HDFS:Hadoop分布式文件系统
自学整理,学习笔记链接:https://www.yuque.com/shiwozack/vlklkx/sqhczr
一、课前准备
- 安装VMware15虚拟化软件
- 安装CentOS 7虚拟机3个
- 安装3节点的apache hadoop-3.1.4集群
- windows或mac安装IDEA
- windows做好hadoop环境配置
二、课堂主题
- hadoop发展历史
- hadoop版本介绍及选择
- hadoop模块简介
- hdfs功能详解
三、课堂目标
- 理解分布式文件系统
- 理解hdfs架构
- 熟练hdfs基本命令使用
- 掌握hdfs编程
- 理解namenode及secondarynamenode交互
四、知识要点
1. hadoop的发展历史
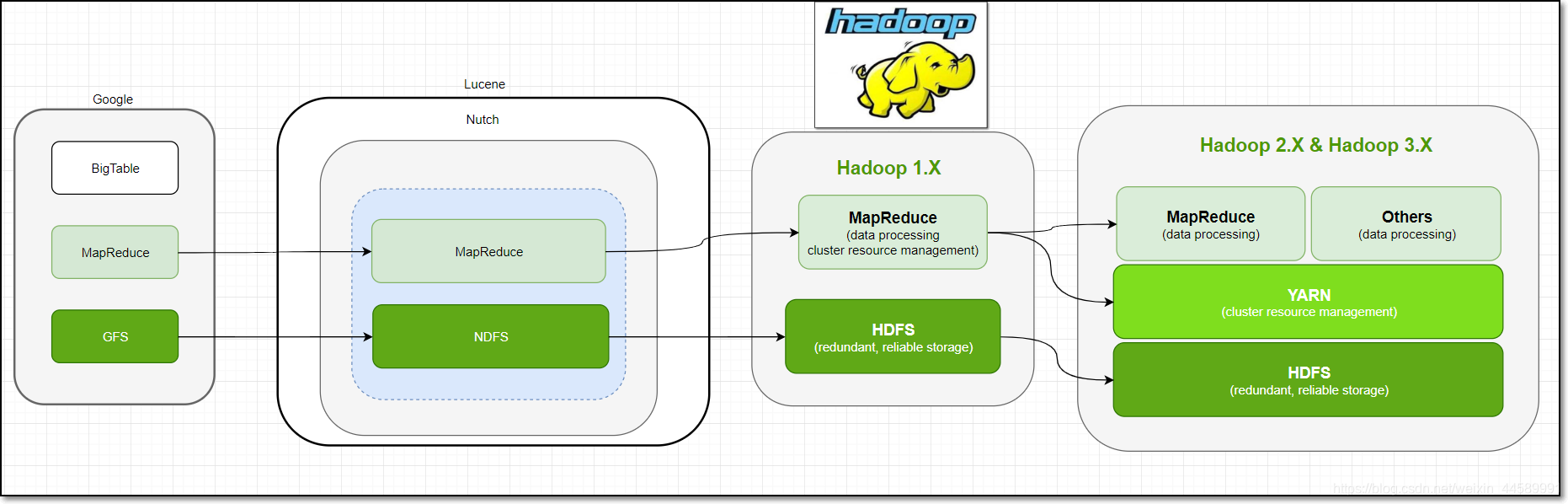
-
Apache Lucene是一个文本搜索系统库
-
Apache Nutch作为前者的一部分
-
Hadoop最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
-
2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
-
Nutch的开发人员2004年、2005年分别完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目(同年,cloudera公司成立),迎来了它的快速发展期。
-
Hadoop作者Doug Cutting

-
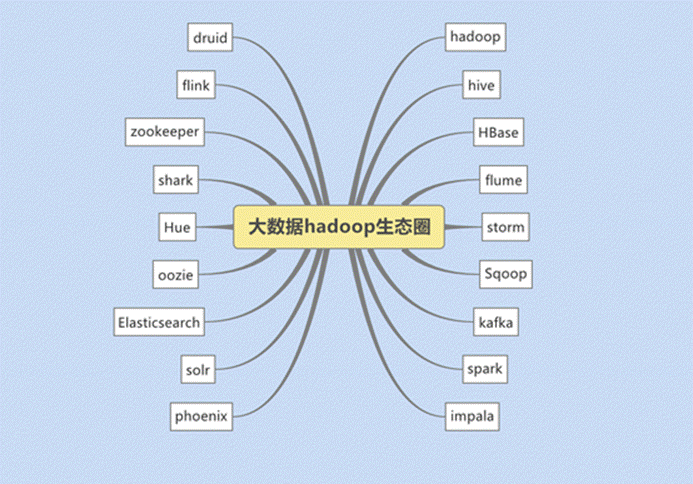
狭义上来说,hadoop就是单独指代hadoop这个软件
-
广义上来说,hadoop指代大数据的一个生态圈,包括很多其他的软件
2. hadoop的版本介绍
-
0.x系列版本:hadoop当中最早的一个开源版本,在此基础上演变而来的1.x以及2.x的版本
-
1.x版本系列:hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等
-
2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性,也是现在生产环境当中使用最多的版本
-
3.x版本系列:在2.x版本的基础上,引入了一些hdfs的新特性等,且已经发型了稳定版本,未来公司的使用趋势
3. hadoop生产环境版本选择
-
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
- Apache版本最原始(最基础)的版本,对于入门学习最好。
- Cloudera在大型互联网企业中用的较多。
- Hortonworks文档较好。
-
mapr
-
Apache Hadoop
官网地址:http://hadoop.apache.org/releases.html
下载地址:https://archive.apache.org/dist/hadoop/common/
-
Cloudera Hadoop
官网地址:https://www.cloudera.com/downloads/cdh/5-10-0.html
下载地址:http://archive.cloudera.com/cdh5/cdh/5/
- 2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
- 2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support
- CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。
- Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。Cloudera Support即是对Hadoop的技术支持。
- Cloudera的标价为每年每个节点4000美元。
- Cloudera开发并贡献了可实时处理大数据的Impala项目。
-
Hortonworks Hadoop
官网地址:https://hortonworks.com/products/data-center/hdp/
下载地址:https://hortonworks.com/downloads/#data-platform
- 现cloudera与hortonworks已合并。
- 2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。
- 公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。
- 雅虎工程副总裁、雅虎Hadoop开发团队负责人Eric Baldeschwieler出任Hortonworks的首席执行官。
- Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。
- HCatalog,一个元数据管理系统,HCatalog现已集成到Facebook开源的Hive中。Hortonworks的Stinger开创性的极大的优化了Hive项目。Hortonworks为入门提供了一个非常好的,易于使用的沙盒。
- Hortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能够在包括Window Server和Windows Azure在内的Microsoft Windows平台上本地运行。定价以集群为基础,每10个节点每年为12500美元。
注意:Hortonworks已经与Cloudera公司合并
4. hadoop的架构模块介绍

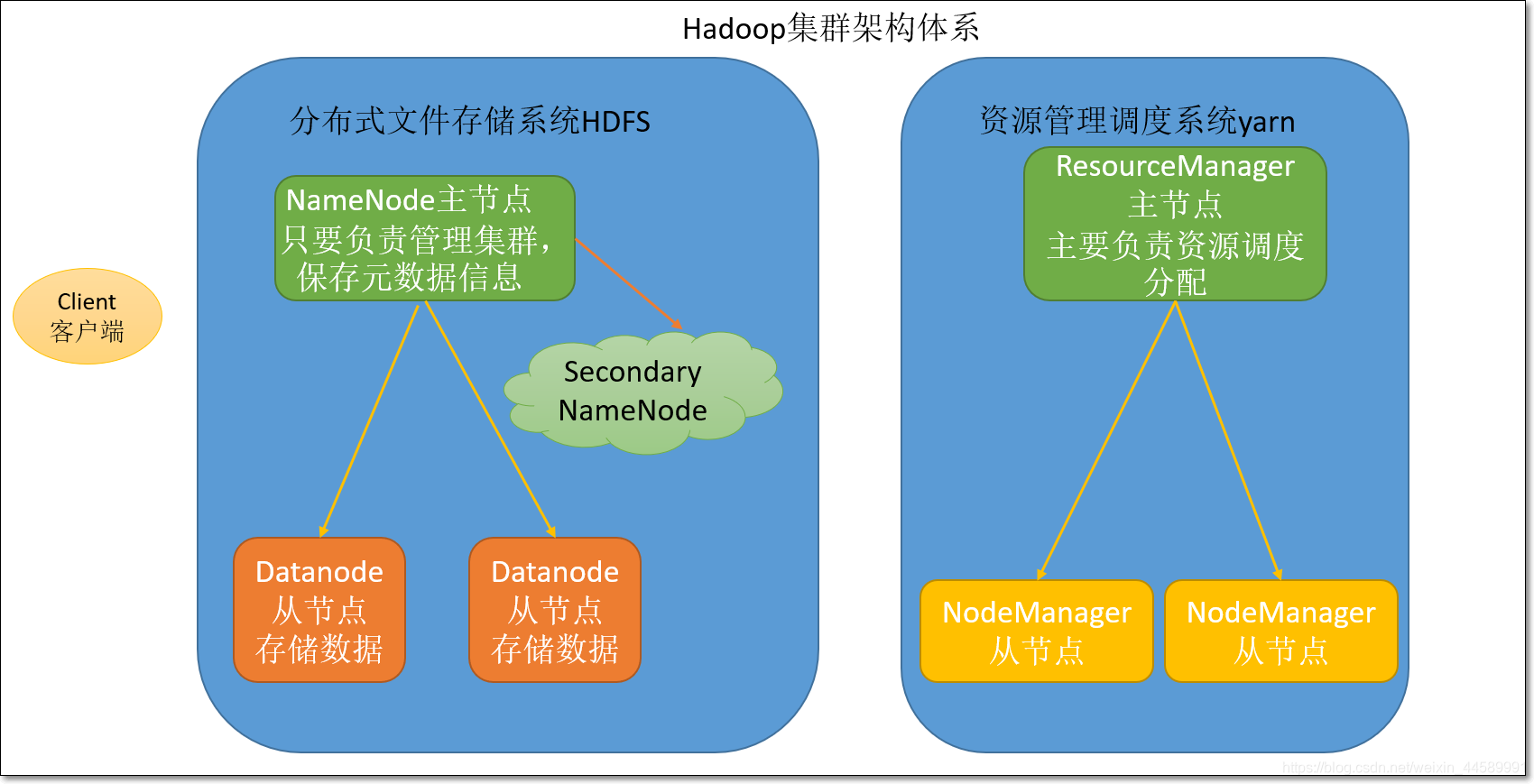
- Hadoop由三个模块组成:分布式存储HDFS、分布式计算MapReduce、资源调度引擎Yarn
-
关键词:
- 分布式
- 主从架构
-
HDFS模块:
-
namenode:主节点,主要负责HDFS集群的管理以及元数据信息管理
-
datanode:从节点,主要负责存储用户数据
-
secondaryNameNode:辅助namenode管理元数据信息,以及元数据信息的冷备份
-
-
Yarn模块:
- ResourceManager:主节点,主要负责资源分配
- NodeManager:从节点,主要负责执行任务
5. hdfs功能详解
1. 理解分布式文件系统
[1、基础环境及hdfs.docx 中的 演示文稿.pptx](assets\1、基础环境及hdfs.docx 中的 演示文稿.pptx)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dJthY4Kx-1614609971926)(assets/分布式文件系统.gif)]](https://img-blog.csdnimg.cn/20210301225213957.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NDU4OTk5MQ==,size_16,color_FFFFFF,t_70)

-
最直观的理解便是三个臭皮匠,顶个诸葛亮。
-
很多的磁盘加一起就可以装下天下所有的avi
-
类似于你出五毛,我出五毛,我们一起凑一块的效果
2. hdfs的架构详细剖析
1. 分块存储&机架感知&3副本
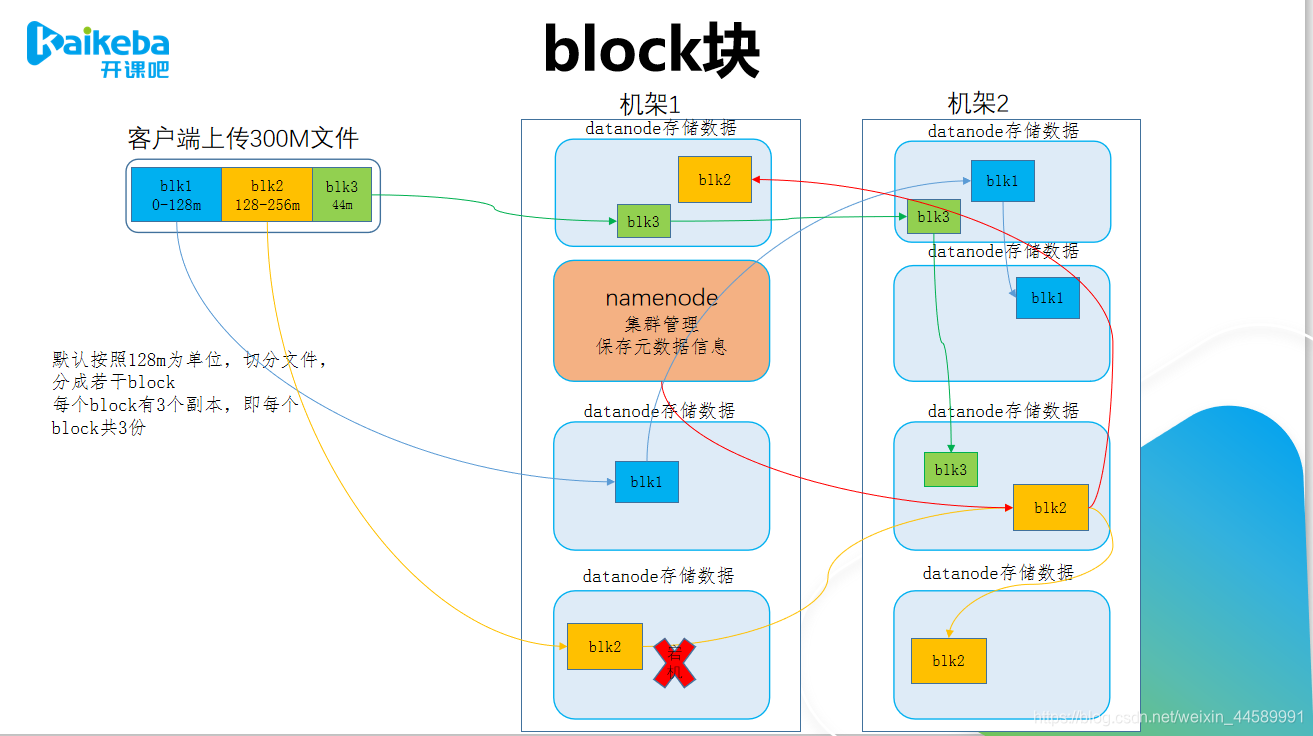
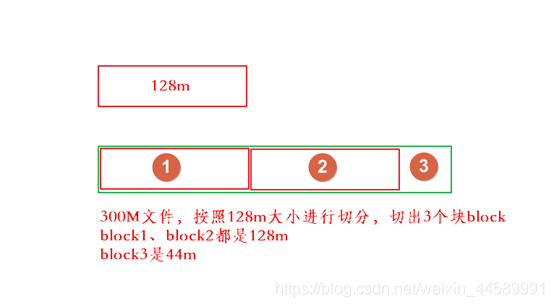
-
分块存储
- 保存文件到HDFS时,会先默认按128M的大小对文件进行切分成block块
- 数据以block块的形式存在HDFS文件系统中
- 在hadoop1当中,文件的block块默认大小是64M
- hadoop2、3当中,文件的block块大小默认是128M,block块的大小可以通过hdfs-site.xml当中的配置文件进行指定
<property> <name>dfs.blocksize</name> <value>块大小 以字节为单位</value><!-- 只写数值就可以 --> </property>-
hdfs-default.xml参考默认属性
-
例如:
如果有一个文件大小为1KB,也是要占用一个block块,但是实际占用磁盘空间还是1KB大小
类似于有一个水桶可以装128斤的水,但是我只装了1斤的水,那么我的水桶里面水的重量就是1斤,而不是128斤
-
block元数据:每个block块的元数据大小大概为150字节
-
3副本存储
- 为了保证block块的安全性,也就是数据的安全性,在hadoop2当中,采用文件默认保存三个副本,我们可以更改副本数以提高数据的安全性
- 在hdfs-site.xml当中修改以下配置属性,即可更改文件的副本数
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
- 扩展:机架感知
- 副本存放策略,不同版本稍有区别Replica Placement: The First Baby Steps:
- 比如apache hadoop 2.7.7
- Replica Placement: The First Baby Steps
- 比如apache hadoop 2.8.5
2. 抽象成数据块的好处
-
文件可能大于集群中任意一个磁盘
10T*3/128 = xxx块 10T 文件方式存—–>多个block块,这些block块属于一个文件 -
使用块抽象而不是文件可以简化存储子系统
hdfs将所有的文件全部抽象成为block块来进行存储,不管文件大小,全部一视同仁都是以block块的形式进行存储,方便我们的分布式文件系统对文件的管理
-
块非常适合用于数据备份;进而提供数据容错能力和可用性
3. HDFS架构
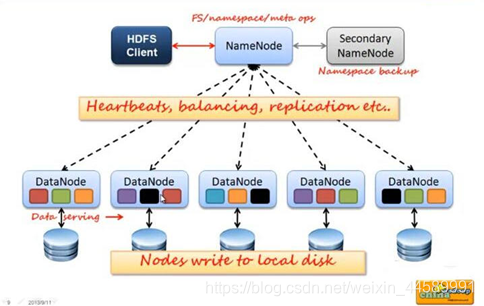
-
HDFS集群包括,NameNode和DataNode以及Secondary Namenode。
- NameNode负责管理整个文件系统的元数据,包括hdfs目录树、每个文件有哪些块、每个块存储在哪些datanode
- DataNode 负责管理用户的文件数据块,每一个数据块都可以在多个datanode上存储多个副本。
- Secondary NameNode用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。最主要作用是辅助namenode管理元数据信息
-
NameNode与Datanode的总结概述
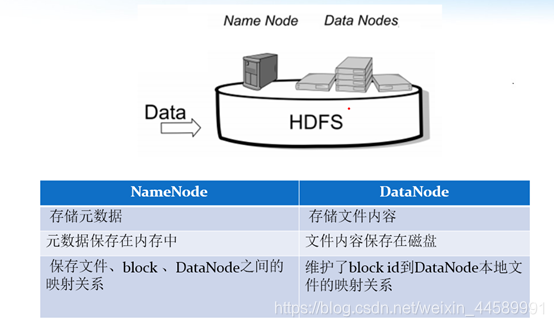
4. 扩展
- 块缓存
-
通常DataNode从磁盘中读取块,但对于访问频繁的文件,其对应的块可能被显示的缓存在DataNode的内存中,以堆外块缓存的形式存在。
-
默认情况下,一个块仅缓存在一个DataNode的内存中,当然可以针对每个文件配置DataNode的数量。作业调度器通过在缓存块的DataNode上运行任务,可以利用块缓存的优势提高读操作的性能。
例如:
连接(join)操作中使用的一个小的查询表就是块缓存的一个很好的候选。
用户或应用通过在缓存池中增加一个cache directive来告诉namenode需要缓存哪些文件及存多久。缓存池(cache pool)是一个拥有管理缓存权限和资源使用的管理性分组
- hdfs的文件权限验证
-
hdfs的文件权限机制与linux系统的文件权限机制类似
r:read w:write x:execute 权限x对于文件表示忽略,对于文件夹表示是否有权限访问其内容
如果linux系统用户zhangsan使用hadoop命令创建一个文件,那么这个文件在HDFS当中的owner就是zhangsan
HDFS文件权限的目的,防止好人做错事,而不是阻止坏人做坏事。HDFS相信你告诉我你是谁,你就是谁
hdfs 权限-》kerberos、ranger、sentry来做
3. hdfs的shell命令操作
- HDFS命令有两种风格,均可使用,效果相同:
- hadoop fs开头的
- hdfs dfs开头的
- 如何查看hdfs或hadoop子命令的帮助信息,如ls子命令
hdfs dfs -help ls
hadoop fs -help ls #两个命令等价
- 查看hdfs文件系统中指定目录的文件列表。对比linux命令ls
hdfs dfs -ls /
hadoop fs -ls /
hdfs dfs -ls -R /
- 在hdfs文件系统中创建文件
hdfs dfs -touchz /edits.txt
hdfs dfs -ls /
- 向HDFS文件中追加内容
hadoop fs -appendToFile edit1.xml /edits.txt #将本地磁盘当前目录的edit1.xml内容追加到HDFS根目录 的edits.txt文件
- 查看HDFS文件内容
hdfs dfs -cat /edits.txt
hdfs dfs -text /edits.txt
- 从本地路径上传文件至HDFS
#用法:hdfs dfs -put /本地路径 /hdfs路径
hdfs dfs -put /linux本地磁盘文件 /hdfs路径文件
hdfs dfs -copyFromLocal /linux本地磁盘文件 /hdfs路径文件 #跟put作用一样
hdfs dfs -moveFromLocal /linux本地磁盘文件 /hdfs路径文件 #跟put作用一样,只不过,源文件被拷贝成功后,会被删除
- 在hdfs文件系统中下载文件
hdfs dfs -get /hdfs路径 /本地路径
hdfs dfs -copyToLocal /hdfs路径 /本地路径 #根get作用一样
- 在hdfs文件系统中创建目录
hdfs dfs -mkdir /shell
- 在hdfs文件系统中删除文件
hdfs dfs -rm /edits.txt
将文件彻底删除(被删除文件不放到hdfs的垃圾桶里)
how?
hdfs dfs -rm -skipTrash /xcall
- 在hdfs文件系统中修改文件名称(也可以用来移动文件到目录)
hdfs dfs -mv /xcall.sh /call.sh
hdfs dfs -mv /call.sh /shell
- 在hdfs中拷贝文件到目录
hdfs dfs -cp /xrsync.sh /shell
- 递归删除目录
hdfs dfs -rm -r /shell
- 列出本地文件的内容(默认是hdfs文件系统)
hdfs dfs -ls file:///home/hadoop/
- 查找文件
# linux find命令
find . -name 'edit*'
# HDFS find命令
hadoop fs -find / -name part-r-00000 # 在HDFS根目录中,查找part-r-00000文件
- 总结
-
输入hadoop fs 或hdfs dfs,回车,查看所有的HDFS命令
-
许多命令与linux命令有很大的相似性,学会举一反三
-
有用的help,如查看ls命令的使用说明:hadoop fs -help ls
-
绝大多数的大数据框架的命令,也有类似的help信息
4. hdfs安全模式
- 安全模式是hdfs的一种保护机制,主要是为了保存block块数量的完整性,避免数据出现丢失的可能性
- 安全模式是HDFS所处的一种特殊状态
- 文件系统只接受读请求
- 不接受写请求,如删除、修改等变更请求。
- 在NameNode主节点启动时,HDFS首先进入安全模式
- DataNode在启动的时候会向namenode汇报可用的block等状态,当整个系统达到安全标准时,HDFS自动离开安全模式。
- 如果HDFS处于安全模式下,则文件block不能进行任何的副本复制操作,因此达到最小的副本数量要求是基于datanode启动时的状态来判定的
- 启动时不会再做任何复制(从而达到最小副本数量要求)
- hdfs集群刚启动的时候,默认30S钟的时间是处于安全期的,只有过了30S之后,集群脱离了安全模式,然后才可以对集群进行操作
- 何时退出安全模式
- namenode知道集群共多少个block(不考虑副本),假设值是total;
- namenode启动后,会上报block report,namenode开始累加统计满足最小副本数(默认1)的block个数,假设是num
- 当num/total > 99.9%时,退出安全模式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fA0B6P6r-1614609971930)(assets/image-20200925151612455.png)]
[hadoop@node01 hadoop]$ hdfs dfsadmin -safemode
Usage: hdfs dfsadmin [-safemode enter | leave | get | wait]
5. hdfs的java API开发
第一步:windows中的hadoop环境配置
- windows操作系统需要配置一下hadoop环境
- mac本质上是unix系统,不需要配置
- 参考文档《Windows&Mac本地开发环境配置》
第二步:创建maven工程并导入jar包
先设置一下IDEA中的maven
- 指定自己安装的maven
- 指定settings.xml
- 指定本地仓库路径
<properties>
<hadoop.version>3.1.4</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/junit/junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<minimizeJar>true</minimizeJar>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
第三步:开发hdfs的javaAPI操作
-
注意依赖下载:
- 在开始编程之前,请先确保相关依赖已经下载完成;等下图的②进度完成,且maven界面不报错
- 如果依赖下载不下来,直接使用老师提供的本地仓库文件夹,粘贴到自己的本地仓库目录即可
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tuJ1SWxK-1614609971930)(assets/image-20200925170117276.png)]
-
编写测试代码
-
如何熟悉框架api
一、api文档
二、工程关联框架源码
-
创建文件夹
编程时,注意导入正确的包
小技巧:让IDEA自动导包

//简化版
@Test
public void mkDirOnHDFS() throws IOException {
//配置项
Configuration configuration = new Configuration();
//设置要连接的hdfs集群
configuration.set("fs.defaultFS", "hdfs://node01:8020");
//获得文件系统
FileSystem fileSystem = FileSystem.get(configuration);
//调用方法创建目录;若目录已经存在,则创建失败,返回false
boolean mkdirs = fileSystem.mkdirs(new Path("/kaikeba/dir1"));
//释放资源
fileSystem.close();
}
//指定目录所属用户
@Test
public void mkDirOnHDFS2() throws IOException, URISyntaxException, InterruptedException {
//配置项
Configuration configuration = new Configuration();
//获得文件系统
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"), configuration, "test");
//调用方法创建目录
boolean mkdirs = fileSystem.mkdirs(new Path("/kaikeba/dir2"));
//释放资源
fileSystem.close();
}
//创建目录时,指定目录权限
@Test
public void mkDirOnHDFS3() throws IOException {
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://node01:8020");
FileSystem fileSystem = FileSystem.get(configuration);
FsPermission fsPermission = new FsPermission(FsAction.ALL, FsAction.READ, FsAction.READ);
boolean mkdirs = fileSystem.mkdirs(new Path("hdfs://node01:8020/kaikeba/dir3"), fsPermission);
if (mkdirs) {
System.out.println("目录创建成功");
}
fileSystem.close();
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9lbOo3QN-1614609971931)(assets/image-20201029205741024.png)]
- 文件上传
/**
* 说明:
* 将文件hello.txt上传到/kaikeba/dir1
* 如果路径/kaikeba/dir1不存在,那么结果是:
* 在hdfs上先创建/kaikeba目录
* 然后,将upload.txt上传到/kaikeba中,并将文件upload.txt重命名为dir1
* 如果路径/kaikeba/dir1存在,那么将hello.txt上传到此路径中去
*
* @throws IOException
*/
@Test
public void uploadFile2HDFS() throws IOException {
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://node01:8020");
FileSystem fileSystem = FileSystem.get(configuration);
fileSystem.copyFromLocalFile(new Path("file://E:\\模块化课程\\hadoop 3.x全解析\\2、HDFS\\3、数据\\hello.txt"),
new Path("/kaikeba/dir1"));//hdfs路径
fileSystem.close();
}
- 文件下载
@Test
public void downloadFileFromHDFS() throws IOException {
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://node01:8020");
FileSystem fileSystem = FileSystem.get(configuration);
fileSystem.copyToLocalFile(new Path("hdfs://node01:8020/kaikeba/dir1/hello.txt"), new Path("file:///C:\\mydata\\hello.txt"));
//删除文件
//fileSystem.delete()
//重命名文件
//fileSystem.rename()
fileSystem.close();
}
- 自主完成hdfs文件删除操作
- 自主完成hdfs文件重命名操作
- 查看hdfs文件相信信息
@Test
public void viewFileInfo() throws IOException, InterruptedException, URISyntaxException {
// 1获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://node01:8020"), configuration);
// 2 获取文件详情
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("hdfs://node01:8020/kaikeba/"), true);
while (listFiles.hasNext()) {
LocatedFileStatus status = listFiles.next();
// 输出详情
// 文件名称
System.out.println(status.getPath().getName());
// 长度
System.out.println(status.getLen());
// 权限
System.out.println(status.getPermission());
// 分组
System.out.println(status.getGroup());
// 获取存储的块信息
BlockLocation[] blockLocations = status.getBlockLocations();
for (BlockLocation blockLocation : blockLocations) {
// 获取块存储的主机节点
String[] hosts = blockLocation.getHosts();
for (String host : hosts) {
System.out.println(host);
}
}
}
// 3 关闭资源
fs.close();
}
IO流操作hdfs文件
- 通过io流进行数据上传操作
@Test
public void putFileToHDFS() throws IOException, InterruptedException, URISyntaxException {
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://node01:8020"), configuration);
// 2 创建输入流 不需要加file:///,否则报错
FileInputStream fis = new FileInputStream(new File("C:\\mydata\\hello.txt"));
// 3 获取输出流 父目录不存在,会自动创建
FSDataOutputStream fos = fs.create(new Path("hdfs://node01:8020/kaikeba/dir3/hello.txt"));
// 4 流对拷 org.apache.commons.io.IOUtils
IOUtils.copy(fis, fos);
// 5 关闭资源
IOUtils.closeQuietly(fos);
IOUtils.closeQuietly(fis);
fs.close();
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5tJclbRX-1614609971932)(assets/image-20200925161954948.png)]
-
自主实现通过IO流从hdfs上面下载文件
提示:fileSystem.open()
-
hdfs的小文件合并
/**
* 小文件合并:读取所有本地小文件,写入到hdfs的大文件里面去
*/
@Test
public void mergeFile() throws URISyntaxException, IOException, InterruptedException {
//获取分布式文件系统hdfs
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"), new Configuration(), "hadoop");
FSDataOutputStream fsDataOutputStream = fileSystem.create(new Path("hdfs://node01:8020/kaikeba/bigfile.xml"));
//获取本地文件系统 localFileSystem
LocalFileSystem localFileSystem = FileSystem.getLocal(new Configuration());
//读取本地的文件
FileStatus[] fileStatuses = localFileSystem.listStatus(new Path("file:///E:\\模块化课程\\hadoop 3.x全解析\\2、HDFS\\3、数据\\smallfile"));
for (FileStatus fileStatus : fileStatuses) {
//获取每一个本地的文件路径
Path path = fileStatus.getPath();
//读取本地小文件
FSDataInputStream fsDataInputStream = localFileSystem.open(path);
IOUtils.copy(fsDataInputStream, fsDataOutputStream);
IOUtils.closeQuietly(fsDataInputStream);
}
IOUtils.closeQuietly(fsDataOutputStream);
localFileSystem.close();
fileSystem.close();
}
6. NameNode和SecondaryNameNode功能剖析
1. namenode与secondaryName解析
- NameNode主要负责集群当中的元数据信息管理,而且元数据信息需要经常随机访问,因为元数据信息必须高效的检索
- 元数据信息保存在哪里能够快速检索呢?
- 如何保证元数据的持久安全呢?
- 为了保证元数据信息的快速检索,那么我们就必须将元数据存放在内存当中,因为在内存当中元数据信息能够最快速的检索,那么随着元数据信息的增多(每个block块大概占用150字节的元数据信息),内存的消耗也会越来越多。
- 如果所有的元数据信息都存放内存,服务器断电,内存当中所有数据都消失,为了保证元数据的安全持久,元数据信息必须做可靠的持久化,在hadoop当中为了持久化存储元数据信息,将所有的元数据信息保存在了FSImage文件当中,那么FSImage随着时间推移,必然越来越膨胀,FSImage的操作变得越来越难,为了解决元数据信息的增删改,hadoop当中还引入了元数据操作日志edits文件,edits文件记录了客户端操作元数据的信息,随着时间的推移,edits信息也会越来越大,为了解决edits文件膨胀的问题,hadoop当中引入了secondaryNamenode来专门做fsimage与edits文件的合并
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B2r6QgkY-1614609971932)(assets/image-20200925164802493.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Mm1cxElt-1614609971933)(assets/checkpoint.gif)]
-
namenode工作机制
(1)第一次启动namenode格式化后,创建fsimage和edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求
(3)namenode记录操作日志,更新滚动日志。
(4)namenode在内存中对数据进行增删改查
-
Secondary NameNode工作
(1)Secondary NameNode询问namenode是否需要checkpoint。直接带回namenode是否检查结果。
(2)Secondary NameNode请求执行checkpoint。
(3)namenode滚动正在写的edits日志
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint
(7) 拷贝fsimage.chkpoint到namenode
(8)namenode将fsimage.chkpoint重新命名成fsimage
| 属性 | 值 | 解释 |
|---|---|---|
| dfs.namenode.checkpoint.period | 3600秒(即1小时) | The number of seconds between two periodic checkpoints. |
| dfs.namenode.checkpoint.txns | 1000000 | The Secondary NameNode or CheckpointNode will create a checkpoint of the namespace every ‘dfs.namenode.checkpoint.txns’ transactions, regardless of whether ‘dfs.namenode.checkpoint.period’ has expired. |
| dfs.namenode.checkpoint.check.period | 60(1分钟) | The SecondaryNameNode and CheckpointNode will poll the NameNode every ‘dfs.namenode.checkpoint.check.period’ seconds to query the number of uncheckpointed transactions. |
2. FSImage与edits详解
- 所有的元数据信息都保存在了FsImage与Eidts文件当中,这两个文件就记录了所有的数据的元数据信息,元数据信息的保存目录配置在了hdfs-site.xml当中
<!-- namenode保存fsimage的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///kkb/install/hadoop-3.1.4/hadoopDatas/namenodeDatas</value>
</property>
<!-- namenode保存editslog的目录 -->
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///kkb/install/hadoop-3.1.4/hadoopDatas/dfs/nn/edits</value>
</property>
-
客户端对hdfs进行写文件时会首先被记录在edits文件中
edits修改时元数据也会更新。
每次hdfs更新时edits先更新后,客户端才会看到最新信息。
fsimage:是namenode中关于元数据的镜像,一般称为检查点。
一般开始时对namenode的操作都放在edits中,为什么不放在fsimage中呢?
因为fsimage是namenode的完整的镜像,内容很大,如果每次都加载到内存的话生成树状拓扑结构,这是非常耗内存和CPU。
fsimage内容包含了namenode管理下的所有datanode中文件及文件block及block所在的datanode的元数据信息。随着edits内容增大,就需要在一定时间点和fsimage合并。
3. FSimage文件当中的文件信息查看
-
使用命令 hdfs oiv
cd /kkb/install/hadoop-3.1.4/hadoopDatas/namenodeDatas/current
hdfs oiv #查看帮助信息
hdfs oiv -i fsimage_0000000000000000864 -p XML -o /home/hadoop/fsimage1.xml
4. edits当中的文件信息查看
-
查看命令 hdfs oev
cd /kkb/install/hadoop-3.1.4/hadoopDatas/dfs/nn/edits/current
hdfs oev #查看帮助信息
hdfs oev -i edits_0000000000000000865-0000000000000000866 -o /home/hadoop/myedit.xml -p XML
5. namenode元数据信息多目录配置
-
为了保证元数据的安全性
- 我们一般都是先确定好我们的磁盘挂载目录,将元数据的磁盘做RAID1 namenode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性。
- 多个目录间逗号分隔
-
具体配置如下:
hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///kkb/install/hadoop-3.1.4/hadoopDatas/namenodeDatas,file:///path/to/another/</value>
</property>
五、拓展点、未来计划、行业趋势
sudo yum -y install tree
tree path
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dN4VgiYY-1614609971933)(assets/image-20201029212854135.png)]
- 画图工具draw io下载地址
- markdown课件,配套软件:https://www.typora.io/
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eb7lvaRx-1614609971934)(assets/image-20200930100340138.png)]
六、总结
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qTNr4CGR-1614609971934)(assets/image-20201029213157065.png)]
七、作业
练习:
- 基本的hdfs命令练习下
- 自主完成hdfs文件删除操作
- 自主完成hdfs文件重命名操作