基本原理
Fast Rcnn主要步骤为
- 利用SR算法生成候选区域
- 利用VGG16网络进行特征提取
- 利用第一步生成的候选区域在特征图中得到对应的特征矩阵
- 利用ROI pooling将特征矩阵缩放到相同大小并平展得到预测结果
相对于RCNN的优化
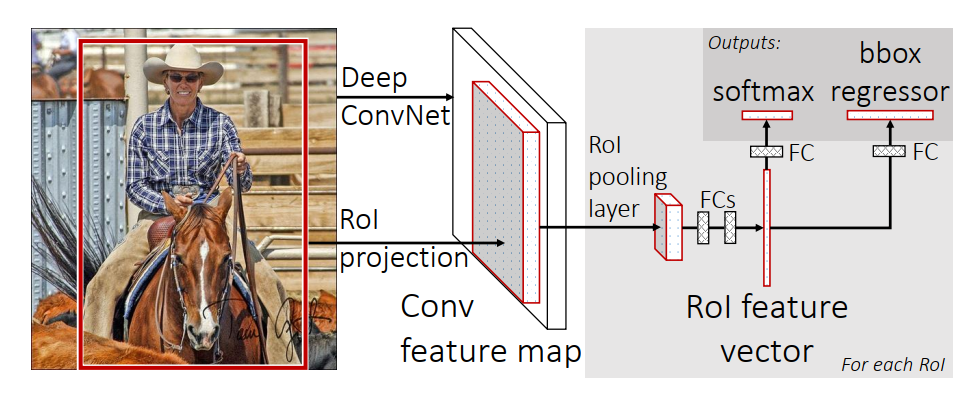
主要有三个改进
- 不再将每一个候选区域依次放入CNN网络中进行特征提取等一系列操作,而是采取将整张图输入网络,得到特征图。然后再利用原图中的候选区域在特征图中对应的区域进行展平,得到预测结果。
- 不再需要对图片进行强制缩放,而是采取利用ROI Pooling缩放到相同大小。
- 不再使用SVM进行分类,而是使用softmax进行代替。
优化意义
- 第一个优化点
一张图片只需要通过卷积网络一次,减少了大量的运算,但是对于特征图的每一个候选区域,全连接层需要对每一个候选区域进行一次运算处理,而算法作者使用SVD进行加快处理。 - 第二个优点
roi pooling可以提高训练处理速度,更好解决缩放问题。 - 第三个优化点
- 将分类的损失纳入网络训练整个过程中,相对于RCNN减少了对磁盘空间的占用。
- 全连接层有两个分支,一个用于softmax分类,另一个用于位置回归。
- 损失函数为
L ( p , u , t u , v ) = L c l s ( p , u ) + λ [ u ⩾ 1 ] L l o c ( t u , v ) L(p,u,t^u,v)=L_{cls}(p,u)+\lambda [u\geqslant 1]L_{loc}(t^u,v) L(p,u,tu,v)=Lcls(p,u)+λ[u⩾1]Lloc(tu,v)
其中 L c l s ( p , u ) = − l o g ( p , u ) L_{cls}(p,u)=-log{(p,u)} Lcls(p,u)=−log(p,u)是分类损失,p是预测的概率,u是真实标签。
λ [ u ≥ 1 ] L l o c ( t u , v ) \lambda[u \ge 1]L_{loc}(t^u,v) λ[u≥1]Lloc(tu,v)是位置损失,v是预测得到的偏移量与缩放系数, t u t^u tu是实际的候选框与真实框的偏移量与缩放系数,与RCNN一致。
前面的系数 λ [ u ≥ 1 ] \lambda[u \ge 1] λ[u≥1]是用于判断候选区域为背景还是物体。如果是背景,则不计算;如果是物体,则计算回归。
其中
L l o c ( t u , v ) = ∑ i ϵ { x , y , w , h } s m o o t h L 1 ( t i u − v i ) L_{loc}(t^u,v)=\sum_{i\epsilon \{x,y,w,h\}}smooth_{L_1}(t_i^u-v_i) Lloc(tu,v)=∑iϵ{ x,y,w,h}smoothL1(tiu−vi)
s m o o t h L 1 ( x ) = { 0.5 x 2 i f ∣ x ∣ < 1 ∣ x ∣ − 0.5 o t h e r w i s e smooth_{L_1}(x)=\left\{\begin{matrix}0.5x^2\ \ \ \ \ \ if\ |x|< 1\\|x|-0.5\ \ otherwise\end{matrix}\right. smoothL1(x)={ 0.5x2 if ∣x∣<1∣x∣−0.5 otherwise