Hadoop基础-HDFS分布式文件系统的存储
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.HDFS数据块
1>.磁盘中的数据块
每个磁盘都有默认的数据块大小,这个磁盘进行数据读/写的最小单位,构建于单个磁盘之上的上文件系统通过磁盘来管理该文件中的块,该文件系统块的大小可以是磁盘块的整数倍。文件系统块一般为几千字节,而磁盘快一般为512字节。这个信息(文件系统块大小)对于需要读/写文件的文件系统用户来说是透明的。尽管如此,系统仍然提供了一些工具(如df和fsck)来维护系文件系统,由它们对文件系统中的块进行操作。
2>.HDFS的数据块
HDFS同样也有块(block)的概念,但是大得多,默认为128MB(既然我这里说默认,那自然是可以这个默认属性的哟!)。与单一磁盘上的文件系统相似,HDFS上的文件也被划分为块大小的多个分块(chunk),作为独立的存储单元。但与面向单一磁盘的文件系统不同的是,HDFS中小于一个块大小的文件不会占据整个块的空间(例如,当一个1MB的文件存储在一个128MB的块中时,文件只使用1MB的磁盘空间,而不是128MB)。
3>.为什么HDFS中块默认是128M
HDFS的块比磁盘的块大,其目的是为了最小化寻址开销。如果块足够大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。因而,传输一个由多个块组成的大文件的时间取决于磁盘传输速率。
我们来做一个运算,如果寻址时间约为10ms,机械硬盘传输速率(磁盘速率)为100MB/s,为了使寻址时间仅占传输时间的1%,我们要将块大小设置约为100MB,Hadoop2.x的版本默认的块大小实际为128MB,初学者的小伙伴会很费解这个128是怎么来的,以及在Hadoop1.x的版本,默认大小为64MB。一开始我也很懵逼,但是根据这两个数字大家是否想到了二进制?在Java中一个int类型的它需要占用4个字节,每一个字节有8个比特位,而一个字节每个比特位代表的数据是不同的,一个字节从右往左大小依次是:“1,2,4,8,16,32,64,128,256,512,1024,.....”等等。考虑有些笔记本的硬盘传输速度在60MB/s~90MB/之间。Hadoop1.x那些大佬们就取一个好记的数组,也就是我们上面说的64MB/s;随着技术的提升,我们机械硬盘速率在100MB/s~190MB/s,Hadoop2.x那些大佬们就取一个好记的数组,也就是我们上面说的128MB/s;但是很多情况下HDFS安装时使用更大的块。以后随着新一代磁盘驱动器传输速率的提示,块的大小会被设置的更大。比如目前主流固态硬盘的速率在450/MB~550/MB之间,估计也没有哪家企业能把机械硬盘都干掉,而是采用固态硬盘来存取数据,随着技术的提升,将来硬盘速度上的提升也是一个必然趋势。我也大胆猜测,当机械硬盘的普遍的传输速度提升到300MB/s左右时,Hadoop官方的大佬们又会再一次修改目前的128MB大小,很有可能默认大小为256MB/s哟!
4>.对分布式文件系统(HDFS)中的块进行抽取的好处
第一个最明显的好处是,一个文件的大小可以大于网络中任意一个磁盘的容量。文件的所有块并不需要存储在同一个磁盘上,因此他们可以利用集群上的任意一个磁盘进行存储。事实上,尽管不常见,但对于整个HDFS集群而言,也可以仅存储一个文件,该文件的块沾满集群中所有的磁盘。
第二个好处是,使用抽象块而非整个文件作为存储单元,大大简化了存储子系统的设计。简化是所有系统的目标,但是这对于故障种类繁多的分布式系统来说尤为重要。将存储子系统的处理对象设置为块,可以简化存储管理(由于块的大小是固定的,因此计算单个磁盘能存储多少个块就相对容易)。同时也消除了对元数据的顾虑(块只是要存储的大块数据,而文件的元数据,如权限信息,并不需要与块一同存储,这样一来,其他系统就可以单独管理这个元数据)。
第三个好处是,块还非常社会用于数据备份进而提供数据容错能力和提高可用性。将每个块复制到少数几个物理上互相独立的服务器上(默认为3个),可以确保在块,磁盘或机器发生故障后数据不会丢失。如果发现一个块不可用,系统会自动从其他地方读取另一个复本,而这个过程对用户是透明的。一个因损坏机器故障而丢失的块可以从其他候选地点复制到另一台可以正常运行的机器上,以保证复本的数量回到正常水平,同样,有些应用程序可能选择为一些常用的文件块设置更高的复本数量进而分散集群的读取负载。
第四个好处是,与磁盘文件系统相似,HDFS中fsck指令可以显示块信息,例如,执行命令“hdfs fsck / -files -blocks”将会列出文件系统中各个文件由哪些块组成
二.Hadoop文件存储
1>.上传文件到服务器
服务端上传文件:
[yinzhengjie@s101 ~]$ ll -h total 382M drwxrwxr-x. 3 yinzhengjie yinzhengjie 16 May 27 00:01 hadoop drwxr-xr-x. 9 yinzhengjie yinzhengjie 4.0K Aug 17 2016 hadoop-2.7.3 -rw-rw-r--. 1 yinzhengjie yinzhengjie 205M Aug 26 2016 hadoop-2.7.3.tar.gz -rw-rw-r--. 1 yinzhengjie yinzhengjie 177M May 17 2017 jdk-8u131-linux-x64.tar.gz -rwxrwxr-x. 1 yinzhengjie yinzhengjie 615 May 26 23:24 xcall.sh -rwxrwxr-x. 1 yinzhengjie yinzhengjie 742 May 26 23:29 xrsync.sh [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ hdfs dfs -put xcall.sh / [yinzhengjie@s101 ~]$ hdfs dfs -put xcall.sh hadoop-2.7.3.tar.gz / [yinzhengjie@s101 ~]$ hdfs dfs -ls / Found 2 items -rw-r--r-- 3 yinzhengjie supergroup 214092195 2018-05-27 00:16 /hadoop-2.7.3.tar.gz -rw-r--r-- 3 yinzhengjie supergroup 615 2018-05-27 00:15 /xcall.sh [yinzhengjie@s101 ~]$
客户端查看HDFS上实际存储的文件:(从图形界面中可以体验出图形的上传过程)
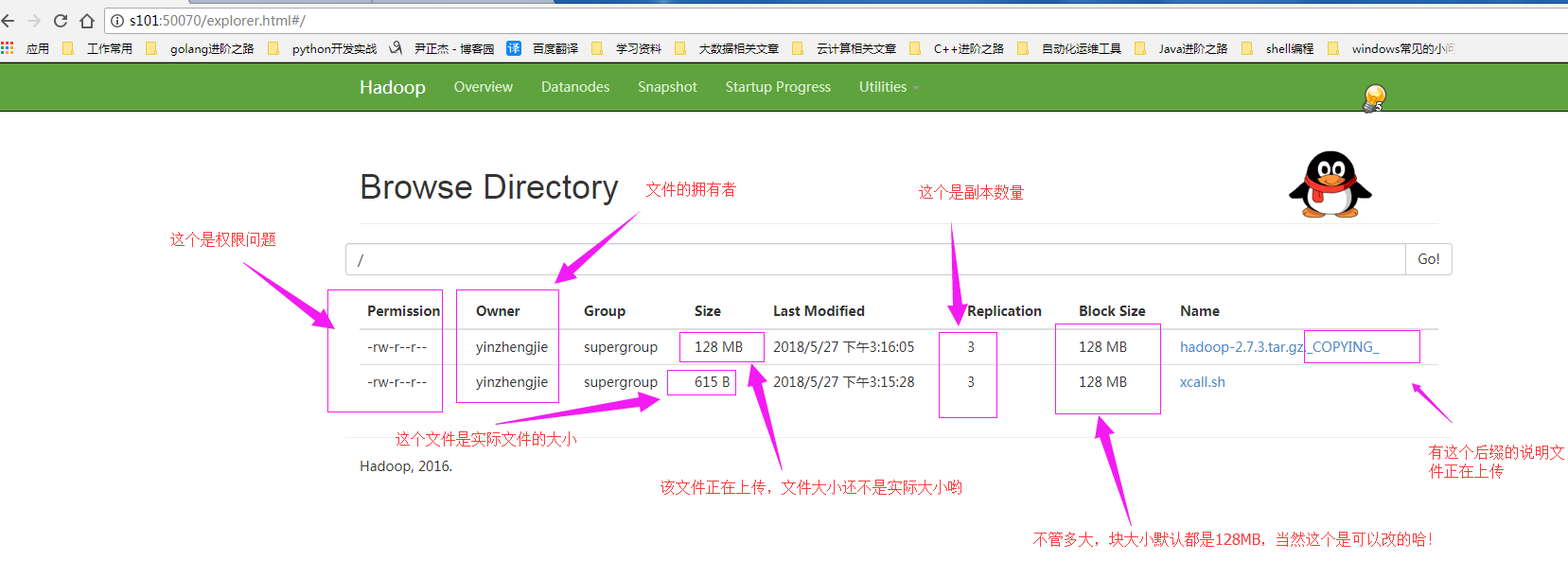
客户端查看上传成功的文件(这个时候我们可以看到上传完后的文件是没有“COPYING”后缀的文件啦!)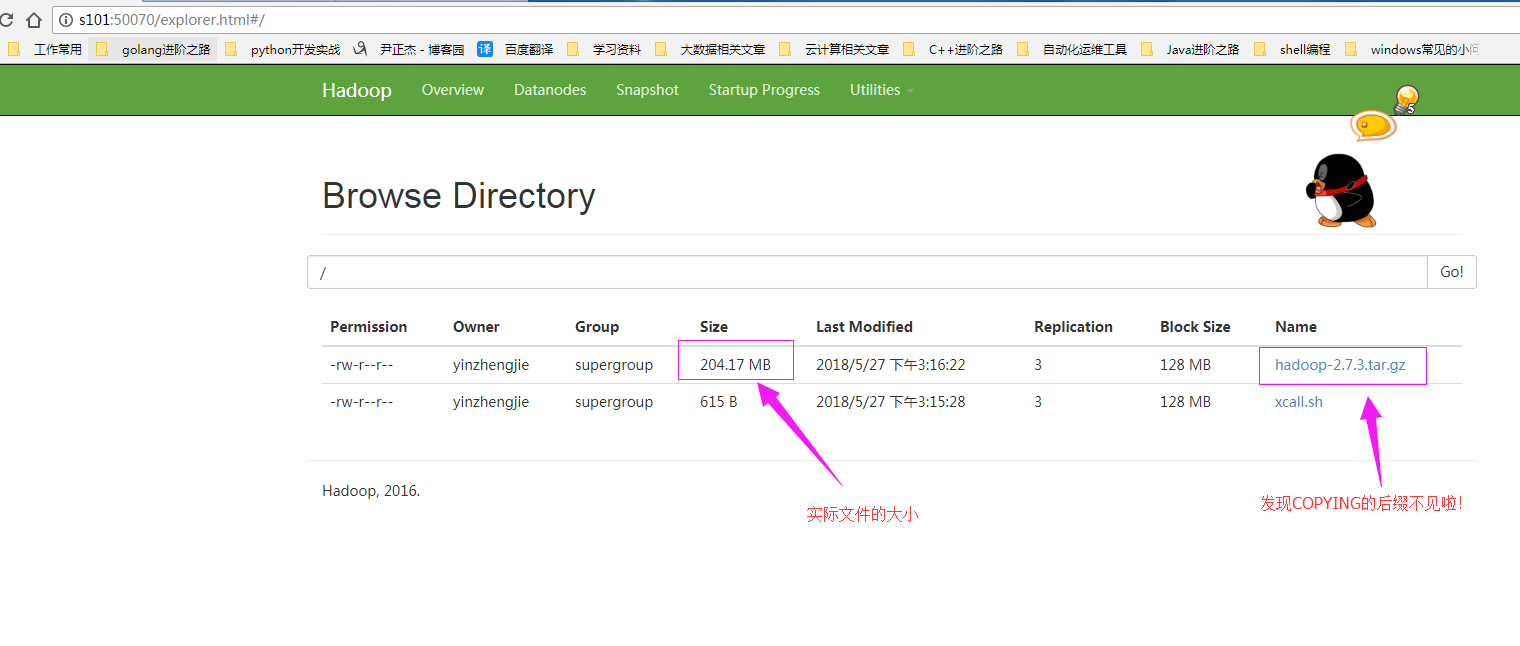
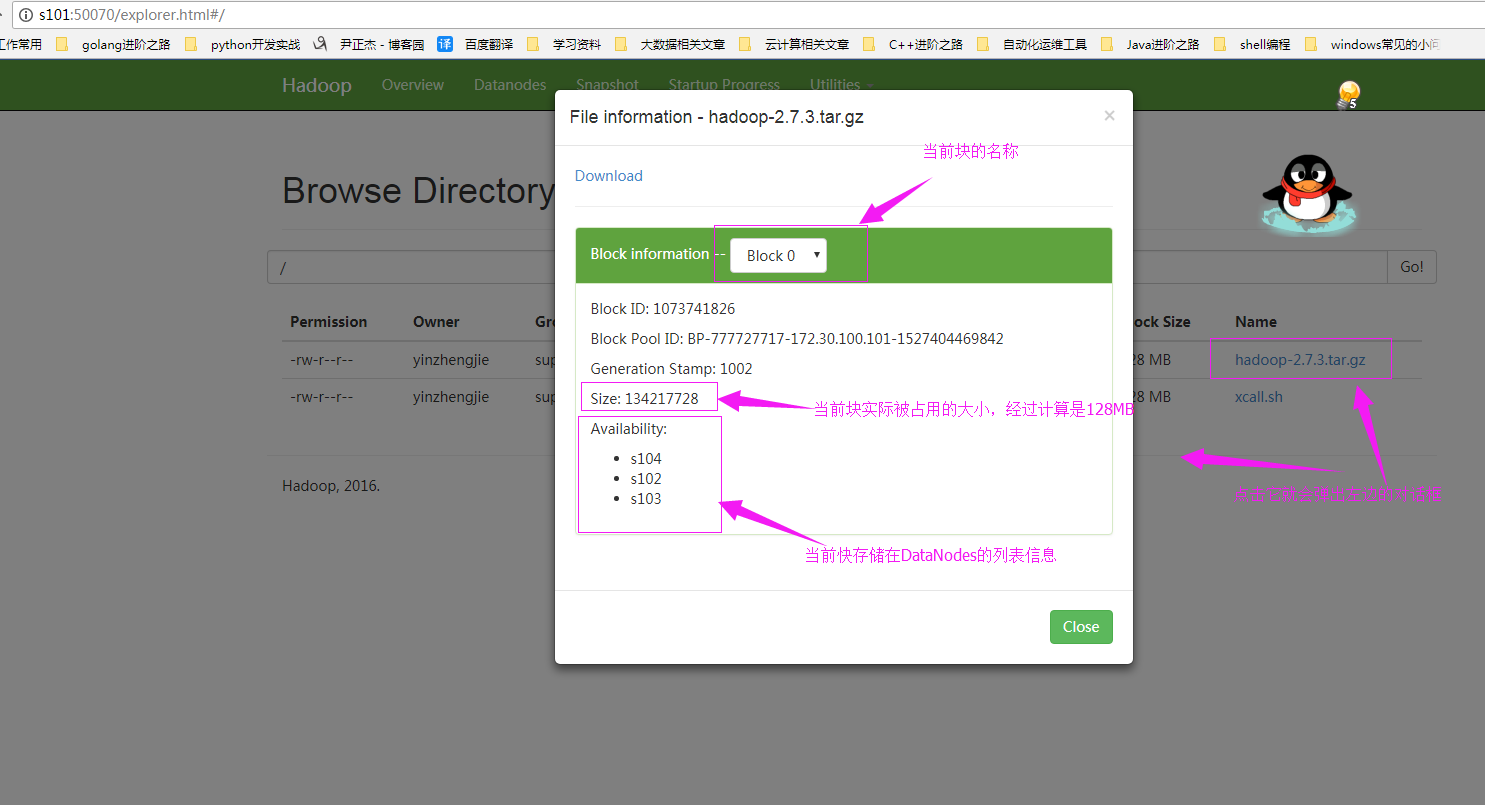
2>.查看存储的块信息
查看“hadoop-2.7.3.tar.gz”实际存储的块信息,下图为“Block 0”的信息
查看“hadoop-2.7.3.tar.gz”实际存储的块信息,下图为“Block 1”的信息
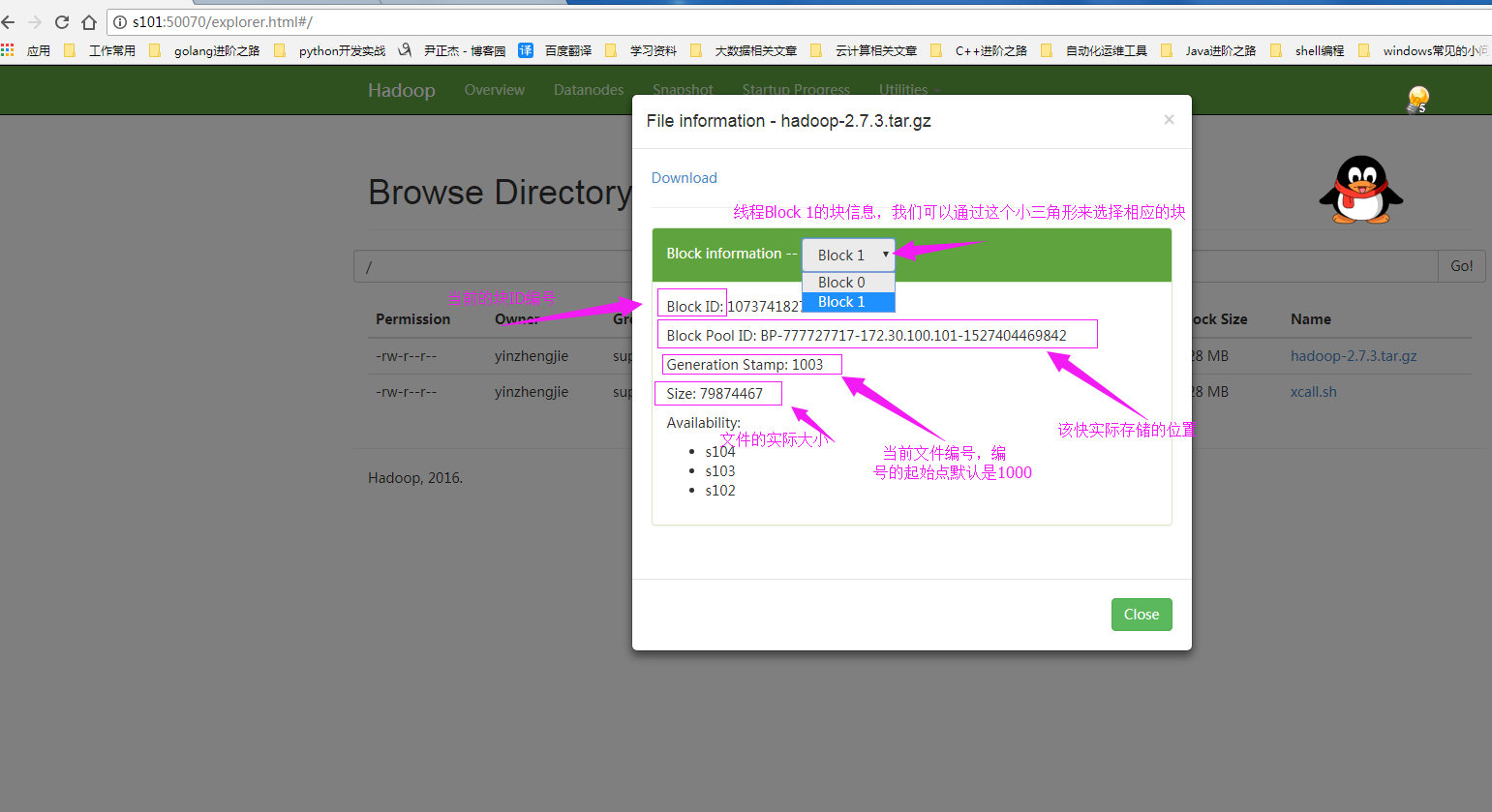
3>.