以下链接是个人关于FSA-Net(头部姿态估算) 所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:a944284742相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。
姿态估计1-00:FSA-Net(头部姿态估算)-目录-史上最新无死角讲解
前言
通过上篇博客,我们详细的讲解了lib/FSANET_model.py中的如下代码:
# 根据参数,确定是否构建论文中Scoring模型,输入三个[b,8,8,64],得到一个[b,3*7,64]
if self.is_noS_model:
# 三个[b,8,8,64]输入, 链接到一起成为[b,192,64]输出
ssr_S_model = self.ssr_noS_model_build()
else:
# 如果构建Scoring模型,其有两种方式,分别为使用1x1的卷积,或者通过方差计算
# 三个[b, 8, 8, 64]输入, num_primcaps参数为192,
# 输出[b,21,64]
ssr_S_model = self.ssr_S_model_build(num_primcaps=self.num_primcaps,m_dim=self.m_dim)
对应论文图示的如下部分:
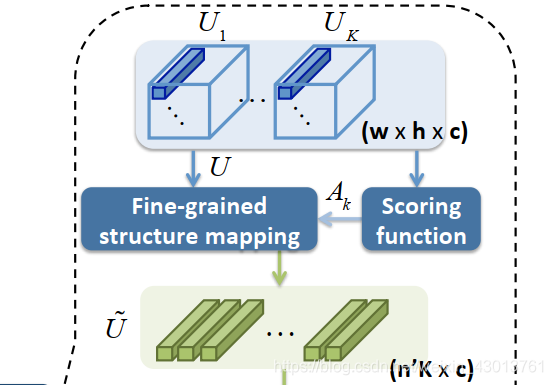
现在我们就来看看如下部分:
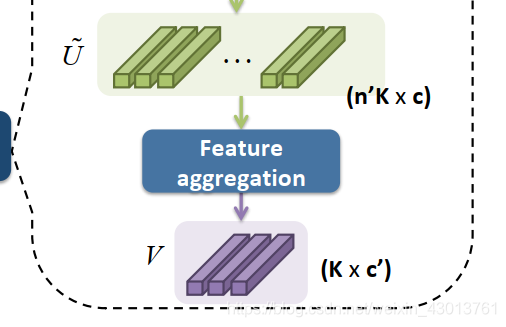
对应源码如下:
# 通过Feature aggregation得到三个特征向量,可以选择选择两种方式进行姿态估算
# self.F_shape默认为16,刚好耦合上个模型的输出,即输入为3个[b,16]
# 输出共九个结果,3个[b,3,3] 6个[b,3]
if self.is_fc_model:
# 直接使用对每个特征进行全连接层
ssr_F_Cap_model = self.ssr_FC_model_build(self.F_shape,'ssr_F_Cap_model')
else:
# 对每个特征进行合适的分割之后,再进行全链接
ssr_F_Cap_model = self.ssr_F_model_build(self.F_shape,'ssr_F_Cap_model')
两个函数的实现如下:
# 构建ssr_F_model模型
def ssr_F_model_build(self, feat_dim, name_F):
input_s1_pre = Input((feat_dim,))
input_s2_pre = Input((feat_dim,))
input_s3_pre = Input((feat_dim,))
def _process_input(stage_index, stage_num, num_classes, input_s_pre):
# [b,16] --> [b,4] --> [b,3], 使用tanh激活函数,输出结果为[-1,1]之间
# 可以看到delta_s输出的维度只和num_classes右关系
feat_delta_s = FeatSliceLayer(0,4)(input_s_pre)
delta_s = Dense(num_classes,activation='tanh',name=f'delta_s{stage_index}')(feat_delta_s)
# [b,16] --> [b,4] --> [b,3] 使用tanh激活函数,输出结果为[-1,1]之间
# 可以看到local_s输出的维度只和num_classes右关系
feat_local_s = FeatSliceLayer(4,8)(input_s_pre)
local_s = Dense(units=num_classes, activation='tanh', name=f'local_delta_stage{stage_index}')(feat_local_s)
# [b,16] --> [b,4] --> [b,3,3], 使用rlu函数,每个元素其结果大于0
# 可以看到pred_s,是和num_classes,以及stage_num有关系的
feat_pred_s = FeatSliceLayer(8,16)(input_s_pre)
feat_pred_s = Dense(stage_num*num_classes,activation='relu')(feat_pred_s)
pred_s = Reshape((num_classes,stage_num))(feat_pred_s)
# [b,3], [b,3], [b,3,3]
return delta_s, local_s, pred_s
# 输入为[b,16] --> 输出[b,3], [b,3], [b,3,3]
delta_s1, local_s1, pred_s1 = _process_input(1, self.stage_num[0], self.num_classes, input_s1_pre)
delta_s2, local_s2, pred_s2 = _process_input(2, self.stage_num[1], self.num_classes, input_s2_pre)
delta_s3, local_s3, pred_s3 = _process_input(3, self.stage_num[2], self.num_classes, input_s3_pre)
# 输入为[b,16] --> 输出[b,3,3], [b,3], [b,3],
# 前三个形状为pred_s1,pred_s2,pred_s3[b,3,3], 为论文中的p
# 中间三个为delta_s1,delta_s2,delta_s3形状为[b,3],为论文中的Δ
# 后面三个为local_s1,local_s2,local_s3,为论文的的η
return Model(inputs=[input_s1_pre,input_s2_pre,input_s3_pre],outputs=[pred_s1,pred_s2,pred_s3,delta_s1,delta_s2,delta_s3,local_s1,local_s2,local_s3], name=name_F)
# 构建ssr_FC_model模型
def ssr_FC_model_build(self, feat_dim, name_F):
# 输入为3个[b,16]
input_s1_pre = Input((feat_dim,))
input_s2_pre = Input((feat_dim,))
input_s3_pre = Input((feat_dim,))
# 输入为[b,16], 输出为分为[b,3], [b,3], [b,3,3]
def _process_input(stage_index, stage_num, num_classes, input_s_pre):
# [b,16] --> [b,6] --> [b,3] 使用tanh激活函数,输出结果为[-1,1]之间
# 可以看到delta_s输出的维度只和num_classes右关系
feat_delta_s = Dense(2*num_classes,activation='tanh')(input_s_pre)
delta_s = Dense(num_classes,activation='tanh',name=f'delta_s{stage_index}')(feat_delta_s)
# [b,16] --> [b,6] --> [b,3] 使用tanh激活函数,输出结果为[-1,1]之间
# 可以看到local_s输出的维度只和num_classes右关系
feat_local_s = Dense(2*num_classes,activation='tanh')(input_s_pre)
local_s = Dense(units=num_classes, activation='tanh', name=f'local_delta_stage{stage_index}')(feat_local_s)
# [b,16] --> [b,3,3] 使用rlu函数,每个元素其结果大于0
# 可以看到pred_s,是和num_classes,以及stage_num有关系的
feat_pred_s = Dense(stage_num*num_classes,activation='relu')(input_s_pre)
pred_s = Reshape((num_classes,stage_num))(feat_pred_s)
# [b,3], [b,3], [b,3,3]
return delta_s, local_s, pred_s
两个函数比较相似,大家看下注解即可,所以不做无谓的介绍了,我们只要知道该函数的功能,是为了获得论文中的 集合参数,也就是函数返回的delta_s, local_s, pred_s。下面,就是重点来了。
SSR算法
从前面,对于每个K=3个delta_s, local_s, pred_s,现在呢,要利用这些参数去计算头部姿态即yaw,pitch,roll。查看class BaseFSANet(object)中的_call__函数可以找到如下部分(后面有带读):
# 根据输入3个[b,3,3] 以及 6个[b,3],进行姿态计算
# 输出pred_pose[b,3], 默认的self.stage_num为[3,3,3], self.lambda_d=1
pred_pose = SSRLayer(s1=self.stage_num[0], s2=self.stage_num[1], s3=self.stage_num[2], lambda_d=self.lambda_d, name="pred_pose")(ssr_F_Cap_list)
该类的具体实现如下:
@register_keras_custom_object
class SSRLayer(Layer):
def __init__(self, s1, s2, s3, lambda_d, **kwargs):
super(SSRLayer, self).__init__(**kwargs)
self.s1 = s1
self.s2 = s2
self.s3 = s3
self.lambda_d = lambda_d
self.trainable = False
def call(self, inputs):
# x为包含九个元素的链表,
# 前三个形状为pred_s1,pred_s2,pred_s3[b,num_classes=3,stage_num=3], 为论文中的p,
# 中间三个为delta_s1,delta_s2,delta_s3形状为[b,3],为论文中的Δ,为了实现缩放
# 后面三个为local_s1,local_s2,local_s3,为论文的的η,为了实现偏移
x = inputs
# 把链表的第一个元素中,第0列全部清0,同样的值全复制给a,b,c,
# 这里没有什么意义,可以看做就是给a,b,c全部都复制为[b,3]形状
# 主要是保存K折之后,每个折区间的预测结果
a = x[0][:, :, 0] * 0
b = x[0][:, :, 0] * 0
c = x[0][:, :, 0] * 0
# 全为3
s1 = self.s1
s2 = self.s2
s3 = self.s3
# lambda_d是对论文中Δ参数的缩放,默认为1,即没有缩放
lambda_d = self.lambda_d
# 全为1, 这个地方为什么要除以2,比较模糊
di = s1 // 2
dj = s2 // 2
dk = s3 // 2
# 和论文中的公式不完全一致,代码是先把V提出来,
# 也就是所有大区间求和之后,再和V相乘,在没有乘以V之前,
# 都可以看做是对归一化结果的操作
V = 99
# 每折的p乘以和对应的u相乘,
# u分为两步计算,先计算偏移量n,再计算其缩放大小Δ
# 该折对应的阶段区间大约为[0,33],[33,66],[66,99]----(注意,非归一化,即乘以V=99后的结果)
for i in range(0, s1):
a = a + (i - di + x[6]) * x[0][:, :, i]
a = a / (s1 * (1 + lambda_d * x[3]))
# 该折对应的阶段区间大约为
# [0,11],[11,22],[22,33],[33,44],[44,55],[55,66],[66,77],[77,88],[88,99]
# (注意,非归一化,即乘以V=99后的结果)
for j in range(0, s2):
b = b + (j - dj + x[7]) * x[1][:, :, j]
# [b,3]
b = b / (s1 * (1 + lambda_d * x[3])) / (s2 * (1 + lambda_d * x[4]))
# 太多了,不写了
for k in range(0, s3):
c = c + (k - dk + x[8]) * x[2][:, :, k]
# [b,3]
c = c / (s1 * (1 + lambda_d * x[3])) / (s2 * (1 + lambda_d * x[4])) / (
s3 * (1 + lambda_d * x[5]))
# [b,3]
pred = (a + b + c) * V
return pred
def compute_output_shape(self, input_shape):
return (input_shape[0], 3)
def get_config(self):
config = {
's1': self.s1,
's2': self.s2,
's3': self.s3,
'lambda_d': self.lambda_d
}
base_config = super(SSRLayer, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
首先我把输入拿出来,如下所示:
# x为包含九个元素的链表,
# 前三个形状为pred_s1,pred_s2,pred_s3形状为[b,num_classes=3,stage_num=3], 为论文中的p,
# 中间三个为delta_s1,delta_s2,delta_s3形状为[b,3],为论文中的Δ,为了实现缩放
# 后面三个为local_s1,local_s2,local_s3形状为[b,3],为论文的的η,为了实现偏移
前面我推荐大家看一篇博客:
论文阅读-年龄估计_SSRNet:https://blog.csdn.net/oukohou/article/details/102676855
最终可以看到得出一个这样的公式:
这个公式和源码的实现,是有点区别的,源码计算的过程中把
作为一个公因式提出了出来,变成如下:
为了大家轻松的理解代码,我再把上面的的公式进行拆分:
花了我这么心思,别告诉我看不懂啊!现在呢,我们在变化一下:
那么可以得到:
是的,聪明的你,看到这个肯定就反应过来了,这里的
就是和源码中的 a,b,c 分别对应的,现在我们就来单独看看a:
其中
该处的实现,对应源码如下:
# 该折对应的阶段区间大约为[0,33],[33,66],[66,99]----(注意,非归一化,即乘以V=99后的结果)
for i in range(0, s1):
a = a + (i - di + x[6]) * x[0][:, :, i]
a = a / (s1 * (1 + lambda_d * x[3]))
源码中的lambda_d是对公式中
的一个缩放吗,并且默认为1,这样:
代码中的 s1 * (1 + lambda_d * x[3] ) 等于公式中的:
x[0][:, :, i] 等于公式中的
这样就全部都对应起来了,但是应该怎么理解呢?其实也很简单,就是在K=1折的时候,把0到99分成了3个阶段,
就是对应起每个阶段的概率,
就对应其每个阶段表示的姿态,但是呢?这个姿态并不是由一个数值表示,而是使用了偏移量
,和缩放
表示。知道了每个阶段估算的姿态,以及对应的概率,就可以求得对应的期望值。
a 表示在K=1处的期望值,b 表示K=2处的期望值, c表示K=3处的期望值。下面就剩下一个问题,为什么要a,b,c相加起来呢?是这样的,假设,
K=1处,进行第一次估算,以00处为基准,偏移期望值为22
k=2处,进行第二次估算,以上次偏移的22为基准,偏移期望值为5
k=3处,进行第二次估算,以上次偏移的5为基准,偏移期望值为1
因为每次,偏移期望值,都是以上一次的期望位置为基准,所以绝对期望值为他们相加,得到22+5+1=28.
结语
到这里为止,比较重要的地方,我们基本讲解完成了,但是大家注意,lib/FSANET_model.py中的类BaseFSANet中的_call_函数中调用了
ssr_aggregation_model = self.ssr_aggregation_model_build((self.num_primcaps,64))
函数,前面我提到,他是由子类实现的,那么下篇博客,我们就对他进行解析吧。点赞哈,本人除了脸皮厚,似乎也没啥优点了,就喜欢厚着脸皮叫别人点赞!
