版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/wanglele1/article/details/86151835
Hadoop-HDFS
存储模型:字节
-文件线性切割成块(Block):偏移量 offset
-block分散存储在集群结点中
-单一文件block大小一致,文件与文件可以不一致
-block可以设置副本数,副本无序分散在不同结点中
>副本数不要超过结点数量
-文件上传可以设置block大小和副本数(资源不够开辟的进程)
-以上传的文件block副本数可以调整,大小不变
(2.X以上版本, 128MB Blocks)
-只支持一次写入多次读取,同一时刻只有一个写入者
-可以append追加数据
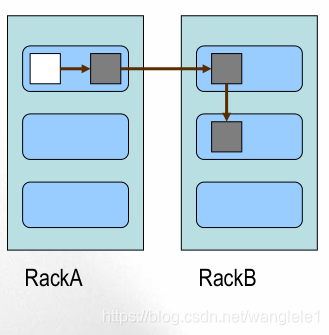
Block的副本放置策略
-第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的结点。
-第二个副本:放置在于第一个副本不同的机架的结点上。
-第三个副本:与第二个副本相同机架的结点。
-更多副本:随机结点
架构模型
-文件元数据MetaDate,文件数据
·元数据
·数据本身
-(主) NameNode节点保存文件元数据:单节点 posix
-(从) DataNode节点保存文件Block数据:多节点
-DataNode与NameNode保持心跳,提交Block列表
-HdfsClient与NameNode交互元数据信息
-HdfsClient与 DataNode交互文件Block数据(cs)
-DataNode利用服务器本地文件系统存储数据块