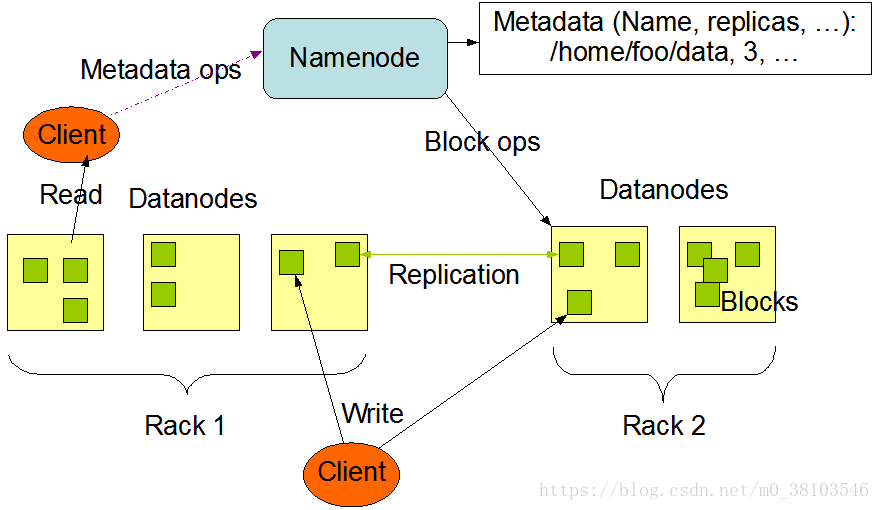
HDFS架构图
HDFS特点:高容错;高吞吐量;在项目中处理大数据集;流式访问文件系统数据;可以构建在普通的硬件之上。
采用master/slave架构,主要组成组件有:Client、NameNode、SecondaryNameNode、DataNode。
(1)Client
用户,通过与NameNode和DataNode交互访问HDFS中的文件,Client提供一个类似POSIX的文件系统接口供用户调用。
(2)NameNode
运行在master结点上整个hadoop集群中只有一个NameNode。它负责HDFS的目录树和相关文件元数据信息。

在磁盘上也会有一个文件也存储一份元数据(fsimage),edits文件保存了对文件系统的修改(也属于元数据的一种),fsimage中存储整个HDFS的元数据,随着时间的推移,文件越来越大,当文件变大时,直接对文件系统的修改保存到fsimage中代价会比较大(内存占用,修改时间等),此时可以将修改到edits文件(文件较小)中,当这个文件达到一定的条件时,将edits问价和fsimage文件合并;
NameNode还负责监控DataNode的健康状态,一旦发现DataNode挂掉,则将该DataNode移出HDFS并重新备份上面的数据。
NameNode的恢复:NameNode恢复后,一般满足(将命名空间的fsimage导入内存中;重做编辑日志---edits文件;接收到足够多的来自datanode的数据块报告并退出安全模式)等情形后才能恢复相应服务。对于一个大型并拥有大量文件和数据块的集群,namenode的冷启动时间需要30分钟,甚至更多。
(3)SecondaryNameNode
运行在master结点上,是NameNode的备份,但是并不是standby,主要负责定期合并fsimage和edits日志文件,并传输给NameNode。
(4)DataNode
一般,每个slave节点上安装一个datanode。对文件系统客户端的请求提供读写服务;基于NameNode对block执行创建,删除,复制备份;在备份期间提供同时对datanodes进行发送、接收操作。DataNode以固定大小的block为基本单位组织文件内容,默认情况下block的大小为64M。当用户上传一个大文件到HDFS上时,该文件会被切割成若干个block,分别存储到不同的datanode,同时,为了保证数据可靠性,会将同一个block以流水线方式写到若干个(默认为3)不同的datanode上。文件切割后存储的过程对用户透明。datanode会通过心跳定期向namenode发送所存储文件列表信息,当对hdfs文件系统进行读写时,namenode告知客户端数据驻留在哪个datanode,然后客户端直接与datanode进行通信,此外,datanode还会与其他的datanode进行通信,复制这些块以实现冗余。
HDFS关键字定义
Blocks(块):存储在HDFS上的文件都会被切割成数据块进行存储,当文件在网络上的两个结点之间传输时,为了保证数据的可靠性,采用校验和的方式,当传输文件时,将校验和也一起传输,在接收端对接受的文件计算校验和,然后与传过来的校验和进行比较,若发现错误则重传。
Replication Factor(复制因子):备份的数量,默认数值为3,在hdfs-site.xml文件中配置。
Shell
使用shell命令操作存储在HDFS上的数据,通用的命令格式为hadoop command [选项]
