一、R-CNN算法流程
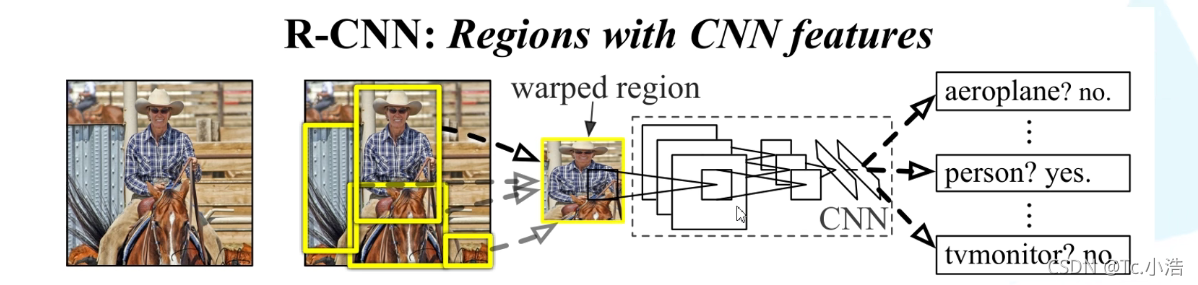
- 一张图像生成1K-2K个候选区域
- 对每个候选区域使用深度网络提取特征
- 特征送入每一个的SVM分类器,判别是否属于该类
- 使用回归器精细修正候选框位置
边界框回归器
输出对应N+1个类别的候选边界框回归参数( d x d_x dx, d y d_y dy, d w d_w dw, d h d_h dh),共(N+1)x4个节点

对非极大值抑制处理后剩余的建议框进一步筛选。接着分别用20个回归器对上述20个类别中剩余的建议框进行回归操作,最终得到每个类别的修正后得分最高的bounding box.
二、利用候选区域与 CNN 结合做目标定位
借鉴了滑动窗口思想,R-CNN 采用对区域进行识别的方案。
具体是:
1.给定一张输入图片,从图片中提取 2000 个类别独立的候选区域。
2.对于每个区域利用事先训练好的AlexNet CNN 抽取一个固定长度的特征向量。
3.再对每个区域利用 SVM 进行目标分类。
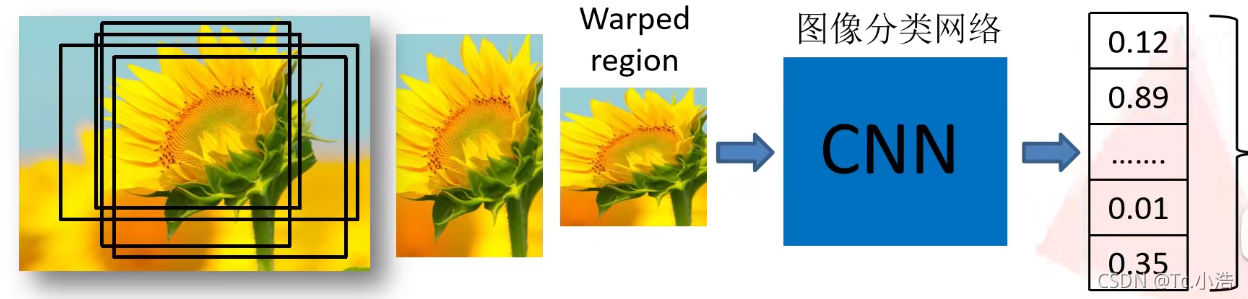
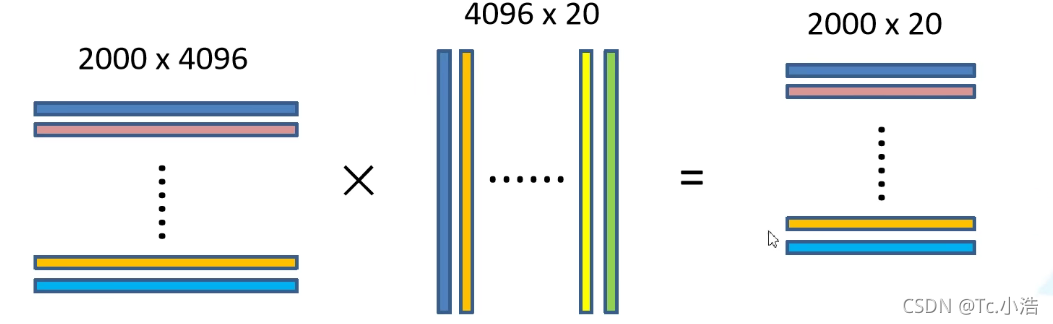
将2000x4096的特征矩阵与20个SVM组成的权值矩阵4096x20相乘,获取2000x20的概率矩阵,每一行代表一个建议框归于每个目标类别的概率。分别对上述2000x20维矩阵中每一列即每一类进行非极大值抑制剔除重叠建议框(IOU),得到该列即该类中得分最高的一些建议框。
IOU参考:
https://blog.csdn.net/weixin_48167570/article/details/120697408

R-CNN存在的问题
- 测试速度慢:
测试一张图片约53s(CPU)。用Selective Search算法提取候选框用时约2秒,一张图像内候选框之间存在大量重叠,提取特征操作冗余。 - 训练速度慢:
过程及其繁琐 - 训练所需空间大:
对于SVM和bbox回归训练,需要从每个图像中的每个目标候选框提取特征,并写入磁盘。对于非常深的网络,如VGG16,从VOCO7训练集上的5k图像上提取的特征需要数百GB的存储空间。
Fast R-CNN算法流程
-
一张图片生成1K–2K个候选区域(使用Selective Search方法)
Selective search算法(以下简称ss算法):首先通过以及简单的聚类生成区域集合;然后根据定义的相似度不断合并相邻区域构成新的候选框。本质上是一种基于在原始聚类后的区域集合上,依照邻域的相似度,从小到大的进行滑动窗口。具体算法实现步骤如下:
step1:计算区域集R里每个相邻区域的相似度S={s1,s2,…}
step2:找出相似度最高的两个区域,将其合并为新集,添加进R
step3:从S中移除所有与step2中有关的子集
step4:计算新集与所有子集的相似度
step5:跳至step2,直至S为空 -
将图像输入网络得到相应的特征图,将ss算法生成的候选框投影到特征图上获得相应的特征矩阵
-
将每一个特征矩阵通过ROI pooling层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果
