时间复杂度表示代码的执行时间随着数据规模增长的趋势。使用O()表示
【假设】每一行代码执行的时间都一样,都是unit_time。所有代码的总执行时间 T(n) 与每行代码的执行次数成正比。
1、只关注循环执行次数最多的一段代码
def calc(n):
"""
分析这个代码执行时间,(3+2n)*unit_time,去掉常量,去掉高阶的系数,从而得出时间复杂度就是O(n)
"""
total = 0 # 执行1次
for i in range(0, n + 1): # 执行n+1次
total = total + i # 执行n+1次
return total
再举一例子:
def combination(data: list):
"""
从一个列表中每次取出两个,找出所有组合方式。
分析这个代码执行时间,(1+n+2n*n)*unit_time,去掉常量、低阶、高阶的系数,从而得出时间复杂度就是O(n*n)
思考:前后顺序不同的组合算同一个,比如(1,3)和(3,1)算一个组合,该如何写?
"""
n = len(data) # 执行1次
for x in range(0, n): # 执行n次
for y in range(0, n): # 执行n*n次
print(data[x], data[y]) # 执行n*n次
3、乘法法则
嵌套代码的复杂度等于嵌套内外代码复杂度的乘积。
def geometric_progression(n: int) -> int:
"""
打印等比数列
i从1开始,每次循环乘以2,当大于n时结束循环。i其实是个等比数列,公比是2。循环次数是log2n,时间复杂度就是 O(log2n)。
不管是以 2 为底、以 3 为底,还是以 10 为底,我们把所有对数阶的时间复杂度都记为 O(logn)
"""
i = 1
while i <= n:
i = i * 2
print(i)
4、对数阶复杂度
def geometric_progression(n: int) -> int:
"""
打印等比数列
i从1开始,每次循环乘以2,当大于n时结束循环。i其实是个等比数列,公比是2。循环次数是log2n,时间复杂度就是 O(log2n)。
不管是以 2 为底、以 3 为底,还是以 10 为底,我们把所有对数阶的时间复杂度都记为 O(logn)
"""
i = 1
while i <= n:
i = i * 2
print(i)
5、复杂度由两个数据的规模来决定
def dependent_on_two_scale(m, n):
"""
从代码中可以看出,m 和 n 是表示两个数据规模。我们无法事先评估 m 和 n 谁的量级大,所以我们在表示复杂度的时候,就不能简单地利用加法法则,省略掉其中一个。
代码的复杂度由两个数据的规模来决定m和n。时间复杂度就是 O(m+n)
"""
sum_1 = 0
sum_2 = 0
for i in range(m):
sum_1 = sum_1 + i
for i in range(n):
sum_2 = sum_2 + i
return sum_1 + sum_2
6、递归算法时间复杂度分析
递归算法是时间复杂度超高的。
def fibonacci(n):
"""
求fibonacci的第n项。
递归算法复杂度分析。画递归树,比如fibonacci(6)如图。复杂度为O(2^N)
"""
if n == 0:
return 0
if n in [1, 2]:
return 1
return fibonacci(n - 1) + fibonacci(n - 2)
7、优化递归算法降低时间复杂度
def fibonacci_plus(n: int) -> int:
"""
斐波那契数列也可以从左到右依次求出每一项的值,那么通过顺序计算求得第N项即可。其时间复杂度为O(N)。
"""
a, b = 0, 1
if n < 2:
return n
for _ in range(2, n+1):
a, b = b, a + b
return b
8、最好、最差时间复杂度
代码在不同情况下的不同时间复杂度。最好情况时间复杂度就是,在最理想的情况下,执行这段代码的时间复杂度。最坏情况时间复杂度就是,在最糟糕的情况下,执行这段代码的时间复杂度。
def search(data: list, x: int) -> int:
"""
从无序数组中查找某个元素的下标。最好时间复杂度是O(1),最差时间复杂度是 O(n)
要查找的变量 x 可能出现在数组的任意位置。
如果数组中第一个元素正好是要查找的变量 x,那就不需要继续遍历剩下的 n-1 个数据了,那时间复杂度就是 O(1)。
但如果数组中不存在变量 x,那我们就需要把整个数组都遍历一遍,时间复杂度就成了 O(n)。
:param data: 无重复元素无序数组
:param x: 待寻找的元素
:return: x的下标
"""
length = len(data)
for i in range(length):
if data[i] == x:
return i
else:
return -1
9、加权平均时间复杂度
上面介绍了最好和最差的时间复杂度,都是比较极端的情况。那么平均的时间复杂度是多少呢?
查找变量x在data中的位置,有n+1中可能,处于0~n-1的下标,和不在data中。我们把每种情况下,查找时需要遍历的元素个数累加起来,然后再除以 n+1,就可以得到需要遍历的元素个数的平均值。(1+2+3…+n+n)/(n+1),省略掉系数、低阶、常量,所以,得到的平均时间复杂度就是 O(n)。
前面的推导过程中存在的最大问题就是,没有将各种情况发生的概率考虑进去。在数组中与不在数组中的概率都为 1/2。另外,要查找的数据出现在 0~n-1 这 n 个位置的概率也是一样的,为 1/n。
如果我们把每种情况发生的概率也考虑进去,那平均时间复杂度的计算过程就变成了这样: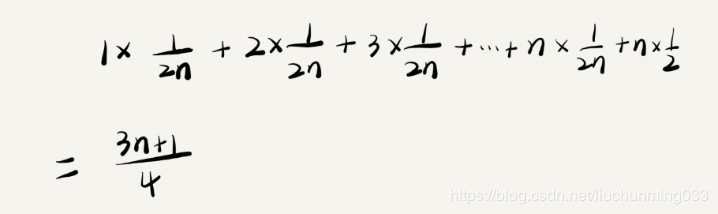
用大 O 表示法来表示,去掉系数和常量,这段代码的加权平均时间复杂度仍然是 O(n)。
10、空间复杂度分析
就看额外分配了多少内存。

def space_complexity(n: int):
"""
第 1 行申请了一个大小为 n 的 列表,除此之外,剩下的代码都没有占用更多的空间,所以整段代码的空间复杂度就是 O(n)。
"""
space = [0] * n # 申请了一个大小为 n 列表
for i in range(n):
space[i] = i * i
print(space)
11、总结
复杂度分析的实用方法:
只关注循环执行次数最多的一段代码;
加法法则:总复杂度等于量级最大的那段代码的复杂度;
乘法法则:嵌套代码的复杂度等于嵌套内外代码复杂度的乘积
复杂度由两个数据的规模来决定m和n时,时间复杂度是 O(m+n)
常见的时间复杂度:O(1)<O(logn)<O(n)<O(nlogn)<O(n*n)
空间复杂度分析比较简单,就看额外分配了多少内存就好。