文章目录
HDFS
HDFS(Hadoop Distributed File System),Hadoop分布式文件系统- 是
Apache Hadoop的核心组件之一,作为大数据生态圈最底层的分布式存储服务而存在。大数据首先要解决的问题就是海量数据的存储问题
HDFS设计目标
- 核心架构目标:
故障检测和自动快速恢复,HDFS可能由成百上千台服务器组成,每一个组件都有可能出现故障 流式读取数据(Streaming Data Access),HDFS被设计为用于批处理,更注重数据访问的高吞吐量支持大文件,HDFS的文件大小为GB-TB级别一次写入多次读取(write-one-read-many),一个文件一旦创建、写入、关闭之后就不需要修改了,简化了数据一致性问题- 将计算移动到数据附近,
移动计算的代价比移动数据的代价低 平台移植性,可以从一个平台轻松移植到另一个平台
HDFS应用场景
-
大文件
-
流式数据访问
-
一次写入多次读取
-
低成本部署
-
高容错
-
不适合场景:小文件、数据交互式访问、频繁任意修改、低延迟处理
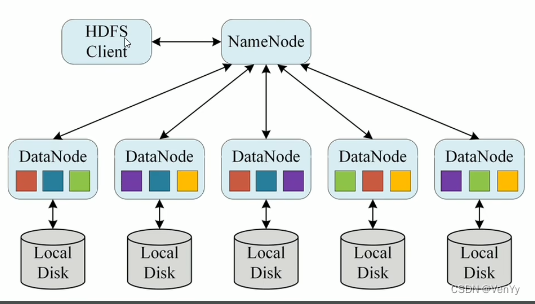
整体概述
- 主从架构:master/slave,一个namenode,多个datanode,两种角色各司其职、共同协调完成分布式文件存储服务
- 分块存储:每个数据被分为多个block,每一个block都可以在多个DataNode上存储,默认大小为128M,不足128M为一块。块的大小由
hdfs-defaults.xml中的dfs.blocksize设定 - 副本机制:每个block有多个备份replication,副本数由
dfs.replication设定,默认3份 - 元数据记录:metadata记录每一块数据的信息
- 文件自身属性信息:文件名称、权限、修改时间、文件大小、复制因子、数据块大小
- 文件块位置映射信息:记录文件块和DataNode之间的映射关系,即哪个块位于哪个节点上
- 抽象统一的目录树结构
各角色职责
主角色:NameNode
- NameNode是Hadoop分布式文件系统的核心,负责
维护和管理文件系统元数据, - 是
访问HDFS的唯一入口 - NameNode内部通过
内存和磁盘文件两种方式管理元数据
从角色:DataNode
- 负责具体的
数据块存储 - 决定了HDFS集群的整体数据存储能力
主角色辅助角色:SecondaryNameNode
- 充当NameNode的辅助节点,但不能替代NameNode
- 主要是帮助主角色进行元数据文件的合并动作
NameNode职责
- 仅
存储HDFS的元数据,不存储实际数据 - 知道HDFS中任何给定文件的块列表及其位置
不持久化存储各个块所在的DataNode位置信息,这些信息会在系统启动时从DataNode重建- 是Hadoop集群中的
单点故障 - NameNode所在机器通常会配置有大量内存
DataNode职责
- 负责最终数据块block的存储
- DataNode启动时,会将自己注册到NameNode并汇报自己负责持有的块列表
- 某个DataNode关闭时,不影响数据的可用性。NameNode将安排由其他DataNode管理的块进行副本复制
- DataNode所在机器通常配置有大量的硬盘空间
HDFS写数据流程
核心概念–Pipline管道
-
pipline,是HDFS在上传文件写数据过程中采用的一种数据传输方式
-
客户端将数据写入第一个数据节点,第一个数据节点保存数据之后再将块复制到第二个数据节点,后者保存后将块复制到下一个数据节点
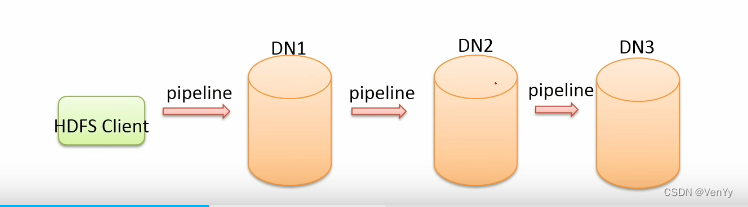
-
数据以管道的方式,顺序的沿着一个方向传输,能够充分利用每台机器的带宽,避免网络瓶颈和高延迟