K近邻
构建模型只需要保存训练数据集即可。想要对新数据点做出预测,算法会在训练数据集中找到最近的数据点,也就是它的“最近邻”。
1、K近邻分类
#第三步导入K近邻模型并实例化KN对象 from sklearn.neighbors import KNeighborsClassifier #其中n_neighbors为近邻数量 clf = KNeighborsClassifier(n_neighbors=3)
#第四步对训练集进行训练 clf.fit(X_train,y_train)
#查看训练集和测试集的精确度 clf.score(X_train,y_train)
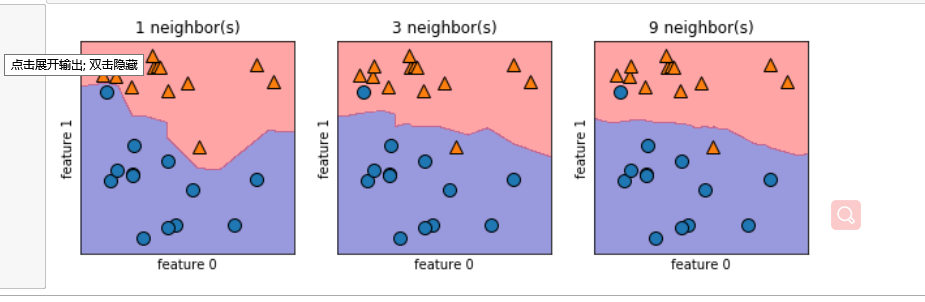
#建立一个有一行三列组成的图组,每个图的大小是10×3 fig, axes = plt.subplots(1,3,figsize=(10,3)) for n_neighbors,ax in zip([1,3,9],axes): #实例化模型对象并对数据进行训练 clf = KNeighborsClassifier(n_neighbors=n_neighbors).fit(X,y) mglearn.plots.plot_2d_separator(clf, X, fill=True, eps=0.5, ax=ax, alpha=.4) mglearn.discrete_scatter(X[:,0],X[:,1],y,ax=ax) ax.set_title("{} neighbor(s)".format(n_neighbors)) ax.set_xlabel("feature 0") ax.set_ylabel("feature 1")
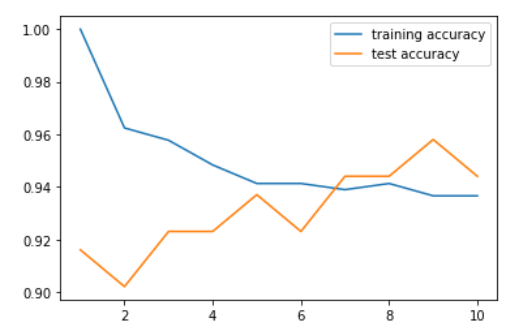
针对乳腺癌数据进行不同近邻的精确度分析
#加载乳腺癌数据 from sklearn.datasets import load_breast_cancer #提取数据 cancer = load_breast_cancer() #第一步将数据分为训练集和测试集 X_train,X_test,y_train,y_test = train_test_split(cancer.data,cancer.target,random_state = 0) #实例化不同近邻的KN对象 neighbors_settings = range(1,11) training_accuracy = [] test_accuracy = [] for n_neighbors in neighbors_settings: clf = KNeighborsClassifier(n_neighbors=n_neighbors).fit(X_train,y_train) training_accuracy.append(clf.score(X_train,y_train)) test_accuracy.append(clf.score(X_test,y_test)) plt.plot(neighbors_settings,training_accuracy,label='training accuracy') plt.plot(neighbors_settings,test_accuracy,label='test accuracy') plt.legend()
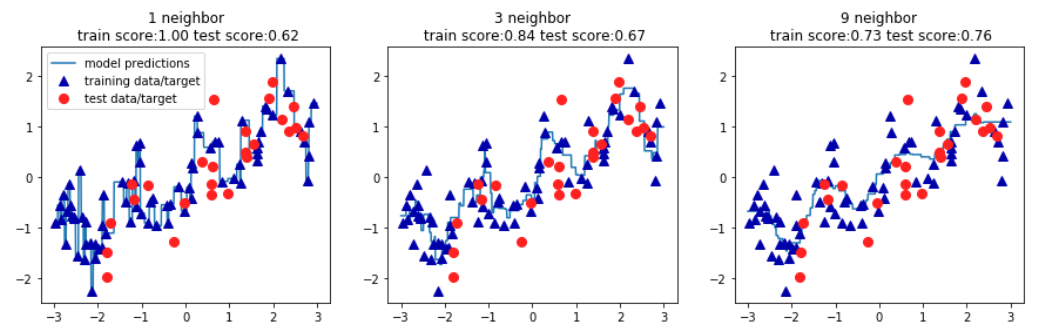
2、K近邻回归
针对wave数据进行K近邻回归演示
#导入wave数据 X,y = mglearn.datasets.make_wave() #将数据分为训练集和测试集 X_train,X_test,y_train,y_test = train_test_split(X,y, random_state = 0) #导入KN模型
from sklearn.neighbors import KNeighborsRegressor
#实例化KN模型
reg = KNeighborsRegressor(n_neighbors=3)
#对训练集进行训练
reg.fit(X_train,y_train)
#查看模型的精度
reg.score(X_test,y_test) #创建一个有一行三列组成的图组,每个图的大小为15×4 fig, axes = plt.subplots(1,3,figsize=(15,4)) #创建1000个数据点,分布在-3和3之间 lines=np.linspace(-3,3,1000).reshape(-1,1) for n_neighbors, ax in zip([1,3,9],axes): reg = KNeighborsRegressor(n_neighbors=n_neighbors).fit(X_train,y_train) ax.plot(lines,reg.predict(lines)) ax.plot(X_train,y_train,'^',c=mglearn.cm2(0),markersize=8) ax.plot(X_test,y_test,'o',c=mglearn.cm2(1),markersize=8) ax.set_title('{} neighbor\n train score:{:.2f} test score:{:.2f}'.format(n_neighbors,reg.score(X_train,y_train), reg.score(X_test,y_test))) axes[0].legend(['model predictions','training data/target','test data/target'])