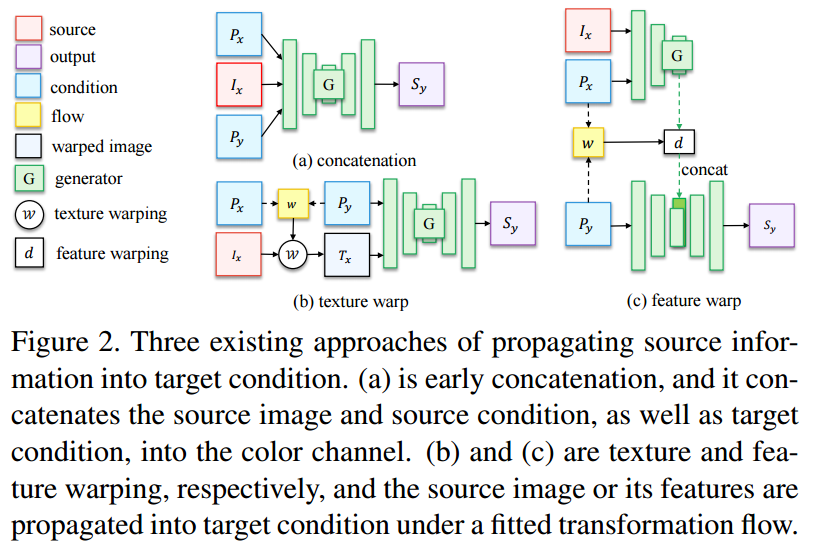
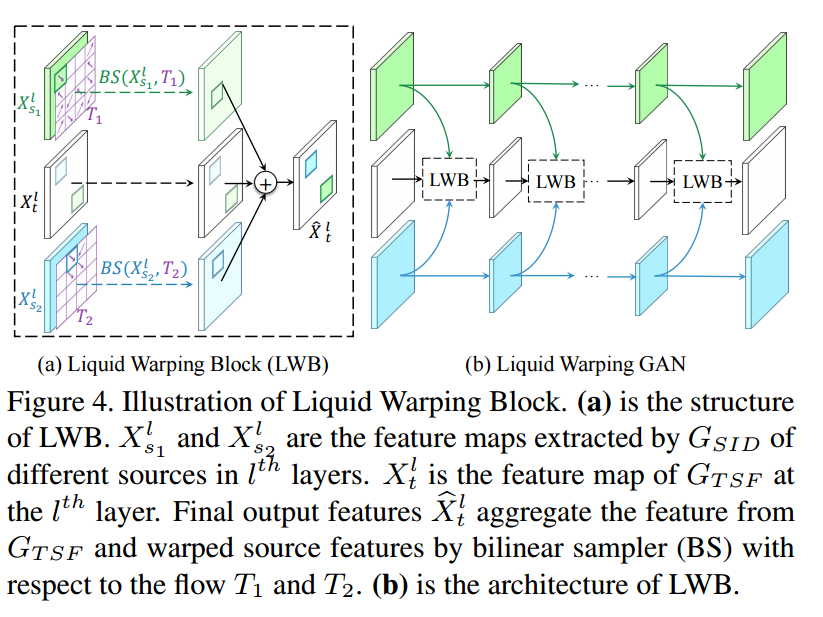
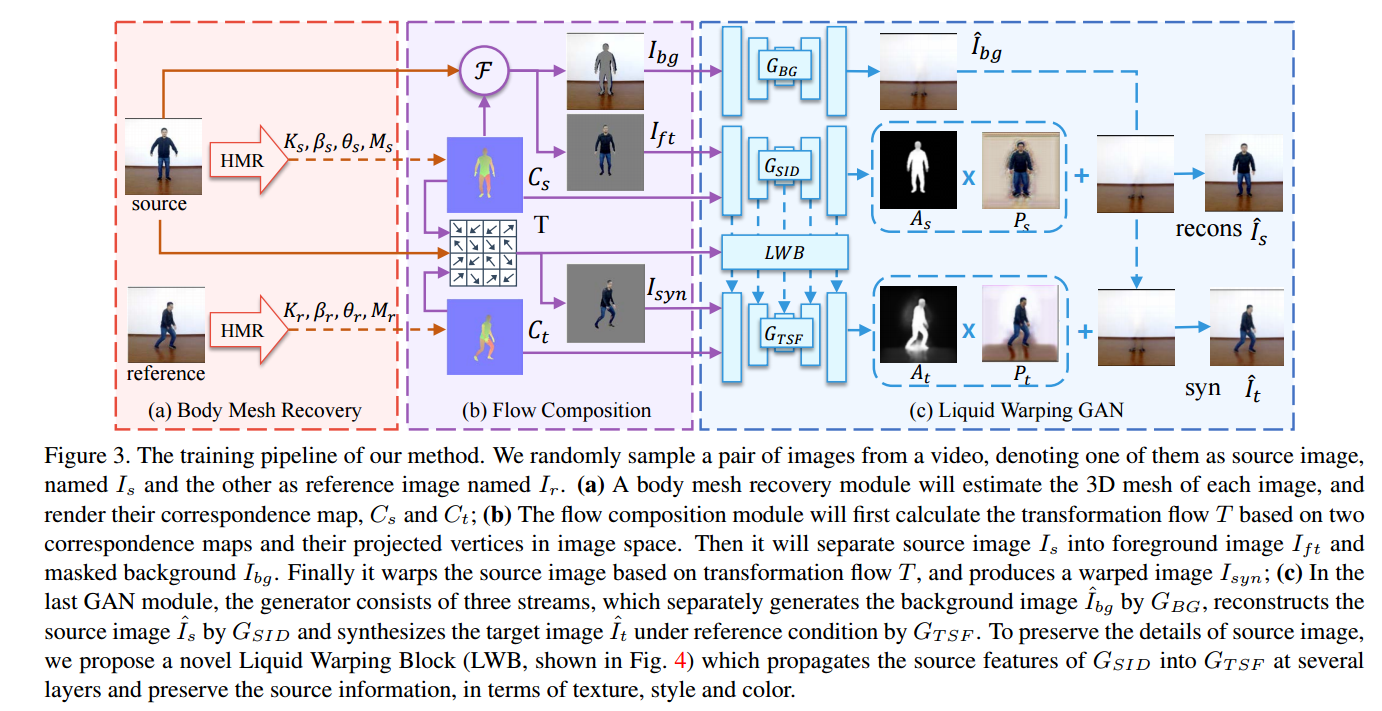
code:https://svip-lab.github.io/project/impersonator.html
?***隐含语义数据增强, 观察到特征空间中某些方向对应着有意义的语义变换,所以讲特征沿着语义方向进行变换增强(from 清华)
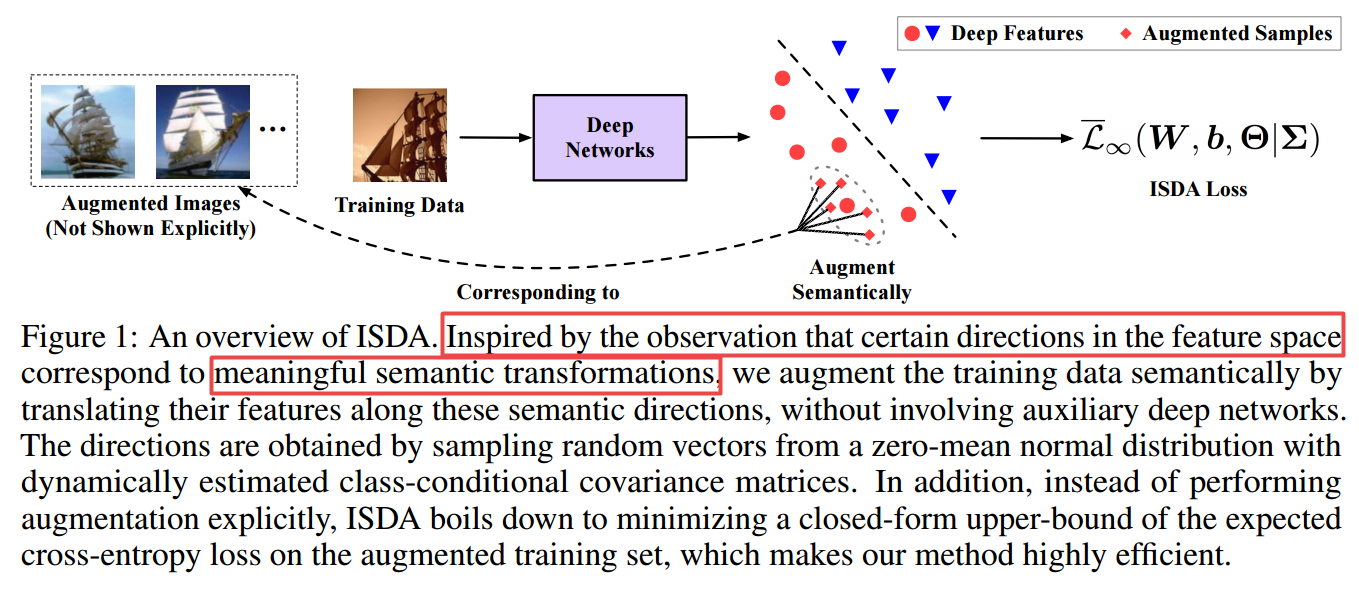
code:https://github.com/blackfeatherwang/ISDA-for-Deep-Networks
?多尺度动态特征编码去除图像摩尔条纹

?Deep Video Deblurring基于关键细节的去模糊

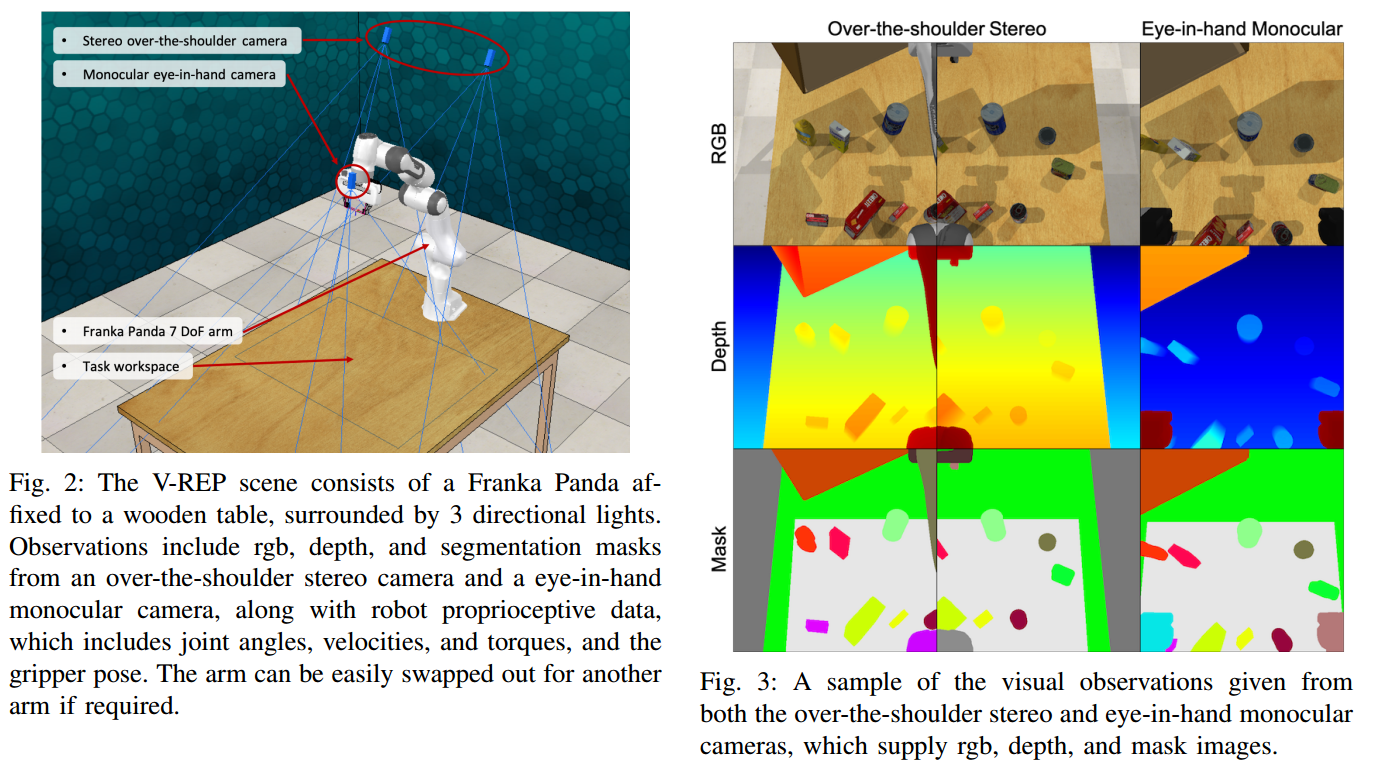
?+++RLBench 机器人学习基准和运行环境
?DISCOMAN 用于SLAM建图和导航的室内场景数据集,(from Samsung AI Center)

?WiderPerson 稠密情况下行人检测数据集

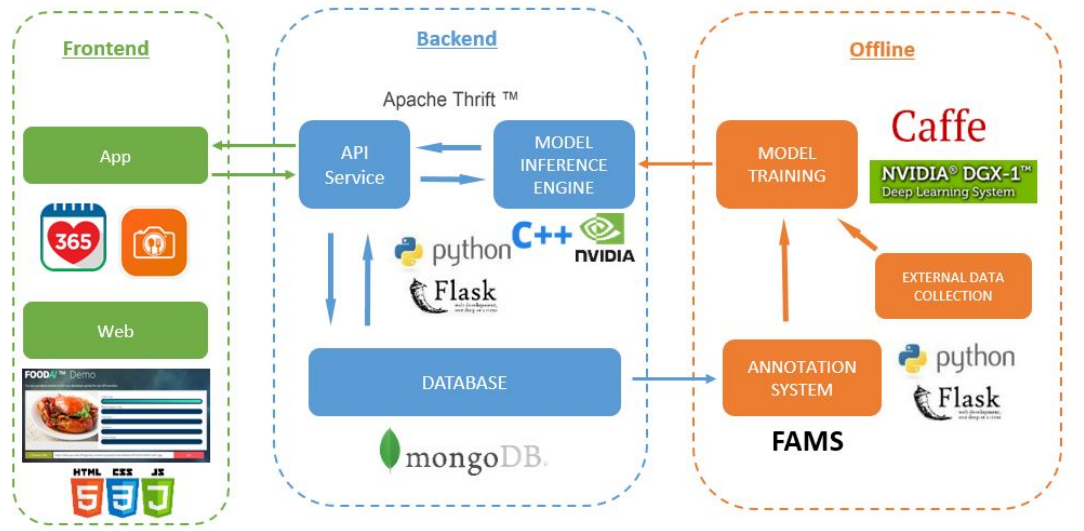
?FoodAI一个智能食物识别系统用于智能记录
?在葡萄树上进行葡萄数量密度估计
?高速完整的基于点云的lidar回环系统
?基于VAE解耦图像的选择和平移,并应用在天文学和蛋白质数据上
?++平衡不同域间目标实例检测的gap

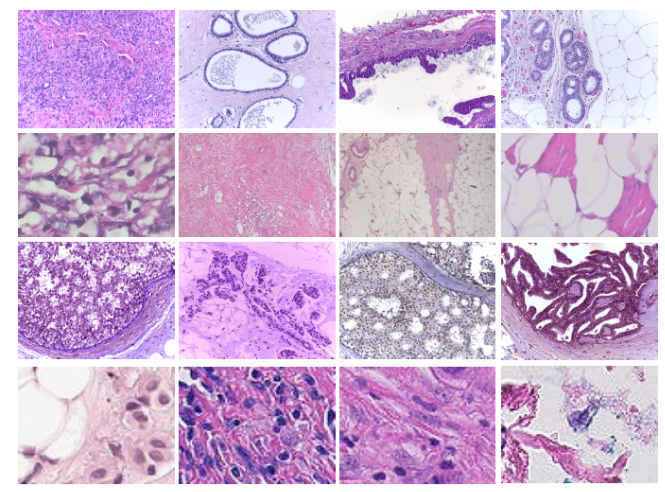
?**乳腺癌相关文章:
基于深度学习的低剂量高精度CT成像
乳腺癌病历组织检查分类 datset:ICIAR, BreakHis, PatchCamelyon, and Bioimaging
基于迁移学习和全局池化的乳腺癌检测
Daily Computer Vision Papers
| Range Adaptation for 3D Object Detection in LiDAR Authors Ze Wang, Sihao Ding, Ying Li, Minming Zhao, Sohini Roychowdhury, Andreas Wallin, Guillermo Sapiro, Qiang Qiu 基于LiDAR的3D对象检测在现代自动驾驶系统中起着至关重要的作用。 LiDAR数据通常在不同观察范围内表现出严重的特性变化。在本文中,我们探索了使用LiDAR进行3D对象检测的跨范围自适应,即远距离观测适用于近距离。这样,优化了远距离检测以实现与近距离检测相似的性能。我们采用鸟瞰BEV检测框架来执行建议的模型适配。我们的模型适应包括对抗性全局适应和细粒度局部适应。所提出的跨范围自适应框架已在基于LiDAR的三种最先进的物体检测网络上得到了验证,并且我们始终观察到远距离物体的性能有所提高,而没有向模型中添加任何辅助参数。据我们所知,本文是研究跨距离LiDAR自适应以进行点云中目标检测的首次尝试。为了证明所提出的适应框架的通用性,进一步进行了更具挑战性的跨设备适应性实验,并发布了具有高质量带注释点云的新LiDAR数据集,以促进未来的研究。 |
| Video Surveillance of Highway Traffic Events by Deep Learning Architectures Authors Matteo Tiezzi, Stefano Melacci, Marco Maggini, Angelo Frosini 在本文中,我们描述了一种视频监视系统,该系统能够检测高速公路上固定摄像机拍摄的视频中的交通事件。感兴趣的事件包括视频中发生的特定情况序列,例如在紧急车道上停车的车辆。因此,检测这些事件需要分析视频流中的时间序列。我们比较了利用基于递归神经网络RNN和卷积神经网络CNN的体系结构的不同方法。第一种方法从每个视频帧中提取主要与运动有关的特征向量,并利用馈入所得向量序列的RNN。其他方法直接基于帧序列,这些帧最终会以逐像素运动信息丰富。所获得的流由堆叠CNN和RNN的体系结构处理,并且我们还研究了基于转移学习的模型。结果是非常有希望的,最好的架构将在实际操作条件下在线测试。 |
| Liquid Warping GAN: A Unified Framework for Human Motion Imitation, Appearance Transfer and Novel View Synthesis Authors Wen Liu, Zhixin Piao, Jie Min, Wenhan Luo, Lin Ma, Shenghua Gao 我们在一个统一的框架内处理人类的运动模仿,外观转移和新颖的视图合成,这意味着该模型一旦经过训练即可用于处理所有这些任务。现有的任务特定方法主要使用2D关键点姿势来估计人体结构。但是,它们仅表达位置信息,而无法表征个人的个性化形状并模拟肢体旋转。在本文中,我们建议使用3D身体网格恢复模块来解开姿势和形状,该模块不仅可以建模关节的位置和旋转,而且可以表征个性化的身体形状。为了保留源信息,例如纹理,样式,颜色和脸部身份,我们提出了带有液体翘曲块LWB的液体翘曲GAN,它可以在图像和特征空间中传播源信息,并相对于参考图像进行合成。具体地,通过去噪卷积自动编码器提取源特征以很好地表征源身份。此外,我们提出的方法能够支持来自多个来源的更灵活的变形。此外,我们建立了一个新的数据集,即Impersonator iPER数据集,用于评估人体运动模仿,外观转移和新颖的视图合成。大量的实验证明了我们方法在多个方面的有效性,例如在遮盖情况下的鲁棒性以及保持面部身份,形状一致性和衣服细节。所有代码和数据集均可在 |
| Implicit Semantic Data Augmentation for Deep Networks Authors Yulin Wang, Xuran Pan, Shiji Song, Hong Zhang, Cheng Wu, Gao Huang 在本文中,我们提出了一种新颖的隐式语义数据扩充ISDA方法,以补充诸如翻转,平移或旋转之类的传统扩充技术。我们的工作受到有趣的属性的启发,即深层网络惊人地擅长于线性化特征,从而使深层特征空间中的某些方向对应于有意义的语义转换,例如添加太阳镜或更改背景。结果,在特征空间中沿许多语义方向翻译训练样本可以有效地扩展数据集以提高泛化性。为了有效,高效地实现这一思想,我们首先对每个类别的深度特征的协方差矩阵进行在线估计,以获取类别内语义的变化。然后从具有估计协方差的零均值正态分布中提取随机向量,以增强该类别中的训练数据。重要的是,代替显式地扩展样本,我们可以直接最小化扩展训练集上预期交叉熵CE损失的上限,从而产生高效算法。实际上,我们表明,所提出的ISDA可以最大程度地减少新颖的健壮CE损失,从而给正常训练过程增加了可忽略的额外计算成本。尽管很简单,但ISDA不断提高了流行的深度模型ResNet和DenseNet在各种数据集(例如CIFAR 10,CIFAR 100和ImageNet)上的泛化性能。可在以下位置获得用于重现我们结果的代码: |
| Deep Video Deblurring: The Devil is in the Details Authors Jochen Gast, Stefan Roth 手持摄像机的视频去模糊是一项艰巨的任务,因为潜在的模糊是由摄像机抖动和物体运动引起的。先进的深层网络可以通过空间时间转换器或循环架构来利用相邻帧的时间信息。与这些涉及的模型相反,我们发现当特别注意时,简单的基线CNN可以表现出色。模型和培训程序的详细信息。为此,我们对这些关键细节进行了全面研究,发现了定量和定性性能的极端差异。利用这些细节可以使我们将简单的基线CNN的架构和训练程序提高到惊人的3.15dB,从而使其在竞争中更具竞争力。尖端网络。这就提出了一个问题,即报告的模型之间的准确性差异是否总是由于技术贡献还是受制于此类正交但至关重要的细节。 |
| Fast and Effective Adaptation of Facial Action Unit Detection Deep Model Authors Mihee Lee, Ognjen Oggi Rudovic, Vladimir Pavlovic, Maja Pantic 检测面部动作单位AU是自动识别情绪和认知状态的面部表情的基本步骤之一。尽管针对此任务提出了多种方法,但是大多数模型仅针对特定目标AU进行了训练,因此它们无法轻松地适应识别新AU的任务,即那些最初不用于训练的AU。目标模型。在本文中,我们提出了一种用于面部AU检测的深度学习方法,该方法可以通过仅利用来自新任务AU或主题的少量标记样本,轻松,快速地适应新AU或目标主题。为此,我们提出了一种基于模型不可知元学习C.Finn和Levine,2017的概念的建模方法,最初是针对一般图像识别检测任务(例如,从Omniglot数据集中的字符识别)提出的。具体地,每个受试者和/或AU被视为新的学习任务,并且模型基于先前任务的知识来学习适应以使用AU和受试者来预训练目标模型。因此,在给定新主题或AU的情况下,可以使用深度学习和不可知论元学习的概念,将训练和测试任务之间共享的元知识用于使模型适应新任务。我们在两个用于面部AU检测的基准数据集BP4D和DISFA上表明,所提出的方法可以轻松适应新任务的AU受试者。仅使用这些任务中的一些标记示例,该模型相对于基准即未调整的模型实现了较大的改进。 |
| DISCOMAN: Dataset of Indoor SCenes for Odometry, Mapping And Navigation Authors Pavel Kirsanov, Airat Gaskarov, Filipp Konokhov, Konstantin Sofiiuk, Anna Vorontsova, Igor Slinko, Dmitry Zhukov, Sergey Bykov, Olga Barinova, Anton Konushin 我们提出了一个新颖的数据集,用于训练和基准化语义SLAM方法。数据集由200个长序列组成,每个序列包含3000 5000个数据帧。我们使用现实的首页布局生成序列。为此,我们对模拟简单家用机器人运动的轨迹进行采样,然后沿这些轨迹渲染框架。每个数据帧包含使用基于物理的渲染生成的RGB图像,b个模拟的深度测量值,c个模拟的IMU读数和d栋房屋的地面实况占用网格。与现有数据集相比,我们的数据集具有更广泛的用途,并且是第一个专注于SLAM映射组件的大规模基准测试。数据集被分为从不同虚拟房屋集合中采样的列车验证测试部分。我们提供了基于经典几何和基于最近学习的SLAM算法,基线映射方法,语义分割和全景分割的基准测试结果。 |
| WiderPerson: A Diverse Dataset for Dense Pedestrian Detection in the Wild Authors Shifeng Zhang, Yiliang Xie, Jun Wan, Hansheng Xia, Stan Z. Li, Guodong Guo 通过现有基准数据集的可用性,行人检测取得了重大进展。但是,现实世界的要求与当前行人检测基准之间的多样性和密度存在差距1大多数现有数据集是从通过常规交通场景驾驶的车辆中获取的,通常会导致多样性不足2行人高度拥堵的人群场景是仍然不足以表示,导致密度低。为了缩小这一差距并促进未来的行人检测研究,我们引入了一个名为WiderPerson的大型且多样化的数据集,用于野外密集的行人检测。该数据集在广泛的场景中涉及五种类型的注释,不再局限于交通场景。总共有13382张图像,带有399786个注释,即每个图像29.87个注释,这意味着该数据集包含具有各种遮挡的密集行人。因此,由于场景和遮挡的巨大变化,建议数据集中的行人极富挑战性,这适合评估野外的行人检测器。我们引入了改进的Faster R CNN和香草RetinaNet,以作为新的行人检测基准的基准。在包括Caltech USA和CityPersons在内的先前数据集上进行了一些实验,以分析所提出数据集的泛化能力,我们在这些先前数据集上获得了无与伦比的最新性能。最后,通过对常见故障案例的分析,发现行人探测器的分类能力有待提高,以减少误报和漏检率。提议的数据集可在以下位置获得 |
| Balanced Binary Neural Networks with Gated Residual Authors Mingzhu Shen, Xianglong Liu, Kai Han, Ruihao Gong, Yunhe Wang, Chang Xu 近年来,二进制神经网络吸引了众多关注。但是,主要由于二值化的偏差导致信息丢失,如何保持网络的准确性仍然是一个关键问题。在本文中,我们尝试维护正向过程中传播的信息,并提出带有门控残差BBG的平衡二值神经网络。首先,引入了权重平衡的二值化以最大化二进制权重的信息熵,因此,信息性二进制权重可以捕获激活中包含的更多信息。其次,对于二进制激活,还附加了门控残差以补偿其在前向过程中的信息丢失,并且开销很小。两种技术都可以包装为通用网络模块,该模块支持用于不同任务(包括分类和检测)的各种网络体系结构。我们评估BBG在CIFAR 10 100和ImageNet上进行的图像分类任务以及在Pascal VOC上进行的检测任务。实验结果表明,BBG Net在各种网络体系结构(例如VGG,ResNet和SSD)上均具有出色的性能,在内存消耗,推理速度和准确性方面均优于最新方法。 |
| Optimal Transport, CycleGAN, and Penalized LS for Unsupervised Learning in Inverse Problems Authors Byeongsu Sim, Gyutaek Oh, Sungjun Lim, Jong Chul Ye 惩罚最小二乘PLS是解决反问题的经典方法,其中添加了正则项以稳定解。最佳运输OT是另一种用于计算机视觉任务的数学框架,它提供了以最小的成本将一种措施运输到另一种措施的手段。周期一致的生成对抗网络周期GAN是GAN的最新扩展,用于学习具有较少模式崩溃行为的目标分布。尽管相似之处在于不需要监督训练,但算法看起来有所不同,因此这些方法之间的数学关系尚不清楚。在本文中,我们提供了重要的进展来揭示缺少的链接。具体来说,我们发现,如果将具有深度学习惩罚的PLS用作测量和未知图像的两个概率度量之间的运输成本,则可以将cycleGAN体系结构导出为最佳运输问题的对偶公式。这表明cycleGAN可被视为经典PLS方法的随机概括。我们的推论是如此笼统,以至于仅通过改变运输成本就可以轻松推导各种类型的cycleGAN架构。作为概念的证明,本文为加速MRI和解卷积显微镜问题中的无监督学习提供了新颖的cycleGAN架构,这证实了该理论的有效性和灵活性。 |
| In-field grape berries counting for yield estimation using dilated CNNs Authors L. Coviello, M. Cristoforetti, G. Jurman, C. Furlanello 数字技术引发了被称为精准农业的农业食品领域的一场革命,实现大规模精准农业的一个主要问题是能否利用现有技术和农艺师技能以最低的成本提供准确的产品质量控制。作为沿该方向的一项贡献,我们展示了一种工具,该工具可通过适应最初为人群计数而开发的深度学习算法,从智能手机相机准确估算水果产量。 |
| Follows Form: Regression from Complete Thoracic Computed Tomography Scans Authors Max Argus, Cornelia Schaefer Prokop, David A. Lynch, Bram van Ginneken 慢性阻塞性肺疾病COPD是发病率和死亡率的主要原因。虽然COPD诊断基于肺功能测试,但可以在计算机断层CT CT扫描上看到疾病的不同方面的早期阶段和进展,并对其进行定量评估。已经发表了许多量化与COPD有关的成像生物标志物的研究。在本文中,我们提出了一个卷积神经网络,该网络可以直接计算视觉气肿评分并根据COPDGene研究预测195次CT扫描的肺功能检查结果。与先前的工作相反,所提出的方法没有对有关量化内容的任何特定的先验知识进行编码,而是通过一组1424次CT扫描来端到端训练其输出参数可用。网络为这些任务提供了最先进的结果视觉肺气肿评分与训练有素的观察员进行的COPD诊断所评估的评分相当,根据估计的肺功能达到ROC曲线下的面积为0.94,优于现有技术。该方法很容易推广到其他情况,其中需要将来自整个扫描的信息汇总为单个数量。 |
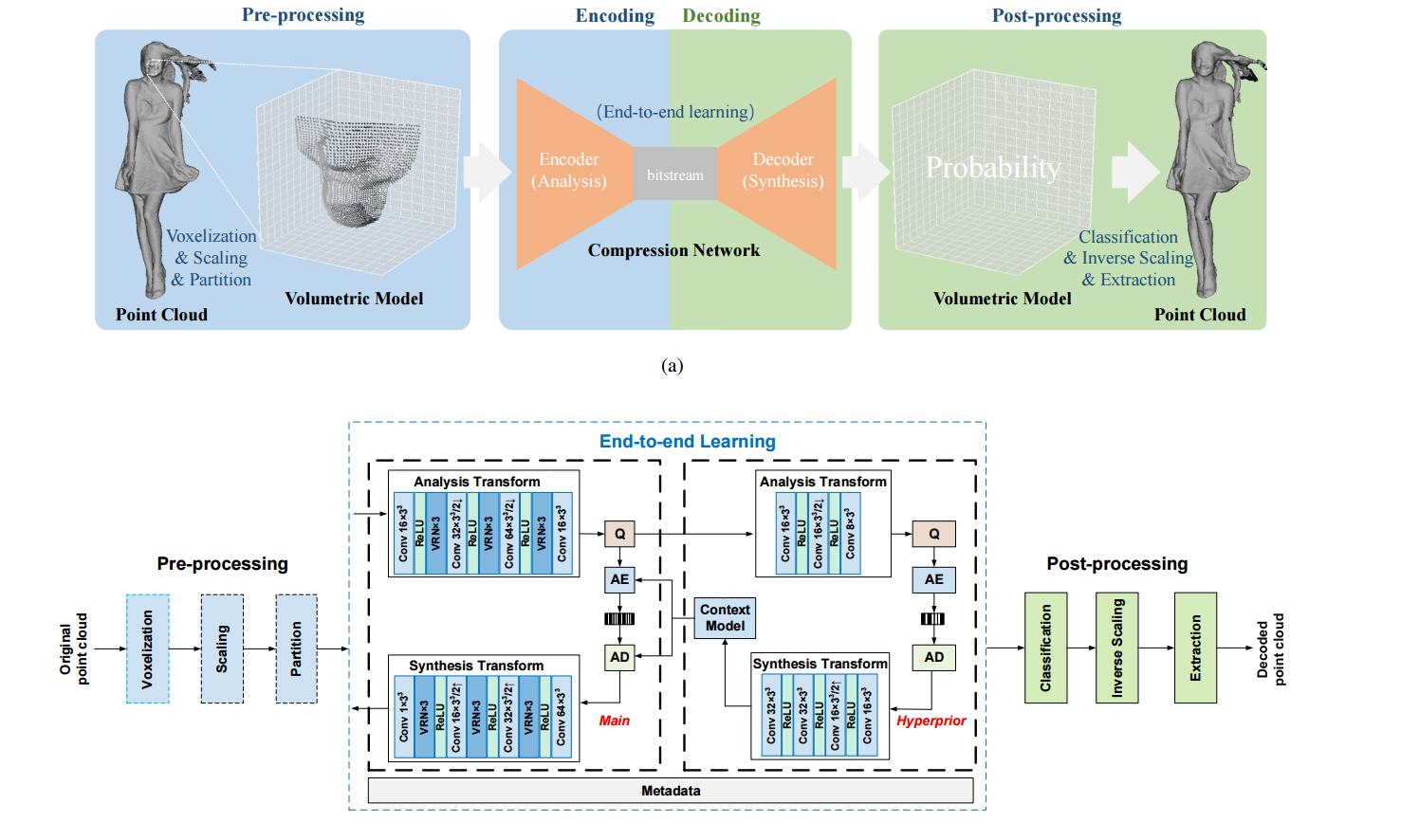
| Learned Point Cloud Geometry Compression Authors Jianqiang Wang, Hao Zhu, Zhan Ma, Tong Chen, Haojie Liu, Qiu Shen 本文提出了一种新颖的端到端学习型点云几何压缩(又称学习型PCGC框架),以使用基于深度神经网络DNN的变分自动编码器VAE有效地压缩点云几何PCG。在我们的方法中,首先对PCG进行体素化,缩放和划分为不重叠的3D立方体,然后将其馈入堆叠的3D卷积中以实现紧凑的潜在特征和超优先生成。 Hyperprior用于改善潜在特征的条件概率建模。加权二元交叉熵WBCE损失在训练中应用,而自适应阈值用于推理以去除不必要的体素并减少失真。客观地讲,我们的方法超过了由著名运动图像专家组MPEG标准化的基于几何的点云压缩G PCC算法,并且使用常见的测试数据集具有显着的性能裕度,例如,至少有60 BD速率的Bjontegaard Delta速率增益。从主观上讲,与所有现有的符合MPEG标准的PCC方法相比,我们的方法具有更好的视觉质量,表面重建更流畅,细节更吸引人。我们的方法总共需要约2.5MB的参数,即使在嵌入式平台上,对于实际实现而言,这也是相当小的大小。额外的消融研究会分析各种方面,例如立方体大小,内核等,以探索我们学到的PCGC的应用潜力。 |
| Convex Relaxations for Consensus and Non-Minimal Problems in 3D Vision Authors Thomas Probst, Danda Pani Paudel, Ajad Chhatkuli, Luc Van Gool 在本文中,我们使用计算代数几何中的多项式优化问题POP的现有工具来制定通用的非极小值求解器。所提出的方法利用了众所周知的Shor或Lasserre松弛,并讨论了其理论方面。值得注意的是,我们还针对3D视觉中的通用共识最大化问题进一步开发了非最小求解器的POP公式。我们的框架实现起来简单明了,并且在3D视觉中得到了三个不同的应用程序的支持,即刚体变换估计,Motion NRSfM的非刚性结构以及相机自动校准。在所有这三种情况下,都测试了非最小化和共识最大化,并将它们与最新方法进行了比较。我们的结果与比较方法相比具有竞争力,也与我们的理论分析相一致。本文的主要贡献是声称可以使用现有的数值计算代数理论来获得3D视觉中涉及的许多多项式问题的良好近似解。这种说法使我们有理由思考为什么3D视觉中的许多松弛方法表现得如此出色,并且还使我们能够以一种相当直接的方式提供通用的松弛求解器。我们进一步表明,这些多项式的凸松弛可以轻松地用于以确定性方式最大化共识。我们通过针对上述3D视觉中的三个不同问题的几个实验来支持我们的主张。 |
| COPHY: Counterfactual Learning of Physical Dynamics Authors Fabien Baradel, Natalia Neverova, Julien Mille, Greg Mori, Christian Wolf 了解机械系统中的因果关系是物理世界中推理的重要组成部分。这项工作提出了从视觉输入反事实学习对象力学的新问题。我们开发了COPHY基准测试,以评估用于合成3D环境中因果推理的最新模型的能力,并提出用于在反事实环境中学习物理动力学的模型。观察到机械实验后,例如,涉及到一个下降的砖塔,一组弹跳球或碰撞物体,我们学会了预测其结果如何受到其初始条件的任意干预的影响,例如替换其中一个。场景中的对象。鉴于过去的变化和模型在无人监督的情况下以端到端的方式学习到的混杂因素的潜在表示,可以预测到替代的未来。我们将其与前馈视频预测基准进行比较,并显示观察替代体验如何使网络捕获环境的潜在物理属性,从而在超级人的绩效水平上实现更准确的预测。 |
| The Stroke Correspondence Problem, Revisited Authors Dominik Klein 我们重新审视中风对应问题13,14。我们通过1评估合适的预处理规范化方法2对该算法进行了优化,以一种额外的距离度量来扩展该算法,以处理具有较少笔触的平假名,片假名和汉字字符,并简化了笔划链接算法。我们的贡献在免费的开源库ctegaki以及演示工具jTegaki和Kanjicanvas中实现。 |
| Subjective and Objective De-raining Quality Assessment Towards Authentic Rain Image Authors Qingbo Wu, Lei Wang, King N. Ngan, Hongliang Li, Fanman Meng 由于下雨天,由室外视觉系统获取的图像容易受到可见性差和烦人的干扰,这对准确理解和描述视觉内容提出了巨大的挑战。最近的研究已经致力于去除雨水的任务以改善图像的可见性。但是,关于除雨图像质量评估的探索很少,即使对于准确测量各种除雨算法的性能至关重要。在本文中,我们首先创建一个除雨质量评估DQA数据库,该数据库收集206个真实的降雨图像及其由6种代表性单图像除雨算法产生的除雨版本。然后,在我们的DQA数据库上进行主观研究,该数据库收集所有除雨图像的主题评分。为了定量测量具有非均匀伪影的雨水图像的质量,我们提出了一种双向特征嵌入网络B FEN,它将全局感知和局部差异的特征整合在一起。实验证实,该方法明显优于许多现有的通用盲图像质量评估模型。为了帮助研究可感知的首选除雨算法,我们将在以下位置公开发布DQA数据库和B FEN源代码: |
| Learning Energy-based Spatial-Temporal Generative ConvNets for Dynamic Patterns Authors Jianwen Xie, Song Chun Zhu, Ying Nian Wu 视频序列包含丰富的动态模式,例如在时域表现出平稳性的动态纹理模式,以及在空间或时域都不稳定的动作模式。我们表明,基于能量的时空生成ConvNet可以用于建模和合成动态模式。该模型定义了视频序列上的概率分布,对数概率由空间时间卷积网络定义,该空间卷积网络由多层空间时间滤波器组成,以捕获不同尺度的空间时间模式。可以通过迭代以下两个步骤的综合学习算法分析,从训练视频序列中学习模型。步骤1根据当前学习的模型合成视频序列。然后,步骤2基于合成视频序列与观察到的训练序列之间的差异来更新模型参数。我们证明了学习算法可以综合现实的动态模式。我们还表明,可以从具有闭塞像素或丢失帧的不完整训练序列中学习模型,从而可以同时完成模型学习和模式完成。 |
| Dual-Stream Pyramid Registration Network Authors Xiaojun Hu, Miao Kang, Weilin Huang, Matthew R. Scott, Roland Wiest, Mauricio Reyes 我们建议将双流金字塔注册网络(称为Dual PRNet)用于无监督3D医学图像注册。与最近的基于CNN的配准方法(例如VoxelMorph,它探索单个流编码器解码器网络以从一对3D体积计算配准字段)不同,我们设计了两个流体系结构,能够从卷积特征金字塔计算多尺度配准字段。我们的贡献是双重的。我设计了一个两流3D编码器解码器网络,该网络针对一对输入量分别计算两个卷积特征金字塔,从而产生了对变形估计有意义的强大的深层表示形式。ii我们提出了一种能够预测的金字塔配准模块直接来自解码特征金字塔的多尺度配准字段。这使得它可以通过顺序扭曲从粗到细逐步地逐步细化配准场,并使模型具有处理两个体积之间的显着变形(例如在空间域或切片空间中的大位移)的能力。拟议的Dual PRNet在用于大脑MRI配准的两个标准基准上进行了评估,在很大程度上优于最新方法,例如,与最近的VoxelMorph 2相比,LPBA40的改进为0.683 0.778,Mindboggle101的改进为0.511 0.631 ,以平均骰子得分为单位。 |
| Multi-scale Dynamic Feature Encoding Network for Image Demoireing Authors Xi Cheng, Zhenyong Fu, Jian Yang 诸如数码相机和移动电话之类的数字传感器的普及简化了照片的获取。但是,数字传感器在拍摄具有复杂纹理的物体时会产生莫尔条纹,这会降低照片质量。莫尔条纹分布在图像的各个频带上,是一种动态纹理,具有不同的颜色和形状,这对拆除图像修复中的一项重要任务提出了两个主要挑战。在本文中,为解决第一个挑战,我们设计了一个多尺度网络来处理不同空间分辨率的图像,获得不同频段的特征,因此我们的方法可以共同去除不同频段的莫尔条纹。为了解决第二个挑战,我们提出了一个嵌入在每个比例尺中的动态特征编码模块DFE,用于动态纹理。通过DFE可以更有效地消除莫尔条纹图案。我们提出的方法,即具有动态特征编码的多尺度卷积网络,用于图像DeMoireing MDDM,在保真度和基准方面都可以超越现有技术。 |
| FoodAI: Food Image Recognition via Deep Learning for Smart Food Logging Authors Doyen Sahoo, Wang Hao, Shu Ke, Wu Xiongwei, Hung Le, Palakorn Achananuparp, Ee Peng Lim, Steven C. H. Hoi 健康监测的一个重要方面是有效记录食物消费量。这可以帮助管理与饮食有关的疾病,例如肥胖,糖尿病甚至心血管疾病。此外,食物记录可以帮助健身爱好者以及想要达到目标体重的人们。然而,食物记录很麻烦,并且不仅需要付出额外的努力来记下定期食用的食物,而且还需要对食用的食物有足够的了解,这由于多种菜式的可获得性而变得困难。随着对智能设备的日益依赖,我们充分利用了通过使用智能手机提供的便利,并提出了智能食品记录系统FoodAI,该系统可提供基于深度学习的先进图像识别功能。 FoodAI已在新加坡开发,尤其专注于新加坡通常消费的食品。 FoodAI模型在来自756个不同类别的40万个食物图像的语料库上进行了训练。在本文中,我们将对该系统的开发进行广泛的分析和见解。 FoodAI已被部署为API服务,并且是为新加坡健康促进委员会开发的移动应用程序Healthy 365提供支持的组件之一。我们有100多家注册组织的大学,公司,初创公司订阅此服务,并且每天都积极收到一些API请求。 FoodAI使食物记录变得便捷,有助于智能消费和健康生活方式。 |
| Multiple Object Forecasting: Predicting Future Object Locations in Diverse Environments Authors Olly Styles, Tanaya Guha, Victor Sanchez 本文介绍了多目标预测MOF问题,其目的是预测跟踪对象的未来边界框。与主要从鸟瞰角度考虑问题的对象轨迹预测的现有工作形成对比,我们从对象级别的角度阐述问题,并呼吁对整个对象边界框进行预测,而不是仅对轨迹进行预测。为了解决此任务,我们介绍了Citywalks数据集,该数据集包含超过200k的高分辨率视频帧。 Citywalks包含来自10个欧洲国家的21个城市的各种天气条件下记录的镜头,以及超过3.5k的独特行人轨迹。为了进行评估,我们调整了MOF的现有轨迹预测方法,并在不进行微调的情况下确认了MOT 17数据集上的交叉数据集可概括性。最后,我们介绍了STED,一种用于MOF的新颖编码器解码器体系结构。 STED结合了视觉和时间特征来对物体运动和自我运动进行建模,并且优于MOF的现有方法。代码数据集链接 |
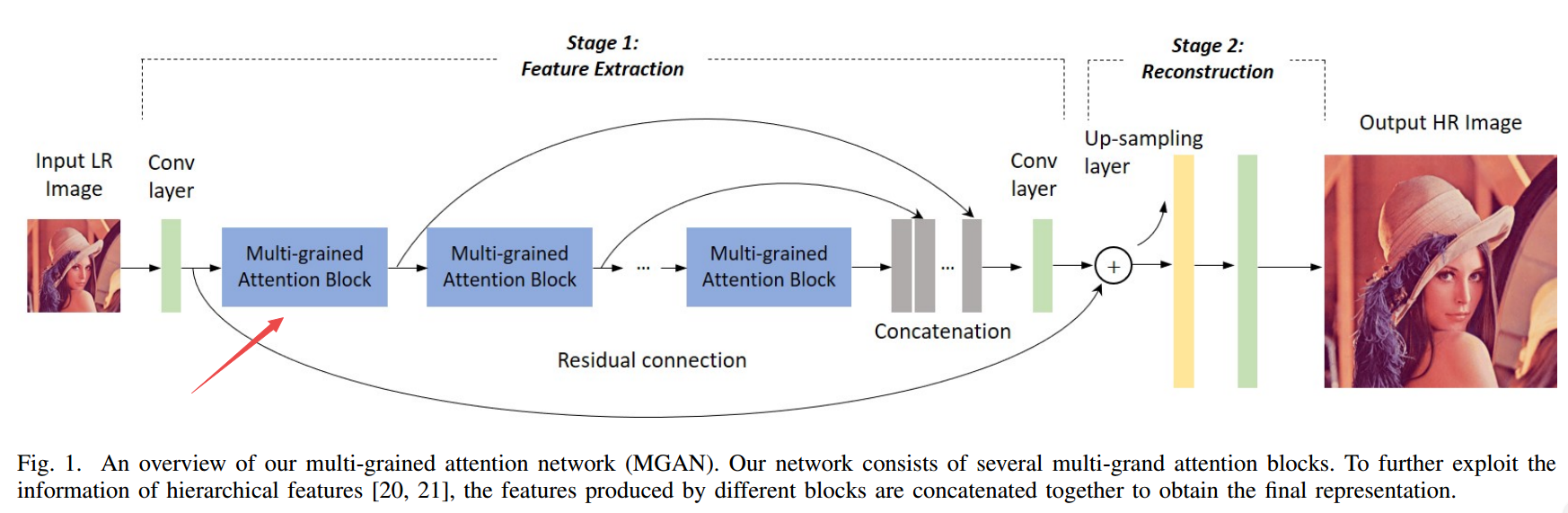
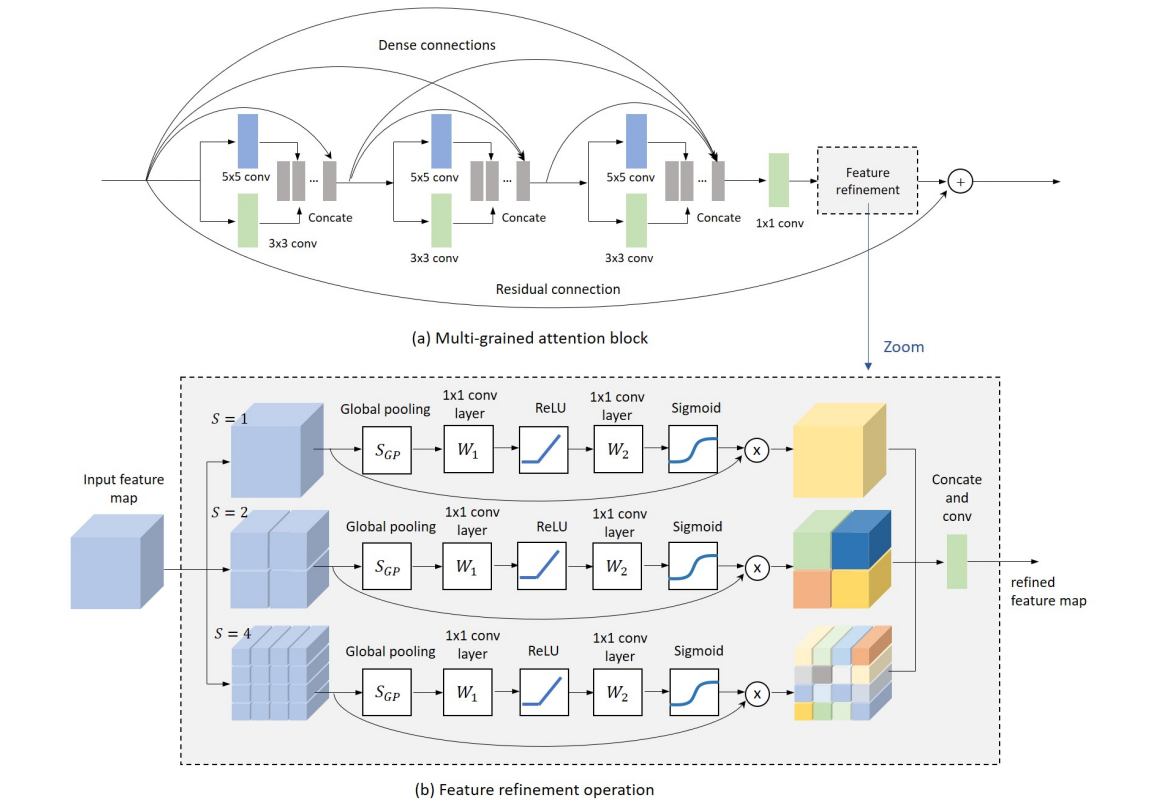
| Multi-grained Attention Networks for Single Image Super-Resolution Authors Huapeng Wu, Zhengxia Zou, Jie Gui, Senior Member, IEEE, Wen Jun Zeng, Jieping Ye, Senior Member, IEEE, Jun Zhang, Member IEEE, Hongyi Liu, Member IEEE, Zhihui Wei 深度卷积神经网络CNN在图像超分辨率SR中引起了极大的关注。近年来,视觉注意力机制同时利用了特征重要性和上下文提示,已被引入到图像SR中,并被证明可有效改善基于CNN的SR性能。在本文中,我们对SR模型中的注意机制进行了深入研究,并阐明了对这些想法的简单有效的改进如何改善了现有技术。我们进一步提出一种称为多粒度注意力网络MGAN的统一方法,该方法充分利用了SR任务中多尺度和注意力机制的优势。在我们的方法中,每个神经元的重要性是根据其周围区域以多粒度方式计算的,然后用于自适应地重新缩放特征响应。更重要的是,先前方法中的通道注意和空间注意策略可以本质上视为我们方法的两个特例。我们还引入了多尺度密集连接以提取多个尺度的图像特征,并通过密集跳过连接捕获不同图层的特征。对基准数据集的消融研究证明了我们方法的有效性。与其他最新的SR方法相比,我们的方法在准确性和模型大小方面均显示出优越性。 |
| A Symmetric Equilibrium Generative Adversarial Network with Attention Refine Block for Retinal Vessel Segmentation Authors Yukun Zhou, Zailiang Chen, Hailan Shen, Peng Peng, Ziyang Zeng, Xianxian Zheng 目的认识眼底血管异常对眼科疾病和心血管事件的早期诊断至关重要。但是,分割结果受到难以捉摸的细血管的影响。在这项工作中,我们提出了一个合成网络,包括对称均衡的生成对抗网络SEGAN,多尺度特征细化块MSFRB以及注意力机制AM,以增强血管分割的性能,特别是对于细血管。方法所提议的网络具有强大的多尺度表示能力。首先,提出了SEGAN以构建对称的对抗架构,这迫使生成器生成具有局部细节的更逼真的图像。其次,MSFRB旨在防止模糊高分辨率特征,从而保留多尺度特征。最后,AM被用来鼓励网络专注于区分特征。结果在公共数据集DRIVE,STARE和CHASEDB1上,我们定量评估了我们的网络,并将其与最新技术进行了比较。消融实验表明,SEGAN,MSFRB和AM均有助于实现我们网络的理想性能。结论拟议的网络优于其他策略,并在难以捉摸的血管分割中有效发挥作用,在灵敏度,G均值,精确度和F1得分方面得分最高,同时保持其他指标的最高水平。意义显着的性能和较高的计算效率为临床视网膜血管分割应用提供了巨大的潜力。同时,该网络可用于提取有关其他生物医学问题的详细信息。 |
| Adaptive Class Weight based Dual Focal Loss for Improved Semantic Segmentation Authors Md Sazzad Hossain, Andrew P Paplinski, John M Betts 在本文中,我们提出了双重焦点损失DFL函数,以代替标准的交叉熵CE函数,以更好地处理数据集中的不平衡类。我们的DFL方法是对最近报道的Focal Loss FL交叉熵函数的改进,该函数提出了一种缩放方法,该方法将较难分类的示例放在较容易分类的示例上。但是,FL的缩放参数是根据经验设置的,这取决于问题。另外,像其他CE变体一样,FL仅关注丢失真实类。因此,不会从错误的类中获得损失反馈。尽管由于softmax函数的性质,仅关注真实示例会增加真实类的概率,并相应地降低错误类的概率,但由于避免了错误类的损失,因此无法达到最佳收敛。我们的DFL方法在两个方面改进了简单FL。首先,FL的思想比简单的例子更多地关注困难的例子,但是在同等重要性的真实和负面类别上评估损失。其次,DFL的缩放参数已变得可学习,因此它可以通过反向传播进行自我调整,而不必依赖于手动调整。通过这种方式,我们提出的DFL方法提供了一种自动可调损失函数,可以减少类不平衡的影响,并且可以将更多的注意力放在真实的困难示例和负面的容易示例上。实验结果表明,我们提出的方法可在各种不同的网络模型和数据集上进行的每次测试中提供更高的准确性。 |
| Unsupervised Image Translation using Adversarial Networks for Improved Plant Disease Recognition Authors Haseeb Nazki, Sook Yoon, Alvaro Fuentes, Dong Sun Park 机器学习的特定任务应用(例如植物病害识别)中的数据获取是一项昂贵的工作,因为需要专业的人类勤奋和时间限制。在本文中,我们提出了一个简单的管道,该管道在无监督的图像翻译环境中使用GAN来改善对植物病害数据集中数据分布的学习,减少由急性类别失衡引起的偏性,从而使分类决策边界朝着更好的方向发展性能。我们的方法的经验分析在2789个番茄植物病害图像的有限数据集上得到了证明,该数据集在9个疾病类别中高度失衡且不平衡。首先,我们通过提高生成的图像的感知质量并保留语义,将基于GAN的图像的现有技术扩展到图像翻译方法。我们介绍了AR GAN,除了对抗损失外,我们的合成图像生成器还优化了激活重建损失ARL功能,该功能优化了针对自然图像的特征激活。与目前最杰出的现有模型相比,我们在视觉上呈现更具吸引力的合成图像,并根据各种数据集和指标评估GAN框架的性能。其次,我们评估基线卷积神经网络分类器的性能,以使用所得的合成样本来增强我们的训练集并将其与经典数据增强方案进行比较,从而提高识别能力。我们观察到使用生成的合成样本在分类准确度5.2上有显着提高,而在同等类别的分布环境中使用经典增强法则提高了0.8。 |
| Deep Model Transferability from Attribution Maps Authors Jie Song, Yixin Chen, Xinchao Wang, Chengchao Shen, Mingli Song 探索异构任务之间的可传递性,有助于了解它们之间的内在联系,从而使知识从一项任务转移到另一项任务,从而减少了后者的培训工作量。在本文中,我们提出了一种令人尴尬的简单但非常有效的方法来估计深层网络的可传输性,尤其是那些处理视觉任务的网络。与任务法的开创性工作依赖大量注释作为监督并因此在计算上繁琐不同,所提出的方法不需要人工注释,并且对网络的体系结构没有任何约束。具体而言,这是通过将深层网络投影到模型空间中来实现的,其中将每个网络视为一个点,并通过其产生的属性图的偏差来测量两个点之间的距离。所提出的方法比任务法快几个数量级,同时保留了与任务法获得的拓扑结构高度相似的任务方式拓扑结构。代码位于 |
| Joint-task Self-supervised Learning for Temporal Correspondence Authors Xueting Li, Sifei Liu, Shalini De Mello, Xiaolong Wang, Jan Kautz, Ming Hsuan Yang 本文提出以自我监督的方式从视频中学习可靠的密集对应关系。我们的学习过程集成了两个高度相关的任务,这些任务跟踪较大的图像区域,并在连续的视频帧之间建立细粒度的像素级关联。我们通过共享的帧间相似度矩阵利用两个任务之间的协同作用,该矩阵同时在区域和像素级别对视频帧之间的过渡进行建模。虽然区域级别的本地化通过缩小搜索区域的范围来帮助减少细粒度匹配中的歧义,但细粒度的匹配则提供了自底向上的功能以促进区域级别的本地化。我们的方法在包括视频对象和零件分割传播,关键点跟踪和对象跟踪在内的各种视觉对应任务上,均优于现有的自我监督方法。我们的自我监督方法甚至超过了从ImageNet上经过预先训练的ResNet 18获得的完全监督的亲和力特征表示。 |
| Resolving Marker Pose Ambiguity by Robust Rotation Averaging with Clique Constraints Authors Shin Fang Ch ng, Naoya Sogi, Pulak Purkait, Tat Jun Chin, Kazuhiro Fukui 平面标记可用于机器人技术和计算机视觉中的地图绘制和定位。给定图像中检测到的标记,常见的任务是估计标记相对于相机的6DOF姿势,这是平面姿势估计PPE的一个实例。尽管存在成熟的技术,但是PPE面临一个基本的歧义问题,因为对于PPE实例,可能有多个可能的姿势解决方案。特别是当标记角的定位很嘈杂时,通常仅基于重投影误差就很难消除姿势解的歧义。先前的方法使用启发式标准在可能的解决方案之间进行选择,或者只是忽略不明确的标记。 |
| Compact Trilinear Interaction for Visual Question Answering Authors Tuong Do, Thanh Toan Do, Huy Tran, Erman Tjiputra, Quang D. Tran 在“视觉提问” VQA中,答案与问题含义和视觉内容具有很大的相关性。因此,为了有选择地利用图像,问题和答案信息,我们提出了一种新颖的三线性交互模型,该模型同时学习了这三个输入之间的高级关联。另外,为了克服交互的复杂性,我们引入了基于多模量张量的PARALIND分解,该分解有效地参数化了三个输入之间的三线性交互。此外,知识蒸馏是首次以自由形式开放式VQA应用。它不仅用于减少计算成本和所需的内存,还用于将知识从三线性交互模型转移到双线性交互模型。在基准数据集TDIUC,VQA 2.0和Visual7W上进行的广泛实验表明,当在所有三个数据集上使用单个模型时,所提出的紧凑型三线性交互模型可以达到最新的结果。 |
| Overcoming Data Limitation in Medical Visual Question Answering Authors Binh D. Nguyen, Thanh Toan Do, Binh X. Nguyen, Tuong Do, Erman Tjiputra, Quang D. Tran 视觉问答VQA的传统方法需要大量标记数据进行培训。不幸的是,这样的大规模数据通常不适用于医学领域。在本文中,我们提出了一种新颖的医疗VQA框架,该框架克服了标记数据的局限性。提出的框架探索了无监督的Denoising Auto Encoder DAE和有监督的元学习的使用。 DAE的优点是可以利用大量未标记的图像,而元学习的优点是可以通过有限的标记数据来学习快速适应VQA问题的元权重。通过利用这些技术的优势,可以使用一个小的标签训练集有效地训练所提出的框架。实验结果表明,我们提出的方法明显优于现有的医疗VQA。 |
| Convolutional Neural Networks with Dynamic Regularization Authors Yi Wang, Zhen Peng Bian, Junhui Hou, Lap Pui Chau 正则化通常用于机器学习中,以缓解过度拟合的情况。在卷积神经网络中,已经提出了诸如Dropout和Shake Shake之类的正则化方法来提高泛化性能。然而,这些方法在整个训练过程中缺乏自我适应性,即,正则化强度被固定为预定的时间表,并且必须执行手动调整以适应各种网络架构。在本文中,我们提出了一种动态正则化方法,该方法可以在训练过程中动态调整正则化强度。具体来说,我们将正则化强度建模为训练损失的后向差异,该差异可以在每次训练迭代中直接提取。借助动态正则化,大型模型可以通过强摄动进行正则化,反之亦然。实验结果表明,该方法可以提高现成网络体系结构的泛化能力,并且优于现有的正则化方法。 |
| UNITER: Learning UNiversal Image-TExt Representations Authors Yen Chun Chen, Linjie Li, Licheng Yu, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, Jingjing Liu 联合图像文本嵌入是大多数视觉和语言V L任务的基础,在此任务中,对多模态输入进行联合处理以实现视觉和文本理解。在本文中,我们介绍UNITER,这是一种通用图像TExt表示形式,它是通过对四个图像文本数据集COCO,Visual Genome,Conceptual Captions和SBU Captions进行大规模的预训练而学习的,这些数据集可以为具有联合多模式嵌入的异构下游V L任务提供支持。我们设计了三个预训练任务,其中包含三种变体:掩蔽语言建模MLM,图像文本匹配ITM和掩蔽区域建模MRM。与将联合随机掩蔽应用于两种模态的多模态预训练的并发工作不同,我们在预训练任务上使用条件掩蔽,即,掩蔽语言区域建模是基于对图像文本的完全观察来进行的。综合分析表明,条件遮罩比未条件遮罩产生更好的性能。我们还进行了彻底的消融研究,以找到适合预训练任务组合的最佳设置。广泛的实验表明,UNITER在9个数据集上的6个V L任务上达到了最新的水平,包括视觉问题解答,图像文本检索,引用表达理解,视觉常识推理,视觉蕴涵和NLVR2。 |
| Learning Pixel Representations for Generic Segmentation Authors Oran Shayer, Michael Lindenbaum 迄今为止,用于通用非语义分段的深度学习方法是间接的,并且依赖于边缘检测。这与语义分割相反,后者直接应用DNN。我们提出了一种称为深度通用分割DGS的替代方法,并尝试遵循用于语义分割的路径。我们的主要贡献是一种新的方法,用于学习反映段相关性的像素明智表示。该表示形式与CRF结合使用以产生分割算法。我们证明了我们能够学习提高分割质量的有意义的表示,并且表示本身达到了最新的细分相似度得分。细分结果具有竞争力且前景广阔。 |
| Revisit Knowledge Distillation: a Teacher-free Framework Authors Li Yuan, Francis E.H.Tay, Guilin Li, Tao Wang, Jiashi Feng 知识提炼KD旨在将笨拙的老师模型的知识提炼成轻量级的学生模型。它的成功通常归因于由教师模型提供的类别之间相似性的特权信息,从这个意义上说,只有强大的教师模型才能部署到实践中来教授较弱的学生。在这项工作中,我们通过遵循实验性观察1挑战了这一普遍的信念,除了承认教师可以提高学生的能力外,学生还可以通过逆转KD程序2显着提高教师的能力,而KD程序是一名训练有素的教师,其准确性远低于学生仍然可以显着改善后者。为了解释这些观察,我们提供了KD和标签平滑规则化之间关系的理论分析。我们证明1 KD是一种学习的标签平滑正则化类型,而2标签平滑正则化为KD提供了虚拟教师模型。根据这些结果,我们认为KD的成功并不完全归因于类别之间的相似性信息,还归因于软目标的正则化,这同样重要,甚至更为重要。 |
| Explicitly disentangling image content from translation and rotation with spatial-VAE Authors Tristan Bepler, Ellen D. Zhong, Kotaro Kelley, Edward Brignole, Bonnie Berger 在给定图像数据集的情况下,我们通常感兴趣的是寻找独立于姿势变量(例如旋转和平移)而对语义内容进行编码的数据生成因子。但是,当前的解缠结方法并未在学习的潜在表示上强加任何特定的结构。我们提出了一种在可变自动编码器VAE框架中将图像旋转和平移与其他非结构化潜在因素明确分离的方法。通过将生成模型公式化为空间坐标的函数,我们使重构误差相对于潜在的平移和旋转参数是可区分的。这种表述使我们能够训练神经网络对这些潜在变量进行近似推断,同时明确地限制它们仅表示旋转和平移。我们证明了这个称为空间VAE的框架有效地学习了从内容中解开图像旋转和平移的潜在表示,并改善了多个基准数据集上标准VAE的重构,包括从单粒子电子显微镜和星系建模蛋白质的连续2D视图的应用在天文图像中。 |
| DCTD: Deep Conditional Target Densities for Accurate Regression Authors Fredrik K. Gustafsson, Martin Danelljan, Goutam Bhat, Thomas B. Sch n 虽然通常使用标准化方法解决基于深度学习的分类,但可以采用多种技术进行回归。在计算机视觉中,一种特别流行的技术是基于置信度的回归技术,该技术需要预测每个输入目标对x,y的置信度值。尽管这种方法已显示出令人印象深刻的结果,但它需要根据任务进行重要的设计选择,并且所预测的置信度通常缺乏自然的概率意义。我们通过提出深度条件目标密度DCTD(一种具有清晰概率解释的新颖且通用的回归方法)来解决这些问题。 DCTD通过使用神经网络直接根据x,y预测未归一化的密度来对条件目标密度py x建模。通过最小化相关联的负对数似然度来训练p y x的模型,该负对数似然度使用蒙特卡洛采样法近似。我们对四个计算机视觉回归任务进行了综合实验。我们的方法优于直接回归法以及其他基于概率和置信度的方法。值得注意的是,我们的回归模型相对于CORC数据集上的对象检测,在Faster RCNN上实现了1.9 AP的改进,并在应用于边界框回归时在视觉跟踪方面设置了新的技术水平。 |
| RLBench: The Robot Learning Benchmark & Learning Environment Authors Stephen James, Zicong Ma, David Rovick Arrojo, Andrew J. Davison 我们为机器人学习RLBench提出了具有挑战性的新基准和学习环境。该基准测试具有100个完全独特的手工设计任务,难度范围很广,从简单的目标到达和开门到更长的多阶段任务,例如打开烤箱并在其中放入托盘。我们提供了一系列本体感受性观察和视觉观察,包括来自肩膀上的立体摄像机和手持单眼摄像机的rgb,深度和分段蒙版。独特的是,通过使用运动计划器,每项任务都提供了无限的演示,这些运动计划器在任务创建期间指定的一系列航路点上进行操作,从而实现了一系列令人兴奋的基于演示的学习。 RLBench的设计考虑了可伸缩性,可以轻松创建新任务及其运动计划的演示,然后通过一系列工具进行验证,从而允许用户将自己的任务提交到RLBench任务存储库。这个大型基准旨在加速视觉引导操纵研究领域的进展,包括强化学习,模仿学习,多任务学习,几何计算机视觉,尤其是很少的镜头学习。借助基准测试任务和演示的广度,我们提出了机器人技术中的第一个大规模少击挑战。我们希望RLBench的规模和多样性为机器人学习社区及其他领域提供无与伦比的研究机会。 |
| Smart Ternary Quantization Authors Gr goire Morin, Ryan Razani, Vahid Partovi Nia, Eyy b Sari 神经网络模型需要大量资源。低位量化(例如二进制和三进制量化)是减轻这种资源需求的常用方法。三元量化提供了更灵活的模型,并且在准确性方面经常优于二元量化,但使内存增加了一倍,并增加了计算成本。另一方面,混合量化深度模型允许在精度和内存占用之间进行权衡。在这样的模型中,量化深度通常是手动选择的,这很累人,或者使用单独的优化例程进行调整,这需要多次训练量化网络。在这里,我们提出了智能三元量化STQ,其中我们通过自适应正则化函数直接修改量化深度,因此我们只训练一次模型。该方法在训练时在二进制和三进制量化之间跳转。我们展示了其在图像分类中的应用。 |
| Towards neural networks that provably know when they don't know Authors Alexander Meinke, Matthias Hein 最近显示,ReLU网络在远离训练数据的自信预测中任意产生。因此,ReLU网络不知道何时不知道。但是,这在安全关键型应用中是非常重要的属性。在无分布检测OOD的背景下,已经提出了许多缓解该问题的建议,但是没有一个能够提供任何数学上的保证。在本文中,我们提出了一种克服OOD的新方法。我们的方法可以与ReLU网络一起使用,并提供远离训练数据的可证明的低置信度预测,以及出站点附近的低置信度预测的第一份证书。在实验中,我们表明,最先进的方法在这种最坏的情况下会失败,而我们的模型可以保证其性能,同时保持最先进的OOD性能。 |
| Two-stage Image Classification Supervised by a Single Teacher Single Student Model Authors Jianhang Zhou, Shaoning Zeng, Bob Zhang 两阶段策略已广泛用于图像分类。但是,这些方法在第二预测阶段几乎没有考虑第一阶段的分类标准。在本文中,我们提出了一种新颖的两阶段表示方法TSR,并将其转换为我们的两阶段图像分类框架中的单师单身学生STSS问题。我们寻找测试样本的最近邻居以选择候选目标类别。同时,将第一级分类器制定为教师,该分类器拥有分类分数。在第二阶段,利用候选类的样本来学习基于L2最小化的学生分类器。学生会受到老师分类器的监督,老师分类器只有获得更高的分数才批准学生。实际上,所提出的框架通过以新颖的方式暂存两个较弱的分类器而生成了较强的分类器。在多个面部和对象数据库上进行的实验表明,我们提出的框架是有效的,并且优于多种流行的分类方法。 |
| Balancing Domain Gap for Object Instance Detection Authors Woo han Yun, Jaeyeon Lee, Jaehong Kim, Junmo Kim 在混乱的室内环境中进行对象实例检测是服务机器人的核心功能。如果我们有大量带注释的数据集,我们可以通过遵循近期成功的深度卷积神经网络策略来轻松构建检测系统。但是,在只有少量样本可用的实例检测问题中,很难准备如此庞大的数据集。这是部署对象检测系统的主要障碍之一。为了克服这个障碍,已经提出了许多生成综合数据集的方法。这些方法都面临领域差距或现实差距问题,原因在于源领域综合训练数据集与目标领域真实测试数据集之间的差异。在本文中,我们提出了一种简单的方法来以最少的人力来生成综合数据集。特别是,我们确定前景和背景的领域差距是不平衡的,并提出了平衡这些差距的方法。在实验中,我们验证了我们的方法可以帮助域间隙平衡并提高在杂乱的室内环境中进行对象实例检测的准确性。 |
| StacNAS: Towards stable and consistent optimization for differentiable Neural Architecture Search Authors Guilin Li, Xing Zhang, Zitong Wang, Zhenguo Li, Tong Zhang 神经体系结构搜索的早期方法计算量很大。最近提出的差分神经体系结构搜索算法(例如DARTS)可以有效地加快计算速度。但是,当前的提法依赖于原始问题的缓解,这会导致不稳定和次优的解决方案。我们认为这些问题是由以下三个基本原因引起的:1双级优化的难度2相关操作(例如最大池和平均池)的多重共线性3搜索阶段的优化复杂度与最终训练之间的差异。在本文中,我们提出了一种基于一级优化的分组变量修剪算法,从而为可区分的NAS提供了更加稳定和一致的优化解决方案。大量实验证明了该方法在准确性和稳定性方面的优越性。我们的新方法可在CIFAR 10,CIFAR 100和ImageNet上获得最先进的精度。 |
| Segmentation of points of interest during fetal cardiac assesment in the first trimester from color Doppler ultrasound Authors Ruxandra Stoean, Dominic Iliescu, Catalin Stoean 本文提出了一项早期研究,该研究使用基于Zernike矩的传统分割方法从孕早期彩色多普勒检查的胎儿超声心动图框架中提取重要特征。然后在获得的指标上使用基于距离的方法对正常心脏条件下应出现的三个给定类别的帧进行分类。该计算工具显示出有希望在筛查期间支持产科医生快速识别心脏视图。 |
| Classification of Histopathological Biopsy Images Using Ensemble of Deep Learning Networks Authors Sara Hosseinzadeh Kassani, Peyman Hosseinzadeh Kassani, Michal J. Wesolowski, Kevin A. Schneider, Ralph Deters 乳腺癌是全世界女性死亡的主要原因之一。这类癌症的早期诊断对于治疗和患者护理至关重要。使用卷积神经网络CNN的计算机辅助检测CAD系统可以帮助进行异常分类。在这项研究中,我们提出了一种基于集合深度学习的方法来对乳房组织学图像进行自动二进制分类。提出的集成模型采用了三个预先训练的CNN,即VGG19,MobileNet和DenseNet。集成模型用于特征表示和提取步骤。然后将提取的特征输入到多层感知器分类器中,以执行分类任务。各种预处理和CNN调整技术(例如污点归一化,数据扩充,超参数调整和微调)用于训练模型。该方法在四个公共基准数据集(即ICIAR,BreakHis,PatchCamelyon和Bioimaging)上得到了验证。所提出的多模型集成方法获得的预测优于单个分类器和机器学习算法,其针对BreakHis,ICIAR,PatchCamelyon和Bioimaging数据集的准确度分别为98.13、95.00、94.64和83.10。 |
| A Hybrid Deep Learning Architecture for Leukemic B-lymphoblast Classification Authors Sara Hosseinzadeh Kassani, Peyman Hosseinzadeh kassani, Michal J. Wesolowski, Kevin A. Schneider, Ralph Deters 由于组织病理学结构的复杂性,在显微图像中自动检测白血病B淋巴母细胞癌非常具有挑战性。为了解决此问题,需要一种自动且强大的诊断系统来进行早期检测和治疗。在本文中,提出了一种基于自动深度学习的方法来区分未成熟的白血病母细胞和正常细胞。所提出的基于深度学习的混合方法通过不同的数据增强技术得到了丰富,能够从输入图像中提取高级特征。结果表明,所提出的模型比单个模型对白血病B淋巴母细胞分类的预测效果更好,总体准确度为96.17,敏感性为95.17,特异性为98.58。融合从中间层提取的特征,我们的方法有可能改善整体分类性能。 |
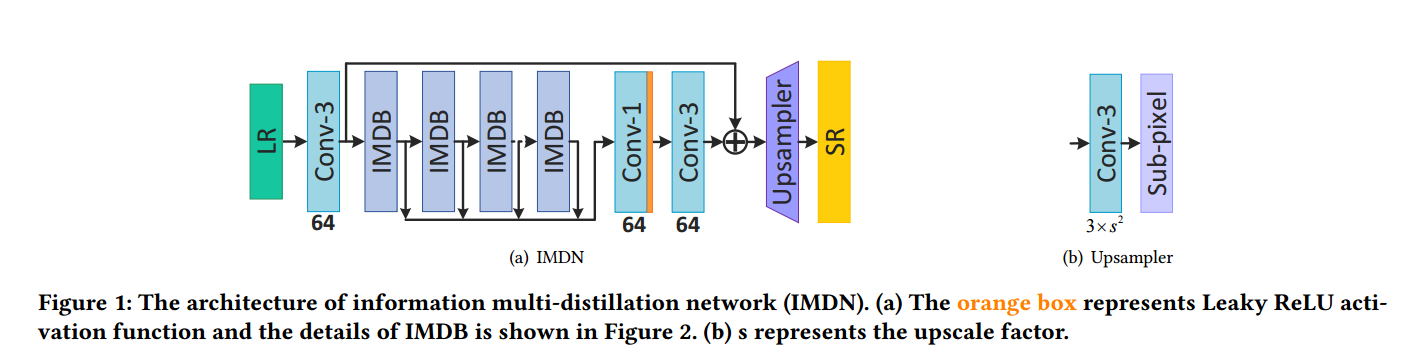
| Lightweight Image Super-Resolution with Information Multi-distillation Network Authors Zheng Hui, Xinbo Gao, Yunchu Yang, Xiumei Wang 近年来,使用深度卷积神经网络CNN的单图像超分辨率SISR方法取得了令人瞩目的成果。由于深层网络具有强大的表示能力,许多以前的方法都可以学习低分辨率LR图像斑块与高分辨率HR版本之间的复杂非线性映射。但是,过度的卷积将限制超分辨率技术在低计算能力设备中的应用。此外,在实际应用中任何任意比例因子的超分辨率都是一个关键问题,在以前的方法中还没有很好地解决。为了解决这些问题,我们通过构造包含蒸馏和选择性融合部分的级联信息多元蒸馏模块IMDB,提出了一种轻量级的信息多元蒸馏网络IMDN。具体来说,蒸馏模块会逐步提取分层特征,然后融合模块会根据候选特征的重要性对它们进行聚合,并通过拟议的对比度感知通道注意机制对其进行评估。为了处理任何尺寸的真实图像,我们开发了一种自适应裁剪策略ACS,以使用相同的训练有素的模型来超级分解逐块图像块。大量实验表明,在视觉质量,内存占用量和推理时间方面,所提出的方法相对于最新的SR算法表现良好。网址中提供了代码 |
| Unsupervised Universal Self-Attention Network for Graph Classification Authors Dai Quoc Nguyen, Tu Dinh Nguyen, Dinh Phung 现有的图嵌入模型通常在利用图结构相似性,节点之间的潜在依赖关系以及全局网络属性方面存在弱点。为此,我们提出了U2GAN,这是一种新颖的无监督模型,它利用了最近引入的通用自我关注网络Dehghani等人的力量2019,以学习可用于图分类的图的低维嵌入。特别地,给定一个输入图,U2GAN首先应用自我关注计算,然后进行递归转换以迭代地记住其对每次迭代中每个节点及其邻居的向量表示的关注。因此,U2GAN可以解决现有模型中的弱点,以产生合理的节点嵌入,其总和是整个图的最终嵌入。实验结果表明,我们的无监督U2GAN在一系列众所周知的用于图形分类任务的基准数据集上产生了最新的性能。在大多数基准案例中,它甚至优于监督方法。 |
| Breast Cancer Diagnosis with Transfer Learning and Global Pooling Authors Sara Hosseinzadeh Kassani, Peyman Hosseinzadeh Kassani, Michal J. Wesolowski, Kevin A. Schneider, Ralph Deters 乳腺癌是全世界女性与癌症相关的死亡的最常见原因之一。早期准确诊断乳腺癌可以显着提高患者的生存率。在这项研究中,我们旨在开发一种基于深度学习的全自动方法,该方法使用由深度卷积神经网络DCNN模型提取的描述符特征以及合并操作来对苏木精和曙红染色的HE组织学乳腺癌图像进行分类,这是该方法的一部分。国际图像分析与识别大会ICIAR 2018乳腺癌组织学BACH图像挑战赛。应用了不同的数据增强方法来优化DCNN性能。我们还研究了不同的污渍归一化方法作为预处理步骤的功效。使用预先训练的Xception模型的拟议网络体系结构可产生92.50的平均分类精度。 |
| Unsupervised Domain Adaptation through Self-Supervision Authors Yu Sun, Eric Tzeng, Trevor Darrell, Alexei A. Efros 本文介绍了无监督域自适应,即在源域上有标签训练数据可用的设置,但目标是在仅包含无标签数据的目标域上具有良好的性能。像以前的许多工作一样,我们力求使源域和目标域的学习表示保持一致,同时保留可分辨性。我们完成对齐的方式是通过学习在两个域上同时执行辅助的自我监督任务。每个自我监督的任务都将两个域沿着与该任务相关的方向拉近。与主要任务分类器一起在源域上进行训练,可以成功地将其推广到未标记的目标域。提出的目标易于实现且易于优化。我们在七个标准基准中的四个基准上获得了最先进的结果,在细分适应方面也获得了竞争性结果。我们还证明了我们的方法与另一种流行的像素级自适应方法组成良好。 |
| LAVAE: Disentangling Location and Appearance Authors Andrea Dittadi 1 , Ole Winther 1 and 2 and 3 1 Technical University of Denmark, 2 Copenhagen University Hospital, 3 University of Copenhagen 我们提出了一种概率生成模型,用于无监督学习视觉场景的结构化,可解释性,基于对象的表示形式。我们使用摊余的变分推理来训练生成模型的端到端。所学习的对象位置和外观表示完全被解开,并且在潜在空间中对象彼此独立表示。与先前的方法无法区分位置和外观的方法不同,我们的方法可以无缝地将场景概括为训练对象中遇到的物体更多的场景。我们在多MNIST和多dSprites数据集上评估提出的模型。 |
| A fast, complete, point cloud based loop closure for LiDAR odometry and mapping Authors Jiarong Lin, Fu Zhang 本文提出了一种闭环方法,可以校正LiDAR测距和映射LOAM中的长期漂移。我们提出的方法计算关键帧的2D直方图,局部地图补丁,并使用2D直方图的归一化互相关作为当前关键帧与地图中关键帧之间的相似性度量。我们证明了该方法快速,不变于旋转并且产生可靠且准确的回路检测。所提出的方法经过精心的工程实施,并集成到LOAM算法中,形成了一个完整实用的系统,可供使用。为了通过提供闭环基准来使社区受益,整个系统在Github上开源 |
| Data consistency networks for (calibration-less) accelerated parallel MR image reconstruction Authors Jo Schlemper, Jinming Duan, Cheng Ouyang, Chen Qin, Jose Caballero, Joseph V. Hajnal, Daniel Rueckert 通过扩展CNN的深层级联并利用数据一致性层,我们提出了用于多线圈数据的简单重构网络。特别是,我们提出了两种变体,其中一种是受POCSENSE启发,而另一种则是较少的校准。我们表明,所提出的方法相对于现有技术在数量和质量上都具有竞争力。 |
| "Good Robot!": Efficient Reinforcement Learning for Multi-Step Visual Tasks via Reward Shaping Authors Andrew Hundt, Benjamin Killeen, Heeyeon Kwon, Chris Paxton, Gregory D. Hager 为了有效学习,机器人必须能够提取无形的上下文,从而定义任务的进度和错误。在强化学习领域,许多信息是由奖励功能提供的。因此,奖励整形是我们如何在复杂的多步骤任务中获得最新结果的必要部分。但是,相对较少的工作检查了应如何进行奖励整形以使其能够捕获任务上下文,特别是在任务期限长且失败后果严重的情况下。我们的“积极任务SPOT奖励计划”训练了我们的有效视觉任务EVT模型,以解决需要了解任务上下文和多步骤块安排任务的工作空间约束的问题。在模拟中,EVT可以通过推动和抓紧99个案例(相对于先前工作中的82个基线)来完全清除对象的对抗性安排。对于随机安排,EVT清除100个测试用例,其动作效率为86,而以前的工作效率为61。与单独使用EVT的5个基准相比,EVT SPOT还能够证明74个试验中的上下文理解和完整堆栈。就我们所知,这是成功完成此类挑战的基于强化学习的算法的第一个实例。代码位于 |
| Deep-learning-based Breast CT for Radiation Dose Reduction Authors Wenxiang Cong, Hongming Shan, Xiaohua Zhang, Shaohua Liu, Ruola Ning, Ge Wang 锥形束乳腺计算机断层扫描CT提供具有各向同性分辨率和高对比度信息的真实3D乳腺图像,可检测小至几百微米的钙化并显示出细微的组织差异。但是,乳房对X射线辐射高度敏感。减少辐射剂量对于医疗保健至关重要。很少有视锥束CT仅使用标准锥束乳腺CT采集的X射线投影数据的一部分,从而可以显着降低辐射剂量。但是,采样数据不足会在使用常规方法重建的CT图像中造成严重的条纹伪影。在这项研究中,我们提出了一种基于深度学习的方法来建立残差神经网络模型以进行图像重建,该方法适用于少数视图乳腺CT以产生高质量的乳腺CT图像。我们分别使用标准锥形束乳腺CT的X射线投影视图的三分之一和四分之一来评估基于深度学习的图像重建。基于临床乳房成像数据集,我们执行有监督的学习,以将神经网络从少量的CT图像训练为相应的完整的CT图像。实验结果表明,基于深度学习的图像重建方法几乎没有视线乳腺CT能够实现每次锥束CT扫描6 mGy的辐射剂量,这是FDA为乳腺X线检查设置的阈值。 |
| Chinese Abs From Machine Translation |


{kind=link}