本文主要是通过程序来学习python 中sklearn的LinearRegression线性回归这一函数的基本操作和使用,注意不是用python纯粹从头到尾自己构建线性回归,既然sklearn提供了现成的我们直接拿来用就可以了,至于线性回归的原理非常简单,这里不做进一步解释(可以参考https://blog.csdn.net/sxf1061926959/article/details/66976356?fps=1&locationNum=9)
LinearRegression的使用非常简单,主要分为两步:
一:使用 fit(x_train,y_train)对训练集x, y进行训练。
二:使用predict(x_test) 训练得到的估计器对输入为x_test的集合进行预测(x_test可以是测试集,也可以是需要预测的数 据)。
本次用的源数据是 datasets.load_diabetes数据,这是一个糖尿病的数据集,data部分主要包括442行数据,10个属性值,分别是:Age(年龄)、性别(Sex)、Body mass index(体质指数)、Average Blood Pressure(平均血压)、S1~S6一年后疾病级数指标;Target为一年后患疾病的定量指标。为了后面绘图方便本程序中只用了data中的一个参数作为自变量(实际自变量中并不限于一个属性或特征值)
代码如下:
#LinearRegression线性回归
from sklearn import datasets,linear_model
import matplotlib.pyplot as plt
import numpy as np
import matplotlib as mpl
diabetes=datasets.load_diabetes()
diabetes_x=diabetes.data[:,np.newaxis ,2] #取第三列数据
diabetes_x_train=diabetes_x[:-20]
diabetes_x_test=diabetes_x[-20:]
diabetes_y_train=diabetes.target[:-20]
diabetes_y_test=diabetes.target[-20:]
#核心代码
regr=linear_model.LinearRegression()
regr.fit(diabetes_x_train,diabetes_y_train) #用训练集进行训练模型
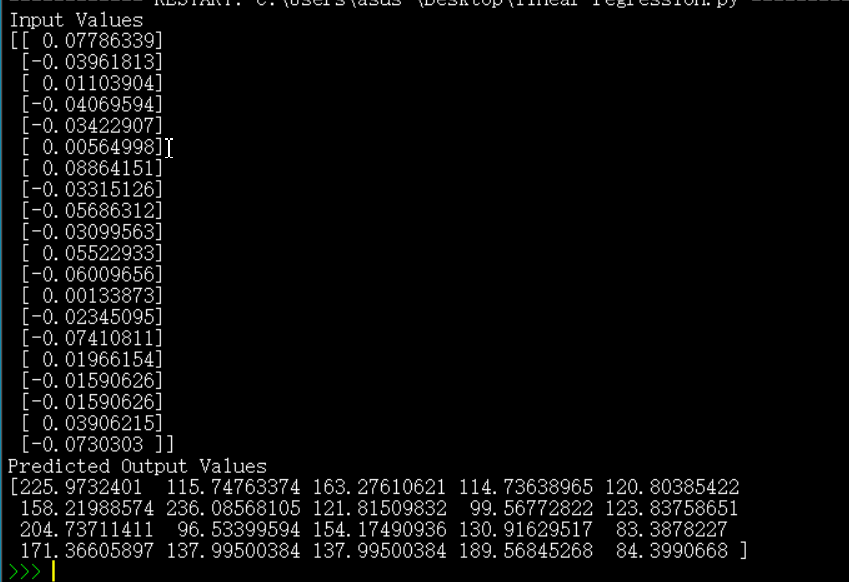
print('Input Values')
print(diabetes_x_test)
#核心代码
diabetes_y_pred=regr.predict(diabetes_x_test)
print('Predicted Output Values')
print(diabetes_y_pred)
#绘图
mpl.rcParams['font.sans-serif'] = [u'SimHei'] #用来正常显示中文标签
mpl.rcParams['axes.unicode_minus'] = False #用来正常显示负号
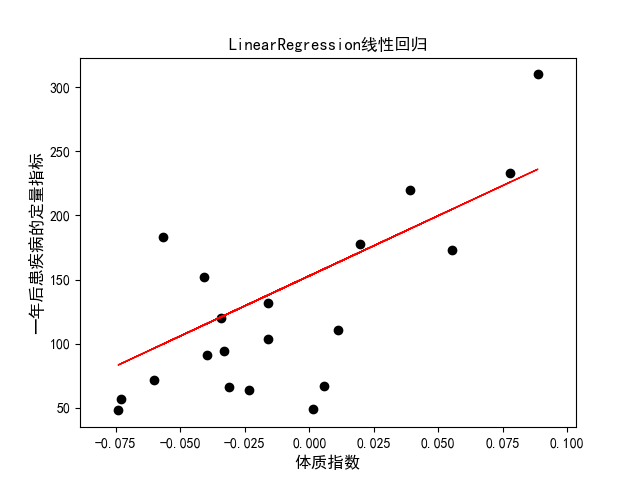
plt.scatter(diabetes_x_test,diabetes_y_test,color='black')
plt.plot(diabetes_x_test,diabetes_y_pred,color='red',linewidth=1)
plt.xlabel('体质指数', fontsize=12)
plt.ylabel('一年后患疾病的定量指标', fontsize=12)
plt.title(u'LinearRegression线性回归', fontsize=12)
plt.show()
运行结果:
更多算法可以参看博主其他文章,或者github:https://github.com/Mryangkaitong/python-Machine-learning