背景
HDFS(Hadoop Distributed File System)源自于Google发表于2003年10月的GFS论文,HDFS是GFS克隆版。它是一个易于扩展的分布式文件系统,可以运行在大量普通廉价机器上,它提供容错机制,为大量用户提供性能不错的文件存取服务。
它具有以下优点:
- 高容错性:数据自动保存多个副本, 副本丢失后,自动恢复
- 适合批处理:移动计算而非数据,数据位置暴露给计算框架
- 适合大数据处理:GB、TB、甚至PB级数据,百万规模以上的文件数量,10K+节点规模
- 流式文件访问:一次性写入,多次读取,保证数据一致性
- 可构建在廉价机器上 :通过多副本提高可靠性,提供了容错和恢复机制
它也具有以下缺点:
- 高延迟数据访问:HDFS像火车,高吞吐率,高延迟,比较笨重;
- 对大量小文件存取支持不好:HDFS对亿级以上的大量小文件存取支持不好,NameNode占用大量内存,寻道时间超过读取时间
- 不支持并发写入:一个文件只能有一个写者,不支持并发写入,只能一个一个的写入;
- 文件不支持修改:HDFS文件不支持修改,只支持追加,或是添加新文件,删除原文件。
HDFS架构
HDFS设计思想
分布式文件系统的一种实现方式
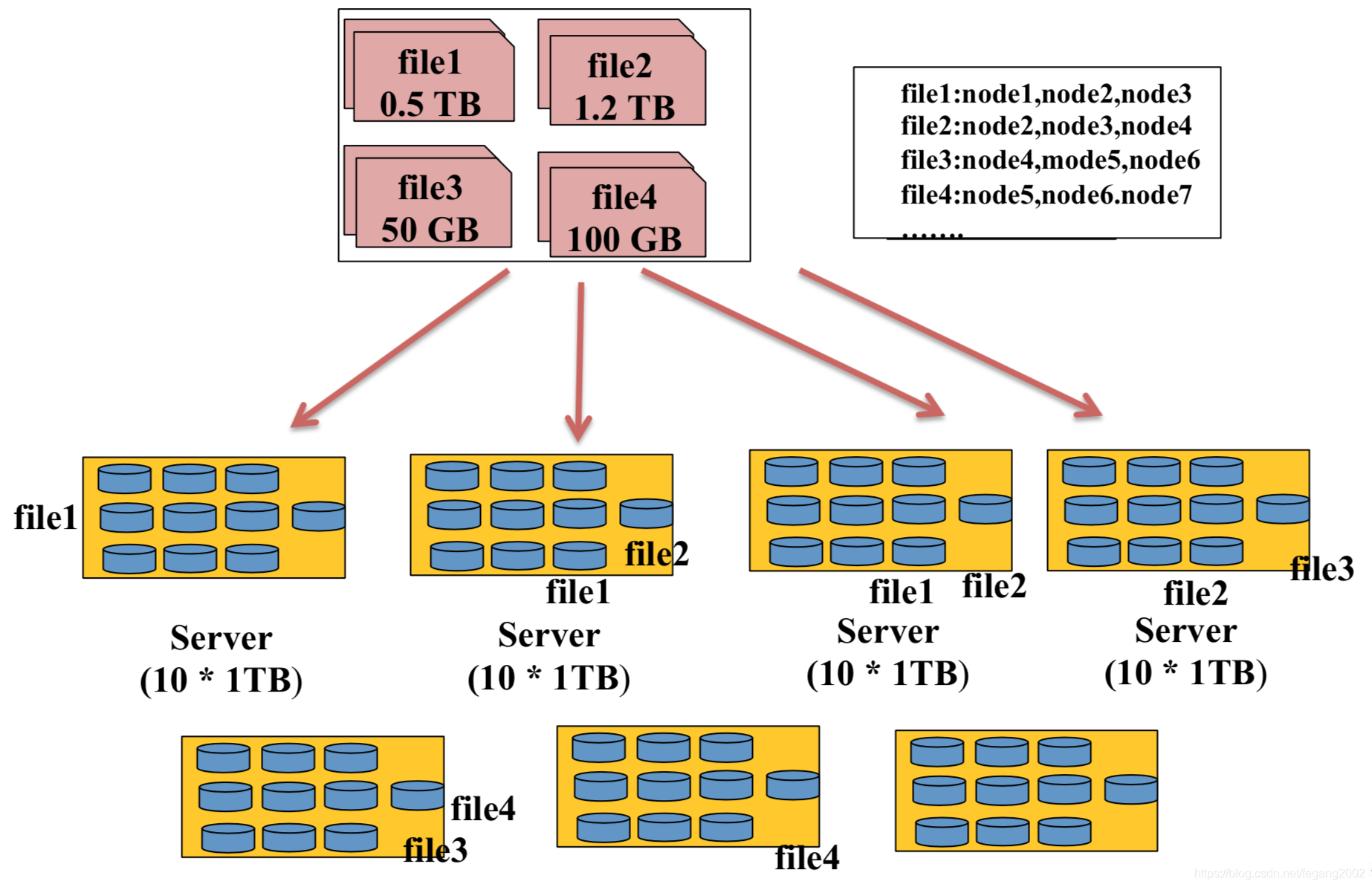 以上方案不好做负载均衡和容错,不支持计算框架的并行处理。HDFS将每个文件分成等大的数据块(默认128M),然后分成多副本(默认3个)均匀的放在不同的节点上,解决了负载均衡和容错的问题,同时也支持计算框架的并行运算。
以上方案不好做负载均衡和容错,不支持计算框架的并行处理。HDFS将每个文件分成等大的数据块(默认128M),然后分成多副本(默认3个)均匀的放在不同的节点上,解决了负载均衡和容错的问题,同时也支持计算框架的并行运算。

HDFS架构
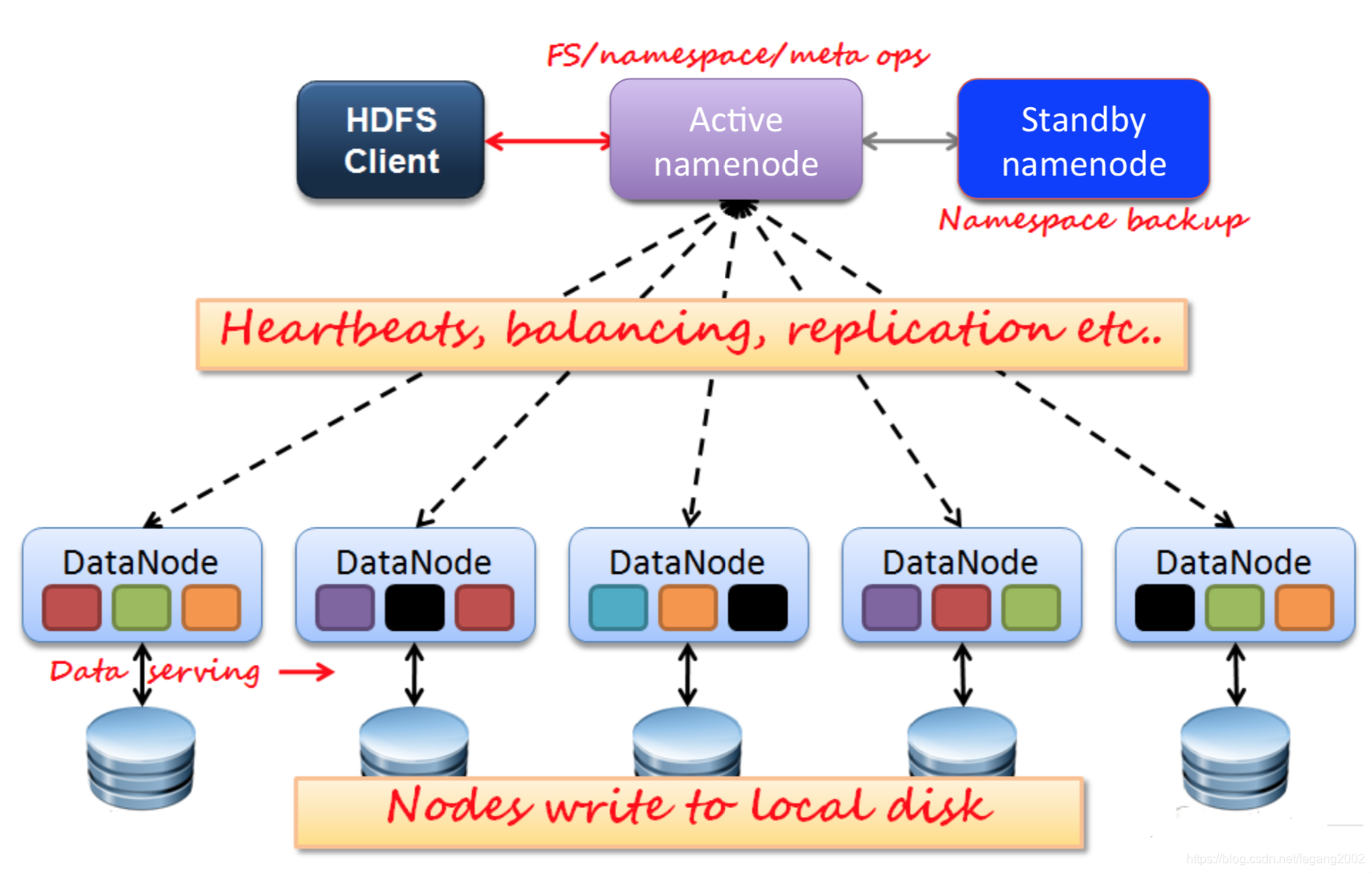 HDFS是主从架构:NameNode为主Master,DataNode为从Slave。使用NameNode存储元信息;使用DataNode存储实际数据信息。
HDFS是主从架构:NameNode为主Master,DataNode为从Slave。使用NameNode存储元信息;使用DataNode存储实际数据信息。
- NameNode
HDFS使用两个NameNode(Active NameNode和Standby NameNode)防止单点故障。Active NameNode只有一个,管理HDFS的名称空间和数据块映射信息,配置副本策略,处理客户端读写请求;Standby NameNode为Active NameNode的热备,与Active NameNode保持一致,定期合并Fsimage和 Edits,推送给Active NameNode;当Active NameNode出现故障时,快速切换为新的Active NameNode。
NameNode包括fsimage和 Edits两个重要文件:
1)Fsimage:元数据镜像文件(保存文件系统的目录树);
2)Edits:元数据操作日志(针对目录树的修改操作),被
写入共享存储系统中 ,比如NFS、JournalNode 。
为防止机器重启,元信息从内存丢失,使用Fsimage和Edits来负责元数据的存储。一般一个小时从内存往硬盘写一次Fsimage,Edits会记录在写入Fsimage镜像的时候的变化。所以,Fsimage+Edits是最新的元数据镜像。这两个文件非常重要,Active NameNode和Standby NameNode会各存一份外。Edits文件过大将导致NameNode重启速度慢 ,所以Standby Namenode负责定期合并它们。 - DataNode
DataNode有多个,主要执⾏数据块读/写,存储实际的数据块。 - Client
Client可以是NameNode,也可以是DataNode,它负责管理HDFS和访问HDFS,与NameNode交互,获取文件位置信息;与DataNode交互,读取或者写入数据。文件的切分和组合由HDFS后台完成,由Client在上传文件的时候就开始切分了。Client传递命令,比如hdfs –ls等到服务器。
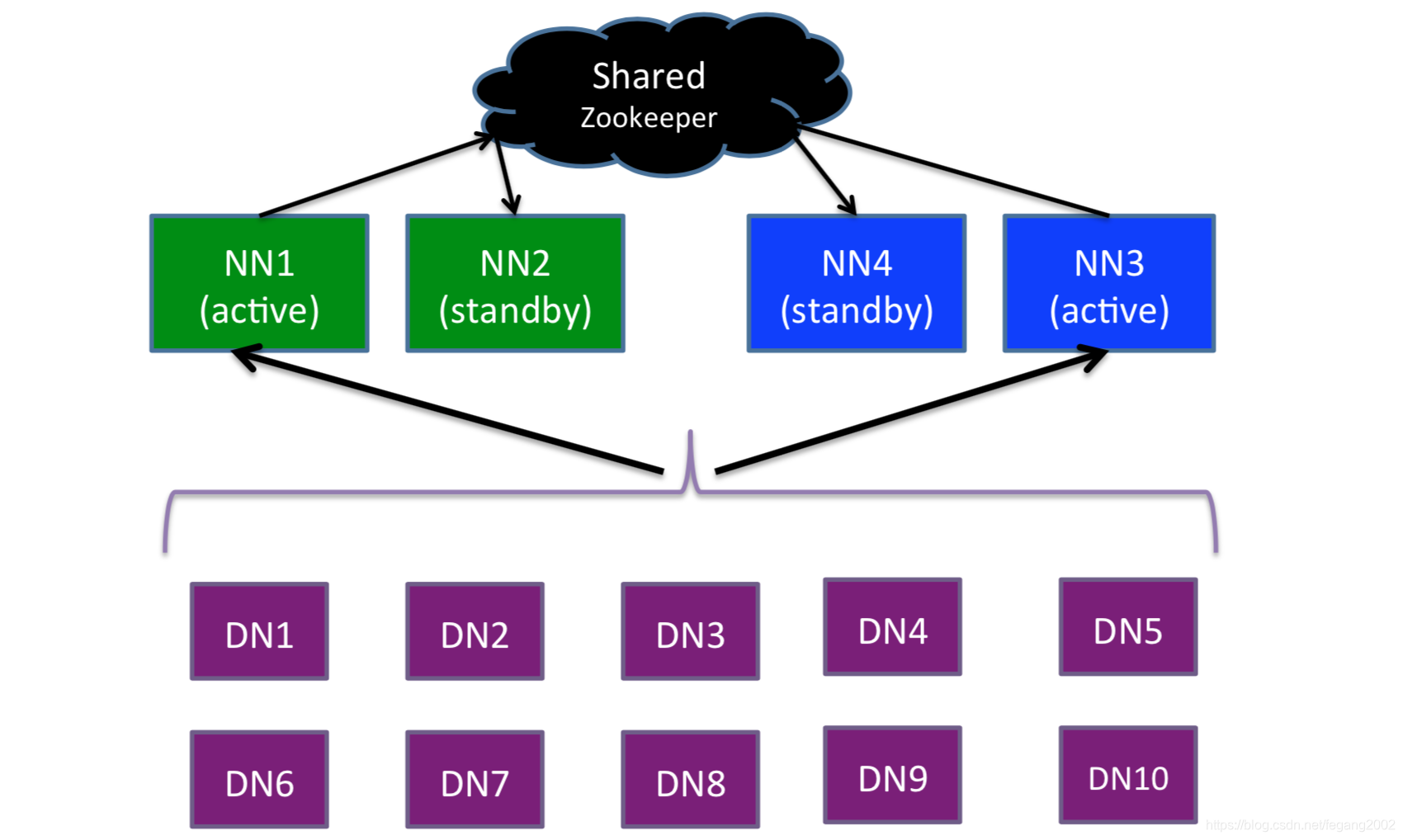
HDFS的HA和Federation
HA(High Ability):用多个Active NameNode 和Standby NameNode的方式防止单点故障,保证高可用性。
Federation:文件比较多的情况下,用联邦,用多个NameNode来管理不同的文件夹或服务。
HDFS内部机制
HDFS数据读写
HDFS文件被切分成固定大小的数据块,默认数据块大小为128MB(设置这个大小为了防止寻道时间大于数据传输时间,符合HDFS高吞吐率的要求,这个大小支持配置),若文件大小不到128MB,则单独存成一个Block。一个文件,按大小被切分成若干个Block,存储到不同节点上,默认情况下每个Block有三个副本。
- 写数据
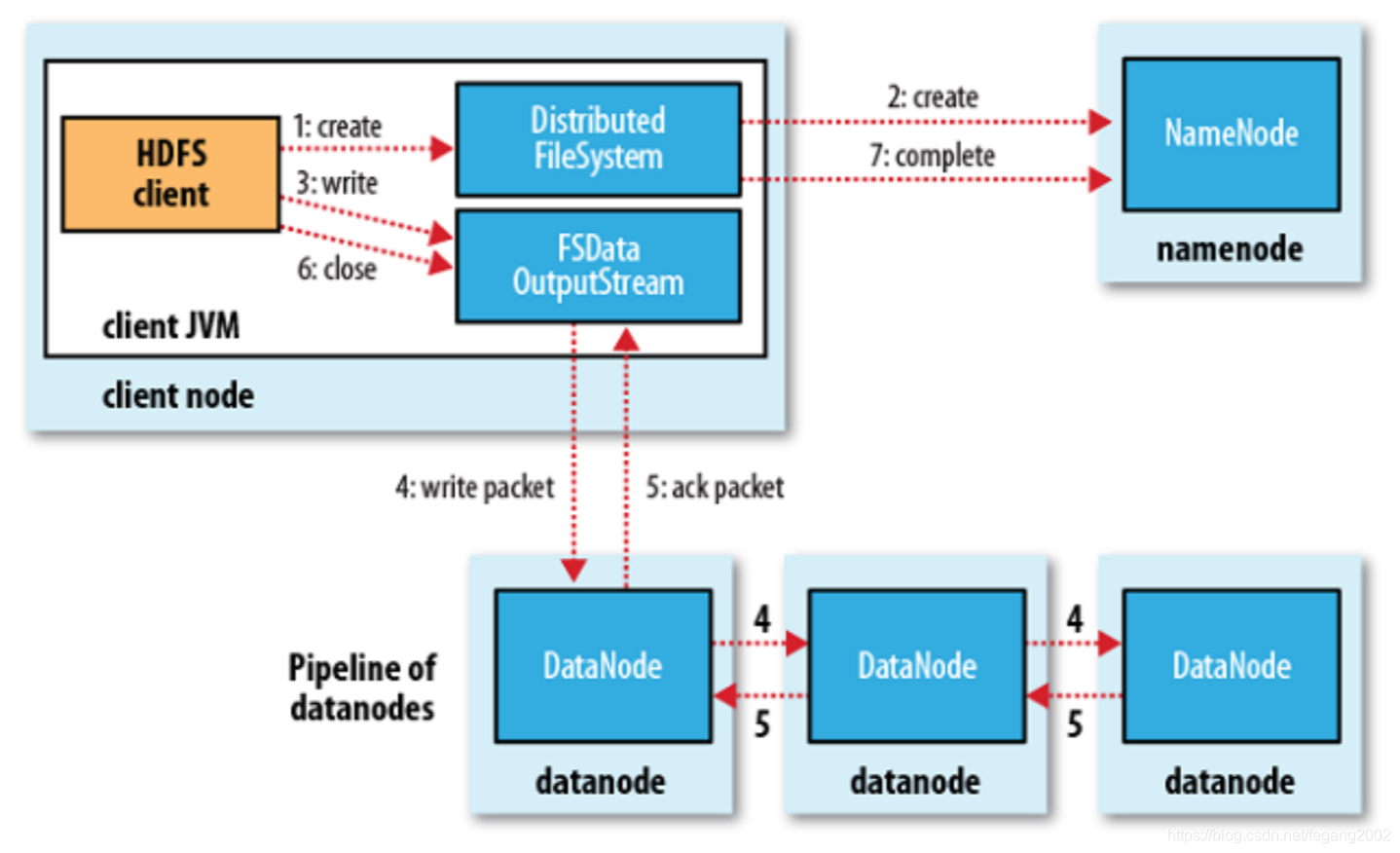
客户端Client请求写数据,NameNode判断是否可以写(是否HDFS上已经有同样名字的文件),可以写的话客户端将文件切分成Block,从NameNode请求三个DataNode地址,将数据写入DataNode,写的过程中是先往一个DataNode写,然后DataNode之间互相传递数据,这样可以缓解Client的网络出口瓶颈。NameNode选择存放的DataNode会采用负载均衡策略,优先选择磁盘利用率最低的磁盘写入。 - 读数据
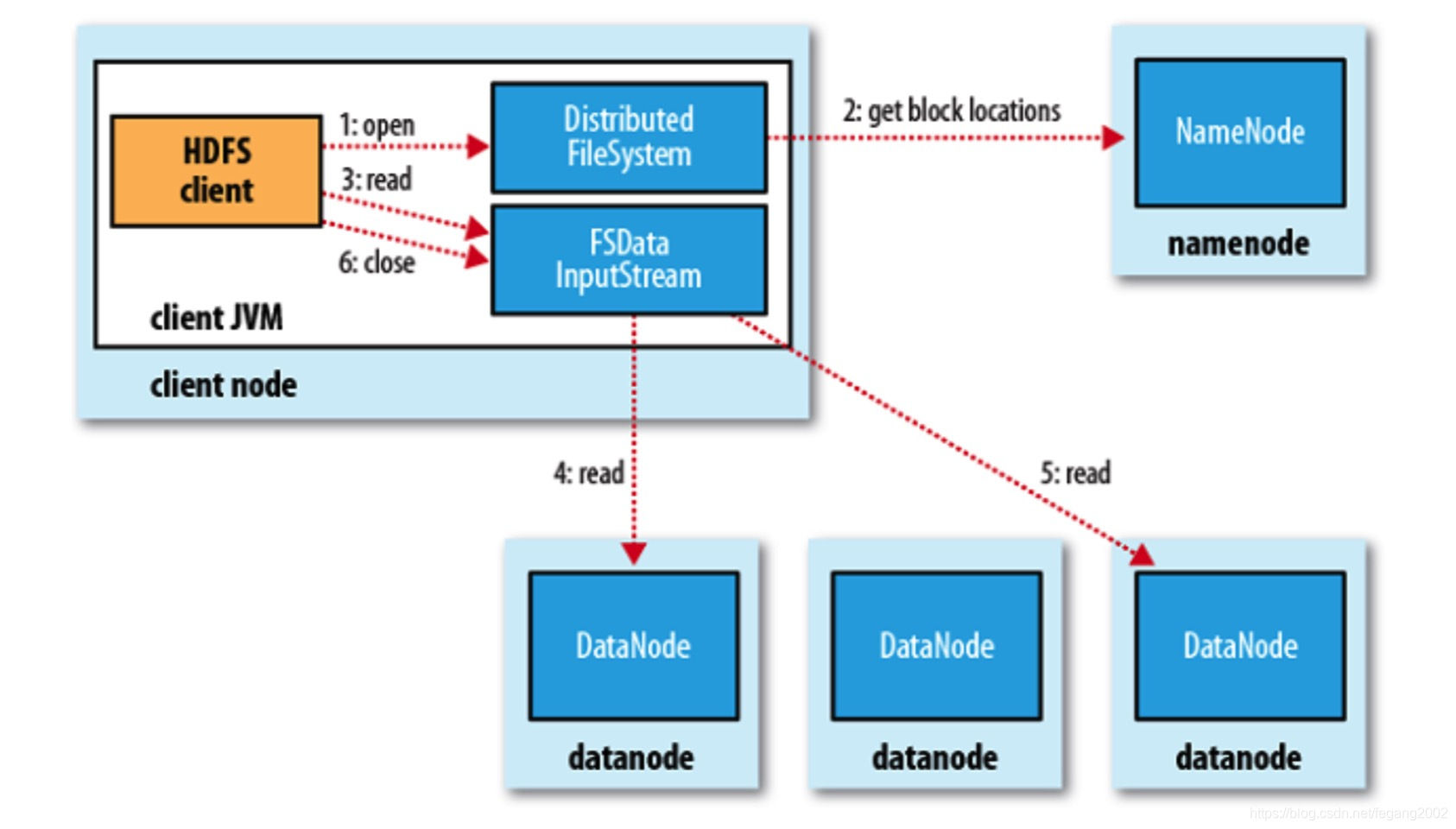 数据读取的时候,NameNode会告知有几个Block以及各个Block的地址,然后一个Block一个Block的读。只在刚开始的时候NameNode交互,得到地址,后续读数据都是跟DataNode交互。
数据读取的时候,NameNode会告知有几个Block以及各个Block的地址,然后一个Block一个Block的读。只在刚开始的时候NameNode交互,得到地址,后续读数据都是跟DataNode交互。
HDFS不适合存储小文件:
1)元信息存储在NameNode内存中,而一个节点的内存是有限的,所以NameNode存储Block数目是有限的,一个Block元信息消耗大约150 byte内存,存储1亿个Block,大约需要20GB内存,如果一个文件大小为10K,则1亿个文件大小仅为1TB,但要消耗掉NameNode 20GB内存;
2)存取大量小文件消耗大量的寻道时间,类比拷贝大量小文件与拷贝同等大小的一个大文件,会消耗更多的寻道时间,效率比较低。
HDFS的可靠性策略
HDFS一般的物理拓扑
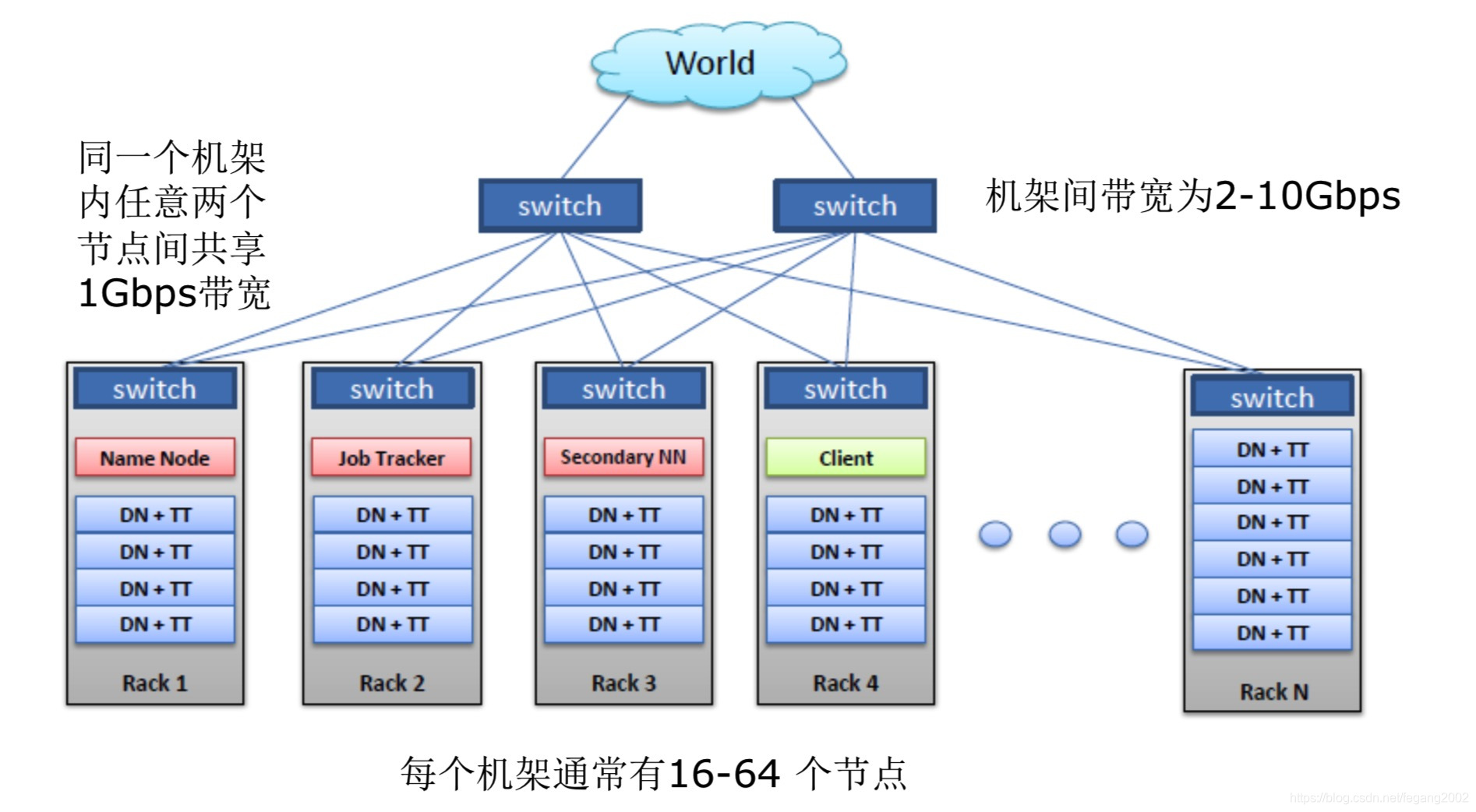
-
容灾策略:
副本1放置在与Client相同的节点上,副本2放置在与副本1不同机架的节点上,副本3放置在和副本2相同机架的节点上,其他副本随意挑选。
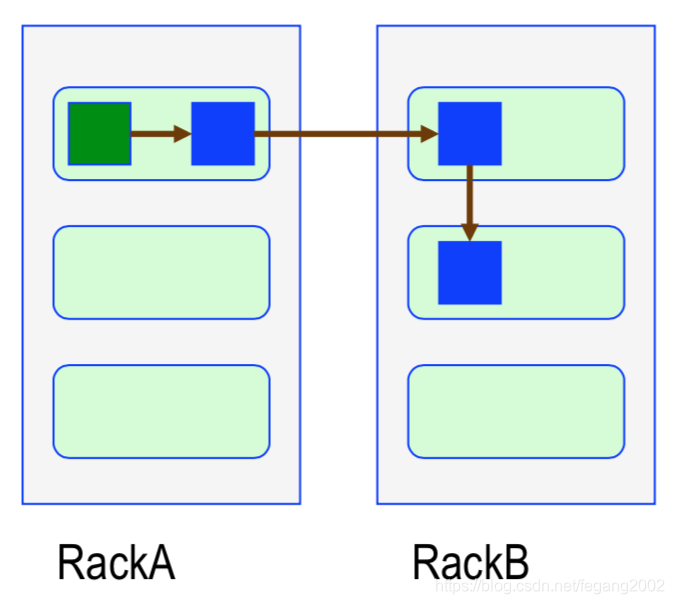
多副本起码放到两个机架上,如果一个机架挂了,还会有至少一个副本。这是一个可靠性和性能之间的折中策略。如果三副本写到三个机架,因为要经过三个交换机,所以性能会降低。 -
文件损坏处理
使用CRC32校验文件完整性,用其他副本取代损坏文件 -
网络或机器失效
Datanode 定期向Namenode发heartbeat,及时发现网络错误或机器失效 -
NameNode失效
FSImage(文件系统镜像)和Edits(操作日志)多份存储,主备NameNode实时切换,Active Namenode挂了,Standby Namenode瞬间可以接管。
HDFS程序设计方法
HDFS访问⽅方式包括:
1)HDFS Shell命令
2)HDFS Java API
3)HDFS REST API
4)HDFS Fuse:实现了Fuse协议
5)HDFS lib hdfs:C/C++访问接口
6)HDFS 其他语言编程API,使用thrift实现,支持C++、Python、php、C#等语言
HDFS Shell命令—⽂文件操作命令
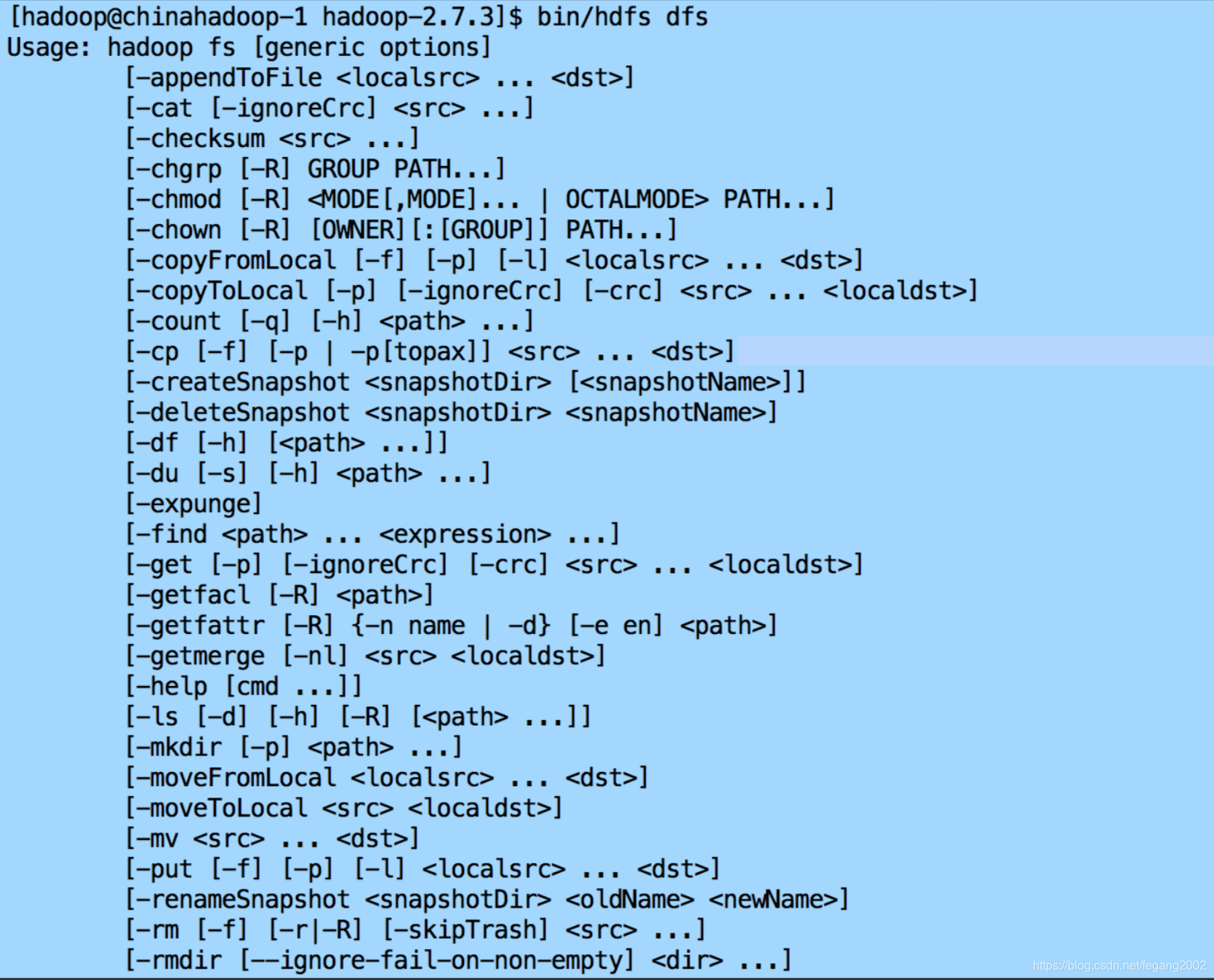 例如:
例如:
将本地文件上传到HDFS上
bin/hdfs dfs -copyFromLocal /local/data /hdfs/data
删除文件/目录
bin/hdfs dfs -rmr /hdfs/data
创建目录
bin/hdfs dfs -mkdir /hdfs/data
HDFS Shell命令—管理命令
HDFS Shell命令—管理脚本
在sbin目录下
start-all.sh
start-dfs.sh
start-yarn.sh
hadoop-deamon(s).sh
单独启动某个服务
hadoop-deamon.sh start namenode
hadoop-deamons.sh start datanode
(可以通过SSH登录到各个节点)
start-all.sh可以启动所有节点的HDFS以及所有的服务(包括Yarn等),不需要登录到各个节点分别启动,但这需要配置免密码登录。
HDFS Java API
- Configuration类:
该类的对象封装了配置信息,这 些配置信息来自core-*.xml; - FileSystem类:
文件系统类,可使用该类的方法对文件/目录进行操作。一般通过FileSystem的静态方法 get获得一个文件系统对象; - FSDataInputStream和FSDataOutputStream类:
HDFS中的输入输出流。分别通过FileSystem的open方法和create方法获得。
以上类均来自java包:org.apache.hadoop.fs
示例:
1)将本地文件拷贝到HDFS上;
Configuration config = new Configuration();
FileSystem hdfs = FileSystem.get(config);
Path srcPath = new Path(srcFile);
Path dstPath = new Path(dstFile);
hdfs.copyFromLocalFile(srcPath, dstPath);
2)创建HDFS文件;
//byte[] buff – 文件内容
Configuration config = new Configuration();
FileSystem hdfs = FileSystem.get(config);
Path path = new Path(fileName);
FSDataOutputStream outputStream = hdfs.create(path); outputStream.write(buff, 0, buff.length);