以下链接是个人关于FSA-Net(头部姿态估算) 所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:a944284742相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。
姿态估计1-00:FSA-Net(头部姿态估算)-目录-史上最新无死角讲解
分析前言
我相信,大家跟到这里来,说明你以及看完论文了,既然如此,我们在来看看training_and_testing/run_fsanet_train.sh文件,这是我们训练的脚本内容如下:
.......
是的,我这里是空的,因为我觉得复制出来太臃肿,显得我的博客不够帅气,所以就不复制出来了,你看自己源码的即可。该文件可以看到如下字样的注释:
# Train on protocal 1
# SSRNET_MT
# FSANET_Capsule
# FSANET_Netvlad
# FSANET_Metric
# Train on protocal 2
# SSRNET_MT
# FSANET_Capsule
# FSANET_Netvlad
# FSANET_Metric
# Fine-tuned on BIWI with synhead pre-trained model
看完了论文的朋友应该就比较熟悉了,因为在论文中存在如下图示:
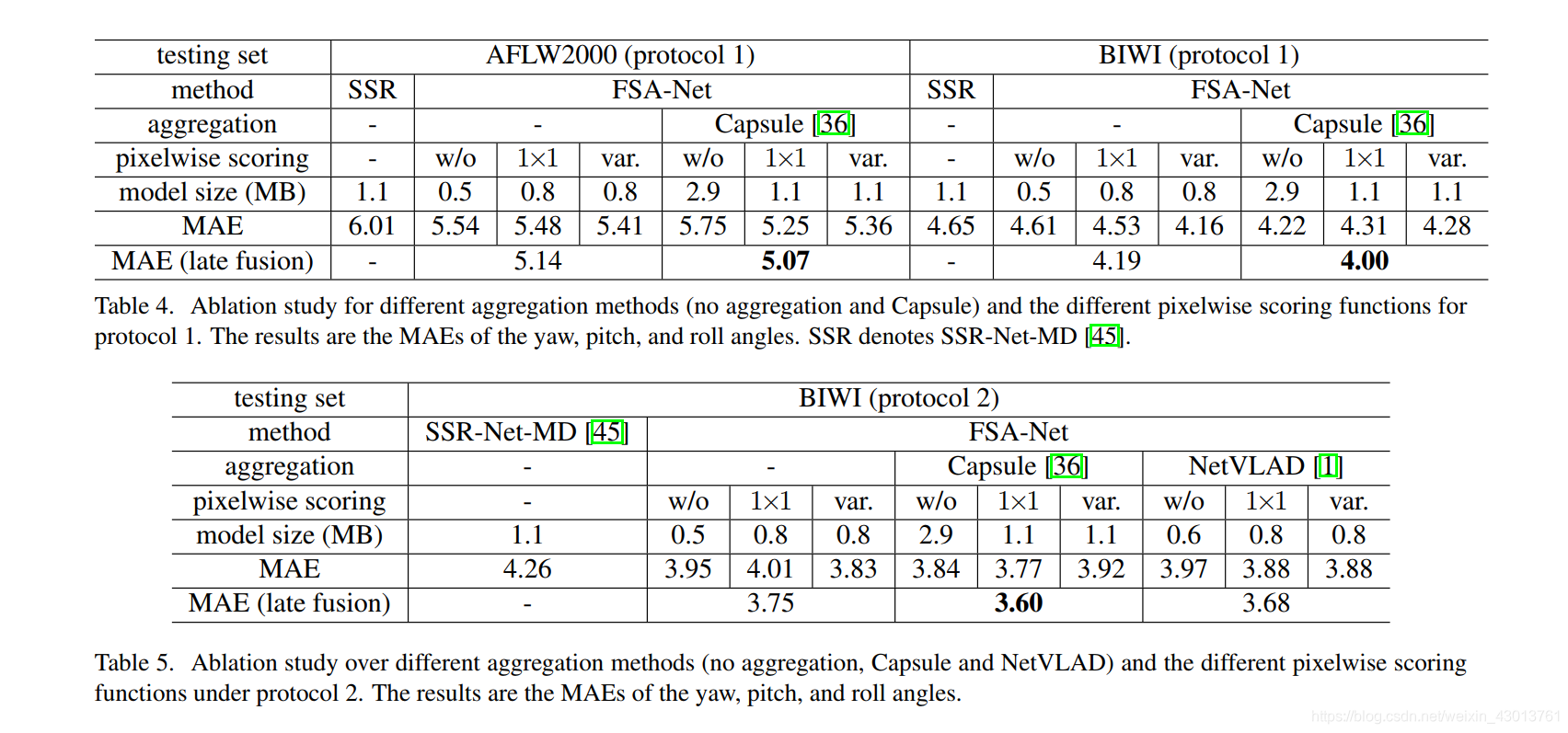
也就是说,作者需要执行多次训练脚本,全是为了为了完成实验的对比。那么我们在分析的时候,当然是选择效果最好的哪个进行分析。说得简单,但是现在我也没办法一眼就知道哪个效果最好,不过通过观察可以知道,他们主要的差别就是在于–model_type的参数不一样,其可以选择1到10之间。那么在分析源码的时候,着重分析其处理过程即可。
源码解析
源码注释:
import os
import sys
sys.path.append('..')
import logging
import argparse
import pandas as pd
import numpy as np
from lib.FSANET_model import *
from lib.SSRNET_model import *
import TYY_callbacks
from TYY_generators import *
from keras.utils import np_utils
from keras.utils import plot_model
from keras.optimizers import SGD, Adam
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import LearningRateScheduler, ModelCheckpoint
logging.basicConfig(level=logging.DEBUG)
def load_data_npz(npz_path):
d = np.load(npz_path)
return d["image"], d["pose"]
def mk_dir(dir):
try:
os.mkdir( dir )
except OSError:
pass
def get_args():
parser = argparse.ArgumentParser(description="This script trains the CNN model for head pose estimation.",
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument("--batch_size", type=int, default=16,
help="batch size")
parser.add_argument("--nb_epochs", type=int, default=90,
help="number of epochs")
parser.add_argument("--validation_split", type=float, default=0.2,
help="validation split ratio")
parser.add_argument("--model_type", type=int, default=3,
help="type of model")
parser.add_argument("--db_name", type=str, default='300W_LP',
help="type of model")
args = parser.parse_args()
return args
def main():
# 解析并且赋值相关参数
args = get_args()
db_name = args.db_name
batch_size = args.batch_size
nb_epochs = args.nb_epochs
validation_split = args.validation_split
model_type = args.model_type
image_size = 64
logging.debug("Loading data...")
# 如果训练的数据集为300W_LP
if db_name == '300W_LP':
# 获得对应的npz文件
db_list = ['AFW.npz','AFW_Flip.npz','HELEN.npz','HELEN_Flip.npz','IBUG.npz','IBUG_Flip.npz','LFPW.npz','LFPW_Flip.npz']
# 用于保存像素
image = []
# 用于保存姿态
pose = []
# 循环加入所有的图片像素,以及对应的姿态
for i in range(0,len(db_list)):
image_temp, pose_temp = load_data_npz('../data/type1/'+db_list[i])
image.append(image_temp)
pose.append(pose_temp)
# 把链表转化为np数组格式.
# 加载完数据之后为[122450, 64, 64, 3]
image = np.concatenate(image,0)
# 加载完数据之后为[122450, 3]
pose = np.concatenate(pose,0)
# 对于其角度不在[-99,99]之间的数据,全部剔除掉
# we only care the angle between [-99,99] and filter other angles
x_data = []
y_data = []
print(image.shape)
print(pose.shape)
for i in range(0,pose.shape[0]):
temp_pose = pose[i,:]
if np.max(temp_pose)<=99.0 and np.min(temp_pose)>=-99.0:
x_data.append(image[i,:,:,:])
y_data.append(pose[i,:])
x_data = np.array(x_data)
y_data = np.array(y_data)
print(x_data.shape)
print(y_data.shape)
elif db_name == 'synhead_noBIWI':
image, pose = load_data_npz('../data/synhead/media/jinweig/Data2/synhead2_release/synhead_noBIWI.npz')
x_data = image
y_data = pose
# 如果训练的数据集为BIWI
elif db_name == 'BIWI':
image, pose = load_data_npz('../data/BIWI_train.npz')
x_train = image
y_train = pose
image_test, pose_test = load_data_npz('../data/BIWI_test.npz')
x_test = image_test
y_test = pose_test
else:
print('db_name is wrong!!!')
return
# 训练到30ep和60ep会进行学习率衰减
start_decay_epoch = [30,60]
#优化器
optMethod = Adam()
# 论文中Stage的数目
stage_num = [3,3,3]
lambda_d = 1
# 输出姿态为yaw, pitch, roll
num_classes = 3
# 是否使用最好的方法
isFine = False
#根据model_type参数 进行模型构建
if model_type == 0:
model = SSR_net_ori_MT(image_size, num_classes, stage_num, lambda_d)()
save_name = 'ssrnet_ori_mt'
elif model_type == 1:
model = SSR_net_MT(image_size, num_classes, stage_num, lambda_d)()
save_name = 'ssrnet_mt'
elif model_type == 2:
num_capsule = 3
dim_capsule = 16
routings = 2
num_primcaps = 7*3
m_dim = 5
S_set = [num_capsule, dim_capsule, routings, num_primcaps, m_dim]
str_S_set = ''.join('_'+str(x) for x in S_set)
model = FSA_net_Capsule(image_size, num_classes, stage_num, lambda_d, S_set)()
save_name = 'fsanet_capsule'+str_S_set
elif model_type == 3:
#
num_capsule = 3
dim_capsule = 16
routings = 2
num_primcaps = 7*3
m_dim = 5
S_set = [num_capsule, dim_capsule, routings, num_primcaps, m_dim]
str_S_set = ''.join('_'+str(x) for x in S_set)
model = FSA_net_Var_Capsule(image_size, num_classes, stage_num, lambda_d, S_set)()
save_name = 'fsanet_var_capsule'+str_S_set
elif model_type == 4:
num_capsule = 3
dim_capsule = 16
routings = 2
num_primcaps = 8*8*3
m_dim = 5
S_set = [num_capsule, dim_capsule, routings, num_primcaps, m_dim]
str_S_set = ''.join('_'+str(x) for x in S_set)
model = FSA_net_noS_Capsule(image_size, num_classes, stage_num, lambda_d, S_set)()
save_name = 'fsanet_noS_capsule'+str_S_set
elif model_type == 5:
num_capsule = 3
dim_capsule = 16
routings = 2
num_primcaps = 7*3
m_dim = 5
S_set = [num_capsule, dim_capsule, routings, num_primcaps, m_dim]
str_S_set = ''.join('_'+str(x) for x in S_set)
model = FSA_net_NetVLAD(image_size, num_classes, stage_num, lambda_d, S_set)()
save_name = 'fsanet_netvlad'+str_S_set
elif model_type == 6:
num_capsule = 3
dim_capsule = 16
routings = 2
num_primcaps = 7*3
m_dim = 5
S_set = [num_capsule, dim_capsule, routings, num_primcaps, m_dim]
str_S_set = ''.join('_'+str(x) for x in S_set)
model = FSA_net_Var_NetVLAD(image_size, num_classes, stage_num, lambda_d, S_set)()
save_name = 'fsanet_var_netvlad'+str_S_set
elif model_type == 7:
num_capsule = 3
dim_capsule = 16
routings = 2
num_primcaps = 8*8*3
m_dim = 5
S_set = [num_capsule, dim_capsule, routings, num_primcaps, m_dim]
str_S_set = ''.join('_'+str(x) for x in S_set)
model = FSA_net_noS_NetVLAD(image_size, num_classes, stage_num, lambda_d, S_set)()
save_name = 'fsanet_noS_netvlad'+str_S_set
elif model_type == 8:
# 论文中
num_capsule = 3
# 论文中的c’=16
dim_capsule = 16
# 论文中的stream数目
routings = 2
# 论文中的n'=7,
num_primcaps = 7*3
# 论文中的m=5
m_dim = 5
S_set = [num_capsule, dim_capsule, routings, num_primcaps, m_dim]
str_S_set = ''.join('_'+str(x) for x in S_set)
model = FSA_net_Metric(image_size, num_classes, stage_num, lambda_d, S_set)()
save_name = 'fsanet_metric'+str_S_set
elif model_type == 9:
num_capsule = 3
dim_capsule = 16
routings = 2
num_primcaps = 7*3
m_dim = 5
S_set = [num_capsule, dim_capsule, routings, num_primcaps, m_dim]
str_S_set = ''.join('_'+str(x) for x in S_set)
model = FSA_net_Var_Metric(image_size, num_classes, stage_num, lambda_d, S_set)()
save_name = 'fsanet_var_metric'+str_S_set
elif model_type == 10:
num_capsule = 3
dim_capsule = 16
routings = 2
num_primcaps = 8*8*3
m_dim = 5
S_set = [num_capsule, dim_capsule, routings, num_primcaps, m_dim]
str_S_set = ''.join('_'+str(x) for x in S_set)
model = FSA_net_noS_Metric(image_size, num_classes, stage_num, lambda_d, S_set)()
save_name = 'fsanet_noS_metric'+str_S_set
# 指定模型的优化方法,以及loss(均值绝对误差)计算方式,
model.compile(optimizer=optMethod, loss=["mae"],loss_weights=[1])
logging.debug("Model summary...")
# 计算模型参数,打印模型结构
model.count_params()
model.summary()
logging.debug("Saving model...")
# 创建必要的目录,如保存模型的路径等等
mk_dir(db_name+"_models")
mk_dir(db_name+"_models/"+save_name)
mk_dir(db_name+"_checkpoints")
# 把模型绘画成图,便于分析(总体结构)
plot_model(model, to_file=db_name+"_models/"+save_name+"/"+save_name+".png")
# 绘画网络模型的细致结构
for i_L,layer in enumerate(model.layers):
if i_L >0 and i_L< len(model.layers)-1:
if 'pred' not in layer.name and 'caps' != layer.name and 'merge' not in layer.name and 'model' in layer.name:
plot_model(layer, to_file=db_name+"_models/"+save_name+"/"+layer.name+".png")
# 迭代到指定次数,进行学习率衰减
decaylearningrate = TYY_callbacks.DecayLearningRate(start_decay_epoch)
# 查看指定路径下的模型知否存在,存在则自动加载该目录下的模型
callbacks = [ModelCheckpoint(db_name+"_checkpoints/weights.{epoch:02d}-{val_loss:.2f}.hdf5",
monitor="val_loss",
verbose=1,
save_best_only=True,
mode="auto"), decaylearningrate
]
logging.debug("Running training...")
# 如果为'BIWI'数据集,则进行测试集和训练集的划分
if db_name != 'BIWI':
data_num = len(x_data)
indexes = np.arange(data_num)
np.random.shuffle(indexes)
x_data = x_data[indexes]
y_data = y_data[indexes]
train_num = int(data_num * (1 - validation_split))
x_train = x_data[:train_num]
x_test = x_data[train_num:]
y_train = y_data[:train_num]
y_test = y_data[train_num:]
elif db_name == 'BIWI':
train_num = np.shape(x_train)[0]
# 为模型绑定训练数据,测试数据,并且进行训练(真的是个讨厌的框架,用了pytorch之后,其他的框架越看越难受)
hist = model.fit_generator(generator=data_generator_pose(X=x_train, Y=y_train, batch_size=batch_size),
steps_per_epoch=train_num // batch_size,
validation_data=(x_test, y_test),
epochs=nb_epochs, verbose=1,
callbacks=callbacks)
logging.debug("Saving weights...")
model.save_weights(os.path.join(db_name+"_models/"+save_name, save_name+'.h5'), overwrite=True)
pd.DataFrame(hist.history).to_hdf(os.path.join(db_name+"_models/"+save_name, 'history_'+save_name+'.h5'), "history")
if __name__ == '__main__':
main()
360行,行行出状元,总得先有钱。三千大道归一大法,无非就是,加载数据,构建模型,训练数据,保存模型。没了,就这么通俗的总结一下。
通过代码的浏览,可以清楚地知道其复杂的地方,是模型的构建过程,具体细节下篇博客进行讲解。
