Fast R-CNN
简述:
RCCN存在以下几个问题:
(1) 需要事先提取多个候选区域对应的图像。这一行为会占用大量的磁盘空间;
(2) 针对传统的CNN来说,输入的map需要时固定尺寸的,而归一化过程中对图片产生的形变会导致图片大小改变,这对CNN的特征提取有致命的坏处;
(3) 每个region proposal都需要进入CNN网络计算。进而会导致过多次的重复的相同的特征提取,这一举动会导致大大的计算浪费。
针对以上问题,Fast R-CNN采用了几个更新来提高训练和测试速度,同时也提高了检测精度。在本文中,简化了基于最先进的卷积神经网络的对象检测器的训练过程。提出了一种单阶段联合学习的目标建议分类和空间定位的训练算法。
模型:
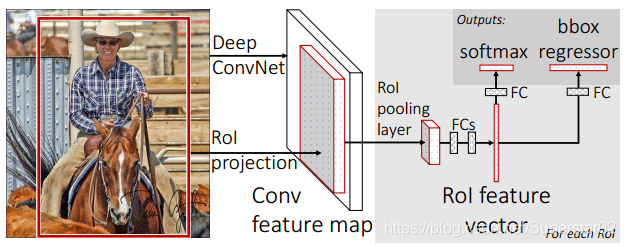
较之前的RCNN相比,有三个方面得到了提升:
1.检测质量(mAP)、速度高于R-CNN, SPPnet
2.训练是单阶段的,使用多任务损失函数,训练可以更新所有网络层
4.特性缓存不需要磁盘存储
模型详细介绍:
该网络首先利用几个卷积(conv)和最大池化层处理整个图像,生成一个conv特征图。然后,针对每个目标提议,一个感兴趣区域(RoI)池化层从特征图中提取一个固定长度的特征向量。每个特征向量送入一个序列的完全连接(fc)层, 把最后的bbox regression也放进了神经网络内部,与区域分类合并成为了一个multi-task模型。
1.特征提取阶段:
在刚开始和RCCN方法一样,利用选择性搜索Selective Search(SS)在图片中获得大约2k个候选框。同时利用卷积网络提取图片特征。在原始图片上执行卷积后,输入图片尺寸不同将会导致得到的feature map(特征图)尺寸也不同,这样就不能直接接到一个全连接层进行分类。作者提出了ROI Pooling的网络层(输入为conv5层的输出和region proposal),可以在任何大小的特征映射上为每个输入ROI区域提取固定的维度特征表示,然后确保每个区域的后续分类可以正常执行。
ROI Pooling层:
ROI是指的在SS完成后得到的“候选框”在卷积特征图上的映射;将每个候选区域均匀分成H×W块,对每块进行max pooling。将特征图上大小不一的候选区域转变为大小统一的数据,送入下一层。如下图:
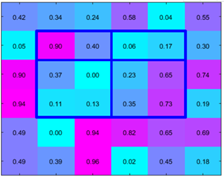
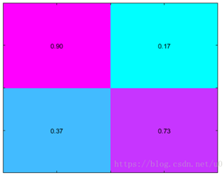
这样虽然输入的图片尺寸不同,得到的feature map(特征图)尺寸也不同,但是可以加入这个神奇的ROI Pooling层,对每个region都提取一个固定维度的特征表示,就可再通过正常的softmax进行类型识别(在论文中使用VGG16,故需提取为7×7)。每个RoI由一个四元组(r, c, h, w)定义,该四元组指定其左上角(r, c)及其高度和宽度(h, w)。
以上操作避免了RCNN存在让图像产生形变,或者图像变得过小的问题,使一些特征产生了损失,继而对之后的特征选择产生巨大影响。
2.特征提取:
Fast R-CNN使用了一种精简的训练过程,该过程有一个微调阶段,联合优化了一个softmax分类器和限制盒回归器。分类损失和回归损失融合,总的损失函数如下:
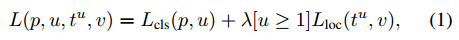

网络在一次微调中将softmax分类器和bbox回归一起优化, 涉及到:多任务损失(multi-task loss)、小批量取样(mini-batch sampling)、RoI pooling层的反向传播(back-propagation through RoI pooling layers)、SGD超参数(SGD hyperparameters)。