分布式文件系统HDFS
第一章 统一思维
单机大数据处理实现以及问题
问题引入
问题
1T 文件,有数字,按行存储 ,每行不是特别长
要求
- 找出存在的重复行(假设只有两行)
- 全排序
- 单词重复数
环境
只有一台计算机 ,要求在 128M,64M,256G的环境下都能够运行
注意
内存不能放下全量数据 ,最大xxMB !!!
我的思路:
-
比较法, 通过比较每行第一个关键字 , 关键字相同的在放入第一个集合中
然后每个集合中比较第二个关键字, 然后在访问第二个集合…一次类推 , 直到找到两个完全相同的行 -
计数法 ,统计每行数据中字符出现的个数 ,从a开始比较到z,从1比较到10 , 最后所有字符个数相同的进行判断,
如果相同的只有两组, 那么这两行所在的就是重复行. 如果大于两组, 对大于的部分执行比较法 -
通过==或者equal进行比较 ,将每一行加上""或使用 ,变成一串字符串 , 然后通过java中的比较运算符或者equal方法进行比较
-
以字符数最少行的个数为比较标准, 从每行第1开字符开水比较最小行个数的字符 ,寻找这些字符都相等的行 ,
如果只有两行相等即所得 ,两行以上相等则对相等的行再次使用这种方法进行比较(迭代)
我的方法不是最好的, 但是一定会有更好的方法由大家想出!!
现在收集到的想法
明确
假设磁盘每秒读取500兆数据, 则1T内容需要2048s 约等于 30min
1.倒排索引
将所有出现的数字以及字母进行切词 ,切成一个个的关键字, 利用关键词建立一个索引库,
每个索引下记录它在这篇文章中出现的所有位置. 然后我们可以理解这个索引进行我们想做的操作(例如找重复行, 关键字等)
用时未知, 但是思路很好
2.hash/哈希算法
如下图, 按行读取数据, 采取hash算法对这一行数据做hash运算, 得到一串数字串 ,然后将数字串对10 0000(足够大)取余
可以知道余数为1-9 9999, 假设1T文件总字节数为n , n对10w取余商第一次得到 1 ,将之前的数字串都写入 1号小文件中
n对10w第二次取余商为1 ,将之前(第二个余数为1-9 9999)的数字串放入2号小文件中 ,依次类推 .
我们可以得到n 多个小文件 ,但是这些文件一定是有限个, 且内部有序外部无序 ,用时30min
如果是相同行 ,那么他们通过hash运算得到的数字串一样, 则对10w取余的余数一样 ,因此他们肯定在一个小文件中
我们暂时忽略极低情况导致不相同的行通过hash运算得到一样的字符串从而导致也在同一个小文件的情况
假设这些小文件足够小, 我们可以统计这些小文件的大小 , 放在1个大文件中排序 , 然后将排序后的值所对应行重新放入文件中
最差情况是我们在最后一个小文件才找到相同的那两行 ,用时也是30min ,整个过程用时1小时

3.分而治之,各个击破
这里假设这1T都是数字
仍是按行读取, 但是是统计数字个数 , 将每行数字个数为 1-100的放到 1号小文件 ,并且建立映射关系(一一对应)
将个数为 101-200 的放入 2号小文件中, 将个数为 201-300的放到3号小文件中… 依次类推(用时30min)
如此, 我们得到了n多个小文件(但是有限), 这些小文件内部无序 ,但是外部有序
我们可以将这些小文件进行内部排序, 然后放入一个大文件中
然后按照映射关系按顺序(正序或倒序)将每一行重新写入这个文件 ,得到一个大小和原来一样的文件(也是1T,用时30min,共1h)
4.归并排序
这里也是假设这1T都是数字 ,将这些数据分为1000个小文件
按行读取 ,统计每行个数 ,建立映射关系( 让我们可以通过每行个数知道是哪一行,相同个数行进行特殊标记, 满足一一对应 )
利用归并排序对这1000个文件内部进行排序 ,得到一个内部有序外部无序的的1000个文件( 用时30min )
然后统计这1000个小文件中数据的个数 ,排序放入1个大文件中
由映射关系顺序将每一行写入这个文件, ,得到一个大小和原来一样的文件(也是1T,用时30min,共1h)
归并排序介绍
思考 :
直到现在才发现我的思维还停留在学习java 的思维 ,
而大数据的主要思维就是 将大量数据大事化小 ,分而治之 ,各个击破 ,进行处理
大家可以自己的思考发在评论区 ,我们在博客中分享你们的想法 ,一起努力, 一起进步呀~~~
问题升级
问题不便 ,但是环境改变
环境
由原来的1台计算机变成了2000台计算机(规模足够大) ,要求在 128M,64M,256G的环境下都能够运行

明确 :
- 所有计算算均是在理想状态下,没有损耗 ,没有延时,主要是方便我们计算结果并进行比较
- 1T文件分发给2000台计算机 , 每台500M, 分发速度100M/s,并行分发需要5s.每台计算机读取速度500M/s , 读取1读1写2s,总共7s ,我们再对排序后的数据进行查询花费2s ,加一起9s
方式:
以hash算法为例 ,依旧是按行读取 ,做hash运算 ,得到数字串 ,对2000取余, 对余数进行分类
余数为1的放入第1个文件 ,为2的放入第二个文件…为1999的放入1999个文件,为0的放入第2000个文件(读1s)
然后每台计算机拉取对应的文件, 如
第一台计算机拉取所有余数为1的文件以及对应的值以及这些hash对应的行数据 ,
第二台计算机拉取所有余数为2的文件以及对应的值以及这些hash对应的行数据 ,
第三台计算机拉取所有余数为2的文件以及对应的值以及这些hash对应的行数据 …
用时也是1s, 明确主要占用速率的不是存放这些hash值的文件, 而是他们所对应行的数据的文件
但是我们其实忽略了分发的过程
真实情况一般是这1T文件存储在一个计算机中, 而影响计算机传输速率的是磁盘I/O ,如果不能够并行读取文件,
并且考虑远程分发的消耗 ,主机分发的速率约为100MB/s ,速率降低到原来的1/5 ,时间是原来的5倍,即150min=2.5h
我们在加上考虑文件读取时间将原来的9s 预估成30min ,所以fenfa->存储->查找过程为3h
我们可以看到利用单机执行该查询需要1h ,而集群需要3h,那我们为什么还需要集群呢?
假设1企业1天处理1T数据,
第一天 单机用时1h 集群用时3h
第二天 单机用时2h 集群用时3h
第三天 单机用时3h 集群用时3h
第四天 单机用时4h 集群用时3h
…
可以看到在第四天集群的运算时间完成了对单机的反超
而且, 随着时间的累计与数据量的积累, 这中差异会越来越明显
集群一直用时为3h的原因是他们都是有规则的文件 ,新文件加入时,不需要对原来的文件进行重新读取并排序
而单机版每增加1T, 则需要将之前所有的文件都进行读取,用时一直在增长
这,就是集群处理大数据的,魅力所在.
生活案例——网易云年度报告
记录了我们在去年的时间里总共听歌数量 ,以及播放量前几的几首歌 ,以及最喜欢的歌手等等
这种个性化定制的报告让我们拥有了更好的用户体验 , 也拥有属于自己的那份惊喜~~~
这种个性化的报告身后是强大的大数据技术的支撑 , 利用分布式计算将所有用户的日志记录和操作进行统计
将海量的数据花费4-5天全部计算完毕 ,啥也不说了 ,网易牛逼!
ps :非常重视用户体验, 或许这也是我们喜欢网易云的原因之一吧 .
企业中分布式计算的重要性
利用大数据分页我们最喜欢的手机颜色->两个公司计算时差为1周(技术原因)->后者商机被抢占->资金链断裂->不能融资->破产倒闭
关键词
集群
并行:提升速度的关键
分布式运行
计算与数据在一起
计算向数据移动
第二章 Hadoop
一 Hadoop简介
2003-2004年,Google公开了部分GFS和Mapreduce思想的细节,以此为基础Doug Cutting等人用了2年业余时间实现了DFS和Mapreduce机制,一个微缩版:Nutch
Hadoop 于 2005 年秋天作为 Lucene的子项目 Nutch的一部分正式引入Apache基金会。2006 年 3 月份,Map-Reduce 和 Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目 ,现在Hadoop已成为顶级项目(可商用)之一
Hadoop官网:http://hadoop.apache.org
HDFS优点
高容错性
数据自动保存多个副本
副本丢失后,自动恢复
适合批处理
移动计算而非数据
数据位置暴露给计算框架(Block偏移量)
适合大数据处理
GB 、TB 、甚至PB 级数据
百万规模以上的文件数量
10K+ 节点
可构建在廉价机器上
通过多副本提高可靠性
提供了容错和恢复 机制
HDFS缺点
小文件存取时
占用NameNode 大量内存
寻道时间超过读取时间
不支持并发写入、文件随机修改
一个文件只能有一个写者
仅支持append
二 Hadoop分布式文件系统HDFS
学习目标 : 尽量理解分布式文件系统如何很好的支持分布式计算
相关介绍
分布式存储系统HDFS (Hadoop Distributed File System )
提供了高可靠性、高扩展性和高吞吐率的数据存储服务的分布式存储系统
HDFS官方文档: 会有下面所有介绍的更详细的讲解
分布式计算框架MapReduce
分布式计算框架(计算向数据移动)
具有易于编程、高容错性和高扩展性等优点。
分布式资源管理框架YARN(Yet Another Resource Management)
负责集群资源的管理和调度
HDFS架构图

,
架构模型
- 文件元数据MetaData,文件数据 . 元数据 :数据本身
- HDFS具有主从架构
(主)NameNode节点保存文件元数据:单节点 posix
(从)DataNode节点保存文件Block数据:多节点 - 结构模型关系介绍
DataNode与NameNode保持心跳,提交Block列表
HdfsClient与NameNode交互元数据信息
HdfsClient与DataNode交互文件Block数据
存储模型( 重点掌握 )
以后我们看到块要立即反应到偏移量,位置信息

NameNode(NN)
基于内存存储 :不会和磁盘发生交换
特点:
1.只存在内存中
2.持久化
NameNode主要功能
接受客户端的读写服务
收集DataNode汇报的Block列表信息
NameNode保存metadata信息包括
文件owership和permissions文件大小,
时间(Block列表:Block偏移量),位置信息, Block每副本位置(由DataNode上报)
NameNode持久化
NameNode的metadate信息在启动后会加载到内存
metadata存储到磁盘文件名为” fsimage ”
Block的位置信息不会保存到fsimage
edits记录对metadata的操作日志
DataNode(DN)
本地磁盘目录存储数据(Block),文件形式 . 同时存储Block的元数据信息文件
启动DN时会向NN汇报block信息, 通过向NN发送心跳保持与其联系(3秒一次),
如果NN 10分钟没有收到DN的心跳,则认为其已经lost,并copy其上的block到其它DN
SecondaryNameNode(SNN)
它不是NN的备份(但可以做备份),它的主要工作是帮助NN合并edits log,减少NN启动时间。
SNN执行合并时机
根据配置文件设置的时间间隔fs.checkpoint.period 默认3600秒
根据配置文件设置edits log大小 fs.checkpoint.size 规定edits文件的最大值默认是64MB
SNN执行流程图
- fsimage文件 : 其实是Hadoop文件系统元数据的一个永久性的检查点,
其中包含Hadoop文件系统中的所有目录和文件idnode的序列化信息; - edits文件 : 存放的是Hadoop文件系统的所有更新操作的路径,
文件系统客户端执行的写操作首先会被记录到edits文件中。

过程介绍
- 在 PNN(Primary NameNode) 合并之前,会将 edits 和 fsimage 文件发送给 SNN,然后 PNN 创建一个新的 edits.new 文件继续记录 PNN 的操作。
- PNN 将之前的 edits 和 fsimage 发送给 SNN 后,SNN 会将 fsimage 加载到内存,edits 也加载到内存
根据 edits 中操作记录执行相应的指令,当 edits 的所有操作记录对应的指令执行完毕,会生成一个新的 fsimage.ckpt 快照。 - 将新生成的 fsimage.ckpt 再发送给 PNN ,这时 PNN 就拥有 edits.new 创建之前的快照记录
若 PNN 发生了宕机,可以根据 fsimage 和 edits.new 恢复到宕机前的状态
Block的副本放置策略
Rack :服务器机架
服务器介绍,注意关注服务器的结构分类

第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
第二个副本:放置在于第一个副本不同的机架的节点上。
第三个副本:与第二个副本相同机架的节点。
更多副本:随机节点
三 HDFS的读写流程
HDFS写流程
需要掌握读写流程的过程 ,面试很大可能会用到

HDFS写流程过程
Client:进行写数据前
切分文件Block ,形成更小的包, 一个包中含有一个datanode
按Block线性和NN获取DN列表(副本数,一般为3个)
验证DN列表后以更小的单位流式传输数据各节点,两两通信确定可用
Block :并行传输时(充分利用的时间线的重叠) ,
第一次写数据时 ,数据首先传输给第一个datanode,
第二次写数据时, 数据传给第一个datanode的同时, 上一次数据通过这个datanode传给第二个datanode
第三次写数据时, 新的数据给第一个datanode, 第二个datanode接收第二次写数据,并将第一次的数据传给第一个datanode…
即: 传数据时 ,除第一次传输 ,每个datanode都会接收数据和发送数据
这样就保证了如果某一次写数据给第一个datanode时, 写入失败 , client可以直接将数据写给第二个datanode, 依次类推, 提高写数据的安全性与可靠性.
Block传输结束后:
DN向NN汇报Block信息 ,DN向Client汇报完成
Client向NN汇报完成获取下一个Block存放的DN列表
最终Client汇报完成(写流程结束) ,NN会在写流程更新文件状态
HDFS读流程
需要掌握读写流程的过程 ,面试很大可能会用到

HDFS读流程过程
- HDFS的client向NN(NameNode)获取块的位置信息, NN返回距离排序列表 ,
读取时按照距离优先的原则 , 读优先取距离clientnode最近的的DN(DataNode) - 客户端读取数据时 ,可以是人为下载文件 ,也可以是计算框架( 计算向数据移动 ) ,并很好的支撑计算本地化读取
- 线性和 DN 获取 Block,最终合并为一个文件
结论: HDFS很好的支撑了计算本地化读取
四 HDFS中的角色权限与安全模式
HDFS文件权限
POSIX
可移植操作系统接口(英语:Portable Operating System Interface,缩写为POSIX)
是IEEE为要在各种UNIX操作系统上运行软件,而定义API的一系列互相关联的标准的总称,
其正式称呼为IEEE Std 1003,而国际标准名称为ISO/IEC 9945。它基本上是Portable Operating System Interface(可移植操作系统接口)的缩写,而X则表明其对Unix API的传承。
与Linux文件权限类似
r: read; w:write; x:execute
权限x对于文件忽略,对于文件夹表示是否允许访问其内容
所有者(owner)就是Linux的当前用户
如果Linux系统用户zhangsan使用hadoop命令创建一个文件,那么这个文件在HDFS中owner就是zhangsan。
HDFS的权限目的
阻止好人错错事,而不是阻止坏人做坏事。HDFS相信,你告诉我你是谁,我就认为你是谁。
例如A部门可以在HDFS处理A部门的资料 , B部门可以在HDFS处理B部门的资料,
虽然A部门无法修改B部门资料 ,但是我们可以通过使用另一个虚拟机在系统用户下创建名称是B部门下的账号, 登入系统即可访修改问B部门的资料
HDFS中角色
角色==进程
namenode
- 数据元数据
- 内存存储,不会有磁盘交换
- 持久化(fsimage,eidts log)不会持久化block的位置信息(不保存到镜像,关闭后即消失)
- block:偏移量,因为block不可以调整大小,hdfs不支持修改文件 , 偏移量不会改变
datanode
- block块
- 磁盘
- 面向文件,大小一样,不能调整
- 副本数,调整,(备份,高可用,容错/可以调整很多个,为了计算向数据移动)
SNN(了解即可)
NN&DN
- 心跳机制
- DN向NN汇报block信息
- 安全模式
client
可以结合架构图再去理解一下
安全模式
-
namenode启动的时候,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作。
-
一旦在内存中成功建立文件系统元数据的映射,则创建一个新的fsimage文件(这个操作不需要SecondaryNameNode)和一个空的编辑日志。此刻namenode运行在安全模式。即namenode的文件系统对于客服端来说是只读的。(显示目录,显示文件内容等。写、删除、重命名都会失败)。
-
在此阶段Namenode收集各个datanode的报告,当数据块达到最小副本数以上时,会被认为是“安全”的, 在 一定比例(可设置)的数据块被确定为“安全” 后,再过若干时间,安全模式结束
-
当检测到副本数不足的数据块时,该块会被复制直到达到最小副本数,系统中数据块的位置并不是由namenode维护的,而是以块列表形式存储在datanode中。
第三章 HDFS高可用集群搭建及API
一 HDFS的安装
操作系统环境
- 依赖软件ssh,jdk
- 环境的配置 ( java_home, 免密钥 )
- 时间同步
- hosts,hostname配置
hadoop部署
- /opt/chy/
- 配置文件修改 : java_home
- 角色在哪里启动
安装步骤
# 0. 免密钥配置( 已经在1配置了免密钥(对其他所有节点) ,需要在2也配置免密钥(对1即可) )
# 在node2中输入以下命令
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cd /root/.ssh/
cat id_dsa.pub >> authorized_keys
cat authorized_keys
ssh node2
exit
scp id_dsa.pub node1:`pwd`/node2.pub
# 在node1中输入以下命令
cd /root/.ssh/
# 在node2中验证免密钥是否成功
[root@node2 .ssh]# ssh node1
Last login: Sun Oct 20 01:03:41 2019 from localhost
[root@node1 ~]# exit
# 1.在 /etc/hosts 文件中配置ip地址映射(对应四台主机,图1)
192.168.179.140 node1
192.168.179.141 node2
192.168.179.142 node3
192.168.179.143 node4
# 2. 验证主机名
hostname
# 3.本机免密钥配置, 生成密钥文件
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
# 4.在/root目录下,找到生成的密钥
ll -a #找到存放密钥和公钥的.ssh文件(图2)
cd ./ssh
[root@node1 .ssh]# ll
total 12
-rw-------. 1 root root 668 Oct 19 17:28 id_dsa #密钥
-rw-r--r--. 1 root root 600 Oct 19 17:28 id_dsa.pub #公钥
-rw-r--r--. 1 root root 794 Oct 19 17:23 known_hosts
# 5,读取/root目录下的公钥文件重定向并追加到/root目录下的authorized_keys文件中
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
# 执行后,会生成authorized_keys文件
[root@node1 .ssh]# ll
total 16
-rw-r--r--. 1 root root 600 Oct 19 17:36 authorized_keys # 新文件
-rw-------. 1 root root 668 Oct 19 17:28 id_dsa
-rw-r--r--. 1 root root 600 Oct 19 17:28 id_dsa.pub
-rw-r--r--. 1 root root 794 Oct 19 17:23 known_hosts
# 通过对比发现两个文件内容一样
cat id_dsa.pub authorized_keys
# 6.安装jdk,配置环境变量 ,重载该文件
-------------------------------
export JAVA_HOME=/usr/java/jdk1.7.0_67
export HADOOP_PREFIX=/opt/chy/hadoop
-------------------------------
source /etc/profile
# 7.利用jps验证jdk是否安装以及环境变量是否配置成功
[root@node1 .ssh]# jps
2604 Jps
# 8.新建安装目录,上传hadoop2.6.5,并解压
tar -zxf hadoop-2.6.5.tar.gz
mkdir /opt/chy
# 9,为/sbin 管理命令添加环境变量,令其在任何目录下都能够执行
pwd #复制/sbin所在目录
#在 /etc/profile中添加如下,并重载
------------------------------------------------------------
export HADOOP_PREFIX=/opt/chy/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin
------------------------------------------------------------
. /etc/profile
# 10.测试是否安装成功(图3)
ha + tab+tab
hdfs + tab+tab
start + tab+tab
图1
图2

图3

小技巧 : Xshell中的局内复制粘贴
利用alt+e和alt+c可以实对选中文件的快速复制, alt+e和alt+p 实现对内容的粘贴
具有同样效果的是 ctrl+insert 复制, shift +insert粘贴
虚拟机内部复制一行+粘贴到下一行命令是 yy+p (编辑模式)
二 集群的配置
配置伪集群
集群配置图解

搭建步骤
# 1. JAVA_HOME的二次配置 ,复制JAVA_HOME的配置文件,都被注释, 需要放开(图4)
vi /opt/chy/hadoop/etc/hadoop/hadpoop-env.sh
vi /opt/chy/hadoop/etc/hadoop/mapred-env.sh
vi /opt/chy/hadoop/etc/hadoop/yarn-env.sh
# 2.修改core-site.xml,设置了name在哪里启动, 以及执行本地存放数据的目录为/var/chy/hadoop/local
vi core-site.xml
------------注意主机名以及指定的目录信息---------------------
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/chy/hadoop/local</value>
</property>
</configuration>
# 3,配置hdfs-site.xml,修改second namenode在哪里启动
vi hdfs-site.xml
--------------注意主机名以及端口号,这里的端口号是图形化界面的端口号---------------------
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:50090</value>
</property>
</configuration>
# 4.修改datanode在启动地方
vi slaves
---------内容---------------
node1
# 5. 格式化HDFS ,查看是否成功(图5)
hdfs namenode -format
# 查看本地数据所在目录
[root@node1 ]# cd /var/chy/hadoop/local/dfs/name/current/
[root@node1 current]# ll
total 16
-rw-r--r--. 1 root root 320 Oct 19 20:40 fsimage_0000000000000000000 #第一个初始的fsimage
-rw-r--r--. 1 root root 62 Oct 19 20:40 fsimage_0000000000000000000.md5
-rw-r--r--. 1 root root 2 Oct 19 20:40 seen_txid
-rw-r--r--. 1 root root 206 Oct 19 20:40 VERSION
# 可以看到VERSION中已经含有了NameNode中的Block等相关信息
[root@node1 current]# cat VERSION
# Sat Oct 19 20:40:20 CST 2019
namespaceID=119524649
clusterID=CID-db364b61-d241-4d38-b370-3425de275ef3
cTime=0
storageType=NAME_NODE
blockpoolID=BP-635787903-192.168.179.140-1571488820328
layoutVersion=-60
# 6.启动管理脚本
start-dfs.sh
# 查看日志文件
/opt/chy/hadoop/logs/hadoop-root-datanode-node1.out
# 通过jps查看启动是否成功
[root@node1 ~]# jps
1244 NameNode
1503 SecondaryNameNode
1331 DataNode
1947 Jps
# 7.在`/var/chy/hadoop/local/dfs/`目录下 ,我们可以看到有data和name文件,但是在真的集群中, 这两个文件时在不同主机上的
我们第一次初始化后可能又会因为误操作(格式化)导致namenode中的数据被删除而datanode中的数据没有被删除(因为datanode第一次从namenode中获得集群ID就不会改变了,格式化只格式namenode),
而导致二者ID不一致的情况,这样做最终的结果是会导致启动后DataNode消失(如图6,图7)
DataNode上的VERSION文件创建的时机: NameNode启动后, DataNode启动时与NameNode交互得来的 (一次交互, 永不更改 )
# 伪集群下访问如何目录,可以看到DN和NN存放的位置
[root@node1 ~]# cd /var/chy/hadoop/local/dfs/
[root@node1 dfs]# ll
total 12
drwx------. 3 root root 4096 Oct 19 21:41 data
drwxr-xr-x. 3 root root 4096 Oct 19 21:40 name
drwxr-xr-x. 2 root root 4096 Oct 19 21:41 namesecondary
#查看NameNode的VERSION信息
cd /var/chy/hadoop/local/dfs/name/current/
cat VERSION
#查看DataNode的VERSION信息
cd /var/chy/hadoop/local/dfs/date/current/
cat VERSION
# 8.访问图形化界面(图8)
service iptables stop
http://node1:50070/
# 9.操作HDFS ,我们可以通过输入 hdfs dfs后提示可知, hdfs dfs -绝大多数Linux命令
# eg:
#新建目录
hdfs dfs -mkdir -p /user/root
# 测试文件上传(都可以通过图形化界面管理,图9)
hdfs dfs -put hadoop-2.6.5.tar.gz /user/root
# 并且,由图10可以看出文件(180MB)被为了两块 ,每块id不同
图4

图5

再次强调
1.在/var/chy/hadoop/local/dfs/目录下 ,我们可以看到有data和name文件,但是在真的集群中, 这两个文件时在不同主机上的
2.我们第一次初始化后可能会因为误操作(格式化)导致NameNode中的数据被删除而DataNode中的数据没有被删除(因为DataNode第一次从NameNode中获得集群ID就不会改变了,格式化只会格式NameNode)
3.而导致二者ID不一致的情况,这样做最终的结果是会导致启动后DataNode消失(如图6,图7)
DataNode上的VERSION文件创建的时机: NameNode启动后, DataNode启动时与NameNode交互得来的 (一次交互, 永不更改 )
图6

图7

图8

图9

图10

测试伪集群
HDFS的官方文档
在首页左下方文档中查找相关的参数 ,通过hdfs dfs -D 相关参数进行修改
# 1.创建一个文本文件,内容是hello csdn 1-100000,10w行,并上传到HDFS(选择文本的原因是方便我们的查看文本内容)
for i in `seq 100000`;do echo "hello csdn $i" >> testhadoop.txt;done
# 2.显示文件大小,换算成 M
[root@node1 ~]# ll -h
-rw-r--r--. 1 root root 1.7M Oct 19 22:50 testhadoop.txt
# 3.设置块大小( 设置块大小图1 https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml )
hdfs dfs -D dfs.blocksize=1048576 -put testhadoop.txt
# 4. 查看被切分的文件
cd /var/chy/hadoop/local/dfs/data/current/BP-206976221-192.168.179.140-1571489736295/current/finalized/subdir0/subdir0/
# 从测试中可以看到, HDFS严格按照字节去切分
[root@node1 subdir0]# vi blk_1073741827
[root@node1 subdir0]# vi blk_1073741828
图1

图2

从测试中可以看到, HDFS严格按照字节去切分
图3

图4

配置集群
集群配置图解

配置步骤
# 1. 关闭NN,DN,SNN
stop-dfs.sh
# 2.对其他结点(node2,node3,node4)安装jdk
# 可通过Xshell的全部会话功能同时对三个节点进行安装
rpm -ivh jdk-7u67-linux-x64.rpm
vi /etc/prvi /etc/profile
----------------------环境变量,注意修改成自己的-------------------------------
export JAVA_HOME=/usr/java/jdk1.7.0_67
export HADOOP_PREFIX=/opt/chy/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin
-----------------------------------------------------
source /etc/profile
jps
# 3.在/root下生成 .ssh文件(所有节点,可通过Xshell全部会话功能)
ssh localhost
exit
cd /roo/.ssh
# 4.将node1中的公钥发送到其他节点
scp id_dsa.pub node2:`pwd`/node1.pub
scp id_dsa.pub node3:`pwd`/node1.pub
scp id_dsa.pub node4:`pwd`/node1.pub
# 将 每个节点 中收到的公钥追加到 authorized_keys文件中(没有自动创建)
cat node1.pub >> authorized_keys
# 5.在 node1 配置HADOOP中的HDFS,配置完成后分发给其他节点
cd /opt/chy/hadoop/etc/hadoop/
# 修改NN启动配置
vim core-site.xml
-----------------------
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/chy/hadoop/full</value>
</property>
-----------------------
# 修改DN启动配置
vi slaves
-----------------------
node2
node3
node4
-----------------------
# 修改SNN启动配置(副本数,启动ip)
-----------------------
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:50090</value>
</property>
</configuration>
-----------------------
注意 : 该步骤是在伪集群配置的基础上运行的 ,如果一开始没有搭建伪集群需要对JAVA_HOME进行二次配置 ,放开下面文件中关于java环境变量的配置, 指定成自己的环境变量配置
vi /opt/chy/hadoop/etc/hadoop/hadpoop-env.sh
vi /opt/chy/hadoop/etc/hadoop/mapred-env.sh
vi /opt/chy/hadoop/etc/hadoop/yarn-env.sh
# 6. 将node1配置好的hdfs配置分发到其他节点
scp -r hadoop/ node2:`pwd`
scp -r hadoop/ node3:`pwd`
scp -r hadoop/ node4:`pwd`
# 7.启动hdfs
# 格式化(第一次启动必做, 图1)
hdfs dfs -format #之前没有配置伪集群
hdfs namenode -format #之前配置伪集群(dfs不会格式化namenode的信息)
# 查看namenode中是否创建了VERSION文件
cd /var/chy/hadoop/full/dfs/name/current/
# 启动hdfs服务(图2)
# 根据图示可知,node1启动了name,node2启动了SNN,node2,3,4启动了datanode,可以通过 jps 查看是否启动
start-dfs.sh
# 访问可视化界面(图3)
http://node1:50070
图1

图2

图3

第四章 Hadoop 2.0
一 Hadoop 2.0
1.产生背景
-
Hadoop 1.0中HDFS和MapReduce在高可用、扩展性等方面存在问题
-
HDFS存在的问题
NameNode单点故障,难以应用于在线场景
NameNode压力过大,且内存受限,影响扩展性 -
MapReduce存在的问题响系统
JobTracker访问压力大,影响系统扩展性
难以支持除MapReduce之外的计算框架,比如Spark、Storm等
2.hadoop 1.0与2.0的比较

3.Hadoop 2.x由HDFS、MapReduce和YARN三个分支构成
- HDFS:NN Federation(联邦)、HA;2.X: 只支持2个节点HA,3.0实现了一主多备
- MapReduce:运行在YARN上的MR;离线计算,基于磁盘I/O计算
- YARN:资源管理系统
4.HDFS 2.x 解决HDFS 1.0中单点故障和内存受限问题。
- 解决单点故障
HDFS HA:通过主备NameNode解决
如果主NameNode发生故障,则切换到备NameNode上 - 解决内存受限问题
HDFS Federation(联邦)
水平扩展,支持多个NameNode;
(1)每个NameNode分管一部分目录;
(2)所有NameNode共享所有DataNode存储资源 - 2.x仅是架构上发生了变化,使用方式不变
- 对HDFS使用者透明
- HDFS 1.x中的命令和API仍可以使用
5.HDFS 2.x HA自动化策略

- 主备 NameNode
- 解决单点故障(属性,位置)
主NameNode对外提供服务,备NameNode同步主NameNode元数据,以待切换
所有DataNode同时向两个NameNode汇报数据块信息(位置) - JNN:集群(属性)
actiove : 主, 通过NN之间相互争抢 ,抢到则自动升级为主,状态置为active, 另一个则将为备 ,状态置为standby
standby:备,完成了 edits.log 文件的合并产生新的image,推送回主NameNode - 两种切换选择
手动切换:通过命令实现主备之间的切换,可以用HDFS升级等场合
自动切换:基于Zookeeper实现 - 基于Zookeeper自动切换方案
ZooKeeper Failover Controller:监控NameNode健康状态 ,并向Zookeeper注册NameNode
NameNode挂掉后,ZKFC为NameNode竞争锁,获得ZKFC 锁的NameNode变为active
免密钥的使用场景 :
- 管理脚本的时候 ,需要利用脚本启动其他节点上的相关x-node,主要操作是将一台节点上密钥分发给其他节点
- 搭建HA时, NN的zkfc需要免秘钥控制对方和自己
联邦知识的使用

在一个公司的时候 ,各部门都需要各自处理数据的时候, 但是由于服务器有限,我们可以通过HDFS的联邦机制.
在有限的服务器(50台)中创建NameNode ,不同的部门使用不同的NameNode ,这些NameNode高度自治, 互不干扰
但是问题是如何让我们知道哪些资源位于哪个NameNode中呢?

我们可以创建一个文件系统(FS) ,每个FS中都通过使用web开发的形式对外暴露接口 ,
让不同部门的用户通过FS的图形化界面去对NN进行读写等操作 ,
而每个FS对外层暴露接口 , 对内层做进行资源的统一管理(封装Linux指令 ,管理底层数据,如FTP, hbase , DN等), 又不影响不同部门之间的操作 ,但是随着部门的增多以及时间的推移 ,单个FS逐渐会成为系统的瓶颈 ,处理效率会降低
我们可以通过使用Nginx对该FS平台做负载均衡 ,保证了系统的可靠性(从成本,可靠性,复杂度考虑…)
二 HDFS HA配置
一定要确定是HA 还是 Federation
需求效果图(HA 自动化)

注意:
NameNode,Zookeeper(ZK)在企业服务中应该是单独拿出来提供服务的
JNN也应该和DN拆开, 但是非专业环境模拟效果有限 ,因此将其糅合在一起
JN : journal node
搭建说明
搭建基于QJM的HA, 搭建过程依据 官方文档
通过对官方配置文件的讲解来梳理思路
- 逻辑到物理的映射
- 做JN的相关配置
- 发生故障的代理实现设置和免密钥设置
启动思路
启动JN ,格式化NN ,启动ZK, 格式化ZK
环境搭建
ZK搭建步骤
# 1.在node2中上传ZK , 配置完毕后 , 分发给加他节点(jdk支持)
mv zookeeper-3.4.6 /opt/zookeeper -f
# 2.为了能让ZK配置成在任意位置使用 ,需要配置ZK环境变量
# 配置环境变量
vi /etc/profile
-----------------------------------zk环境变量配置,注意ZK地址指定--------------------------
export ZOOKEEPER_HOME=/opt/zookeeper
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin:$ZOOKEEPER_HOME/bin
-----------------------------------zk环境变量配置,注意ZK地址指定--------------------------
# 重新读取环境变量配置
. /etc/profile
# 测试配置是否成功 ,输入zk + tab+tab 查看是否会有下面的文件
[root@node2 bin]# zk
zkCleanup.sh zkCli.cmd zkCli.sh zkEnv.cmd zkEnv.sh zkServer.cmd zkServer.sh
# 3,修改ZK的配置文件
-------------------------------------------------------------------------
# 修改数据存放目录
dataDir=/var/chy/hadoop/zk
# 集群配置
server.1=192.168.179.141:2888:3888
server.2=192.168.179.142:2888:3888
server.3=192.168.179.143:2888:3888
-------------------------------------------------------------------------
# 修改配置文件名称(ZK运行时默认读取zoo.cfg)
mv zoo_sample.cfg zoo.cfg
# 数据存放新建目录 ,创建ZK集群的唯一标识文件
mkdir -p /var/chy/hadoop/zk
echo 1 > /var/chy/hadoop/zk/myid
# 4.分发文件到其他节点 ,并修改ZK集群的唯一标识文件
scp -r zookeeper/ node3:`pwd`
scp -r zookeeper/ node4:`pwd`
# node3
mkdir -p /var/chy/hadoop/zk
echo 2 > /var/chy/hadoop/zk/myid
# node4
mkdir -p /var/chy/hadoop/zk
echo 3 > /var/chy/hadoop/zk/myid
# 5.修改node3,node4的ZK环境变量配置 ,
export ZOOKEEPER_HOME=/opt/zookeeper
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin:$ZOOKEEPER_HOME/bin
# 重载, 并测试
[root@node4 chy]# . /etc/profile
[root@node4 chy]# zk
zkCleanup.sh zkCli.cmd zkCli.sh zkEnv.cmd zkEnv.sh zkServer.cmd zkServer.sh
# 9.启动node2,3,4的zookeeper ,查看哪个是领导者哪个是追随者
zkServer.sh start
zkServer.sh status
HDFS HA QJM搭建步骤
# 1. 基于伪集群 / 集群 安装后
cd /opt/chy/hadoop/etc/
# 备份hadoop到hadoop-full, hadoop-full是我们之前配置的hdfs集群
cp -rf hadoop/ hadoop-full
# 在hadoop目录下而不是hadoop-full
# 2.修改hdfs-site.xml ,修改集群逻辑名称到物理的映射 ,代码块在下方
# 3.修改core-site.xml,指定集群名称, 存放数据的地址, 集群ip, 代码块在下方
# 4. 修改slave配置
[root@node2 hadoop-full]# vim slaves
--------------------------------------------------
node2
node3
node4
# 5.分发这些文件到其他节点
scp core-site.xml hdfs-site.xml slaves node2:`pwd`
scp core-site.xml hdfs-site.xml slaves node3:`pwd`
scp core-site.xml hdfs-site.xml slaves node4:`pwd`
# 6.要进行初始化, 首先应该启动JN(node1,node2,node3)
hadoop-daemon.sh start journalnode
# node1
hdfs namenode -format #图1
# node1启动namenode(主)
hadoop-daemon.sh start namenode
# node2启动备用namenode
hdfs namenode -bootstrapStandby
# node1格式化ZK(图2 ,可以看到初始化ZK后会在集群中创建/hadoop-ha/mycluster节点,且目录下为空)
hdfs zkfc -formatZK
# 7.启动HDFS服务(图3, 图4)
start-dfs.sh
# 在node2,3,4中使用jps可以看到QuorumPeerMain进程,这个就是代表ZK启动进程
# 访问主NN和备NN的图形化界面
# 前提: 配置本地hosts地址映射,将备NN所在IP映射成node2
http://node1:50070/
http://node2:50070/
# 第二次启动只需要
1. 启动zk
2. start-dfs.sh
hdfs-site.xml ( 注意节点名称 )
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/chy/hadoop/ha/jn</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
core-site.xml ( 指定集群名称, 存放数据的地址, 集群ip )
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/chy/hadoop/ha</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node2:2181,node3:2181,node4:2181</value>
</property>
</configuration>
图1

图2

图3

图4
需求效果图,用来与图3对比
小技巧: 虚拟机同步时间设置
在集群中 ,对时间进行同步是非常有必要的
# 1.在Xshell右下方选择全部会话功能, 安装ntp服务
yum -y install ntpdate
# 2.启动ntp服务(-u指定的是网络上的ntp服务器,可以自行搜索)
ntpdate -u ntp.api.bz
# 3.查看当前日期
date
测试HDFS HA的性能
1.从下图可以看到启动后,主NN处于激活状态,备NN处于备用状态


2.结束主NNkill -9 NN的进程ID
可以看到node1无法访问, 而node2变成激活状态,升级为主NN


3.重启node1的NN后 ,发现node1变成了备用状态,而node2仍是激活状态也就是说没有自动进行切换
(因为主NN的服务器性能比备NN强很多,在故障结束后,我们一般会希望原来的主NN能够继续成为激活状态)
4.解决方案
jps :查看当前进程
kill -9 DFSZKFailoverControlle进程的ID 结束node2的zkfc进程
再次访问即可看到node1重新变为激活态,而node2又变成了备用状态
hadoop-daemon.sh start zkfc 即使重启node2的zkfc后状态也不会发生改变 ,但是结束node1的zkfc状态会变化
原因 :
zkfc被结束后 ,集群会删除所对应的节点 ,会触发相应的事件导致状态切换
第四章 Eclipse 下开发大数据
一 环境配置(首次)
- 创建 Hadoop 的安装包源码以及工具包所在文件夹 ,图1,资料见底部
- 添加 Hadoop 环境变量和指定用户,(新增HADOOP_HOME,HADOOP_USER_NAME,修改Path,图2,图3)
- 将Hadoop插件放入myeclipse中的指定目录下, 并重启eclipse ,图4,插件见底部
- 指定Map/Reduce的目录,也就是环境变量HADOOP_HOME的目录,不是也是加压后的hadoop-2.6.5所在目录,图5
- 创建DFS Locations配置,用于代替图形化界面管理HDFS ,例如创建修改文件夹等
- 创建完毕后, 可以尝试在HDFS中创建一个文件夹, 然后刷新尝试是否创建成功(这里有问题可以看注意的提示)
- 添加工具包到 user library , 步骤如图7 .
注意 :
-
第6步如果无法创建文件夹(刷新后看不到新的文件夹 ), 则说明HDFS中开启了权限验证
-
需要我们修改修改hdfs-site.xml,追加dfs.permissions配置。如果是true,则打开权限检查系统;如果是false,权限检查就是关闭的。
<property> <name>dfs.permissions</name> <value>false</value> </property> -
配置完成后分发到其他的节点(node2,node3,node4)中。
scp hdfs-site.xml root@node2:`pwd` scp hdfs-site.xml root@node3:`pwd` scp hdfs-site.xml root@node4:`pwd` -
重启HDFS集群
stop-dfs.sh stop stop-dfs.sh start -
重新连接DFS Locations,创建文件夹,并refresh。文件夹创建成功
图 1

图2
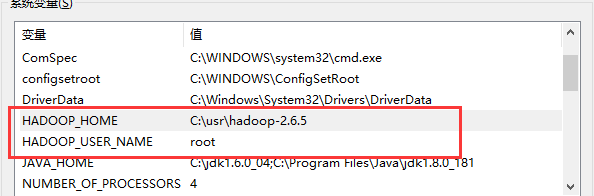
图3

图4

图5

图5

图6

图7

二 HDFS-API的使用
- 创建java项目 ,右击项目 build configuration ,添加我们创建的 user library ,图1
- 将HDFS的配置文件从虚拟机上拷下来 ,然后放在在java项目的根目录下新创建的文件夹 ,将其作为源文件 ,如图2
图1

图2

基本API代码
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
public class TestHDFS {
// 为配置文件创建对象
Configuration conf = null;
// 客户端对象
FileSystem fs = null;
@Before
public void before() throws Exception{
// true 代表读配置文件
conf = new Configuration(true);
// 通过配置文件获取对应的对象HDFS,FTP...
fs = FileSystem.get(conf);
}
@After
public void after() throws Exception{
fs.close(); //关闭资源
}
// 创建目录
@Test
public void mkdir() throws Exception{
// 给定一个目录,若该目录存在,则直接删除再创建
// 若该目录不存在,直接创建
Path f = new Path("/test1");
if(fs.exists(f)){
fs.delete(f, true);
}
fs.mkdirs(f);
}
// 上传文件
@Test
public void upload() throws Exception{
InputStream is =
new BufferedInputStream(
new FileInputStream(new File("E:\\testhadoop.txt")));//上传文件原地址
Path p = new Path("/user/root/test-h.txt");//上传文件目的地址
FSDataOutputStream out = fs.create(p);
IOUtils.copyBytes(is, out, conf, true);
}
// 下载文件
@Test
public void download() throws Exception{
Path path = new Path("/user/root/test-h.txt");//下载文件源地址
InputStream in = fs.open(path);
// 输入流
FSDataInputStream fsin = new FSDataInputStream(in);
// 输出流
OutputStream ops =
new BufferedOutputStream(
new FileOutputStream(new File("E:\\download-test-h.txt")));//下载文件目的地址
// 流对接
IOUtils.copyBytes(fsin, ops, conf);
}
// 块
@Test
public void testBlockLocation() throws Exception{
Path path = new Path("/user/root/testhadoop.txt");
FileStatus fStatus = fs.getFileStatus(path);
//位置新 ,包括坐在块起始字节,结束字节,所在块地址
BlockLocation[] bkls =
fs.getFileBlockLocations(fStatus , 0, fStatus.getLen());
for (BlockLocation bkl : bkls) {
System.out.println(bkl);
}
FSDataInputStream in = fs.open(path);
System.out.println("----------下面是第一个Block--------------");
//输出文件中的字节
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println("----------下面是第二个Block--------------");
//跳到第1048576个字节后,这里指的也就是第二个块中的文件
in.seek(1048576);
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
}
}
运行结果

所被读取的文件内容

链接:https://pan.baidu.com/s/1BrwASaX5ykdsMQ-DIqtGIg
点赞即可获得资料哦
提取码:82q9
复制这段内容后打开百度网盘手机App,操作更方便哦