之前有看过这几篇论文,但都不是了解特别清楚。这次索性做个纵向对比,重新把这几篇论文翻出来看,也当做一个阅读笔记。
目前的目标检测算法主要分为两类:一类是以RCNN领头的two stage的检测算法。另一类是以Overfeat领头的one stage算法。其主要的综述可以看
https://zhuanlan.zhihu.com/p/33277354
各项指标可以看以下链接:
https://handong1587.github.io/deep_learning/2015/10/09/object-detection.html
RCNN
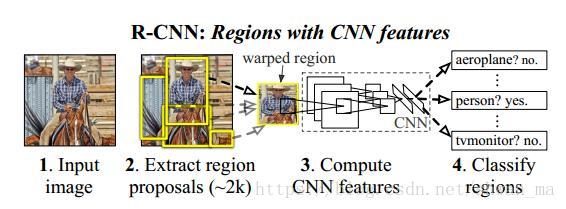
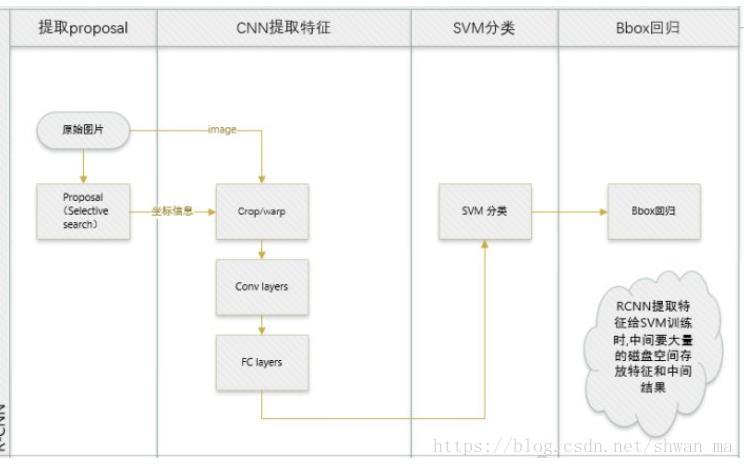
可以由上述的overview看到,RCNN主要分为三部分:1)提取proposals 2)CNN提取特征 3)分类。
1)提取特征: RCNN还是采取了传统的proposal算法:Selective Search 算法对 目标region进行提取。事实上,由于我们知道 Region proposals 提取下来后 尺寸大小不一,然后在特征提取时,采用了CNN进行提取特征,此处RCNN采取了Wrapped, 即无视原来的大小和长宽比,强行将proposal的大小拉伸至227 x 227。
2)提取特征: 对每一个proposal进行CNN提取特征。(其实我们可以看到,这种操作为RCNN带来了巨大的计算量)
3)分类: RCNN中采用了SVM对CNN提取下来的特征进行分类。特征矩阵为 2000x4096, 则SVM的权重矩阵为4096xN,其中N为类别数。
Note:
1. CNN后面接一个Softmax就能分类, 为什么RCNN把CNN提取特征和分类给分开做?
由于训练数据不一样:
CNN提取特征的时候,设置IOU>0.5的作为正样本,其他作为负样本。
在一个mini-batch中,作者32个正样本,96个负样本进行输入。
而SVM中:作者将groud truth作为正样本,IOU<0.3的为负样本,其他忽略。
2.由于把CNN提取特征和SVM分类两个任务分开,需要在硬盘上存入大量样本数据,容易造成 disk-hungry.
3. 上面也提到,RCNN对每一个proposal都进行了CNN操作,存在着大量的冗余计算。
RCNN中涉及到的bounding-box regression
由于Selective Search提取的box不会太准,RCNN在之后面又加了一个 linear regression。
box regression的输入形式: P i = (Px i; Py i; Pw i ; Ph i) 分别表示 box中心点的x,y坐标及box的宽和高、每个ground-truth bounding box G 同样的定义设置。G = (Gx; Gy; Gw; Gh)
作者定义proposal P到ground-truth G之间的变换:
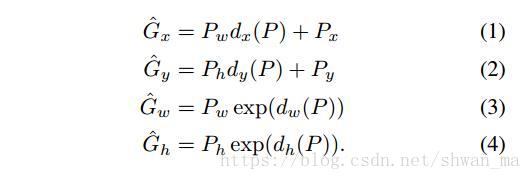
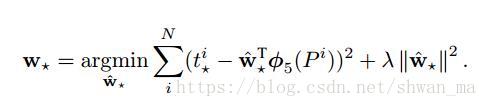
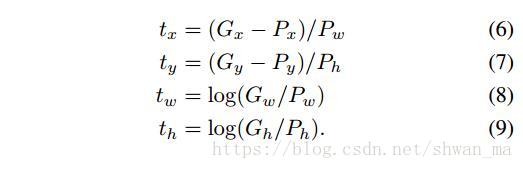
其中在岭回归中的 lamda 系数,作者将其设置为1000。
RCNN的整个计算流程

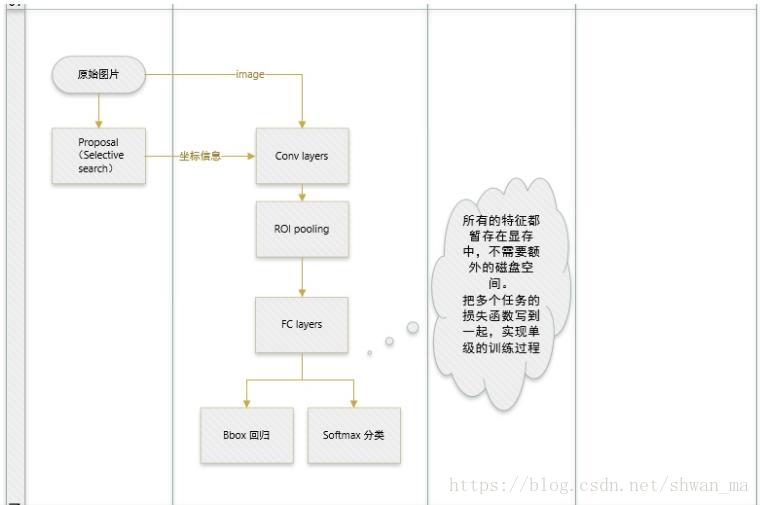
Fast-RCNN
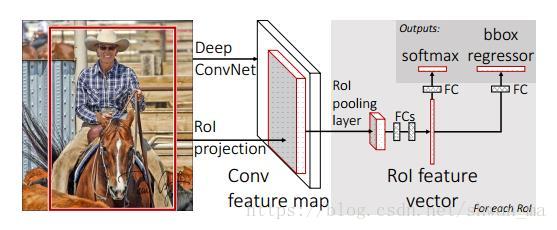
从上图我们可以看到Fast-RCNN跟RCNN的流程里面有几个明显区别。
1)Fast-RCNN 不再像RCNN一样,对每个ROI分别去提取特征,而是直接在输入图像上进行一次卷积。从而共享了大量的卷积计算量。
2)Fast-RCNN 将提取特征和分类的部分进行了融合,因此不需要像之前一样把feature进行存储后投入到SVM训练,从而避免了 disk storage。
那么想对上述两点进行了改进会带来以下几个问题:
- RCNN是对原始图像进行提取proposal,然后在每一个proposal上分别去提取特征。而Fast-RCNN仅仅是直接在原始图像上进行了一次卷积后,如何把原始图片中的ROI映射到feature map中,这将是一个难点。
- 每个proposal对应的feature map 如何去保持等长输出到Fully connected network上。在RCNN中,是可以直接对原始图像上提取的proposal进行wrapped进行投入网络中。而在Fast-RCNN中,feature map 是无法进行扭曲变形后投入到后面的FC中的。因此作者提出了ROI Pooling. 来保证每个输出的特征是等长的,以为了更方便的处理。
1.原始图像中的ROI映射到feature map 上的方法
截取自Hekaiming IICV 2015的slide

关于详细的ROI映射到feature map上可以参考:https://zhuanlan.zhihu.com/p/24780433
2.ROI pooling方法
由于Fast-RCNN无法对feature map 进行warped 投入到CNN中,因此采用了ROI pooling算法,输出等长的feature。
此处假设某个ROI区域坐标为(x1,y1,x2,y2),那么输入size为(y2-y1)(x2-x1)。如果pooling的输出size为 pooledheight pooledwidth,
那么每个网格的size为((y2-y1)/pooledheight * (x2-x1/pooledwifdth))
此处引用一个博客上的例子对ROI pooling进行更好的讲解:
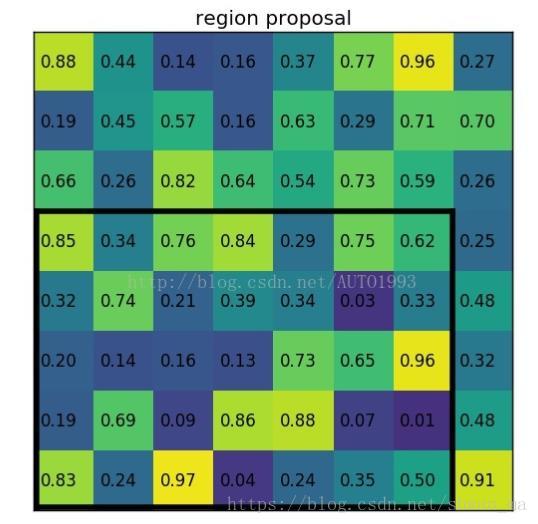
黑框表示 ROI.(7x5) 那么假设输出的大小为2x2。那么对其进行pooling时,分成7/2 * 5/2。因此分成4个区域为 3x2,4x2, 3x3,4x3。 如下:
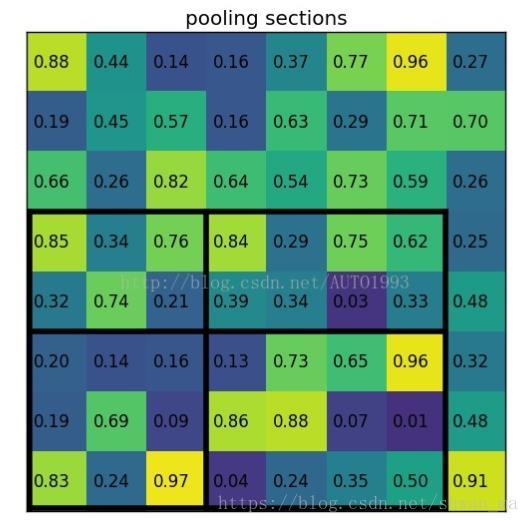
最后对每个section做max pooling为:
3. 关于损失函数
FastRCNN采取了Multi-task loss,结合了分类损失和bounding-box regression。
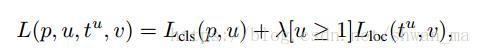
其中第一项:Lcls = -log(pu) 其中pu为真实类别u的概率。
其中第二项:bounding-box regression,采用了 与RCNN不同的损失。Fast-rcnn采用了smooth L1损失函数:
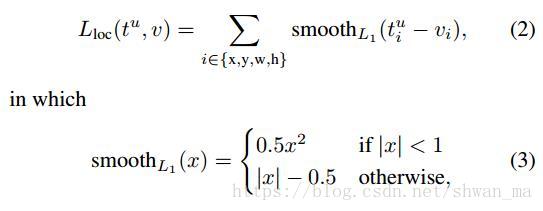
这里稍微解释一下,为什么要采用 smooth L1 loss (网易2018春招的笔试题之一)
robust L1 loss that is less sensitive to outliers than the L2 loss used in R-CNN and SPPnet. When the regression targets are unbounded, training with L2 loss can require careful tuning of learning rates in order to prevent exploding gradients. Eq. 3 eliminates this sensitivity
因为Smooth L1 loss 对 异常值不敏感,当出现一个异常值,导致回归偏差很大时,smooth L1 loss能够有效的避免梯度爆炸。
Fast-RCNN的整个计算流程
Faster-RCNN
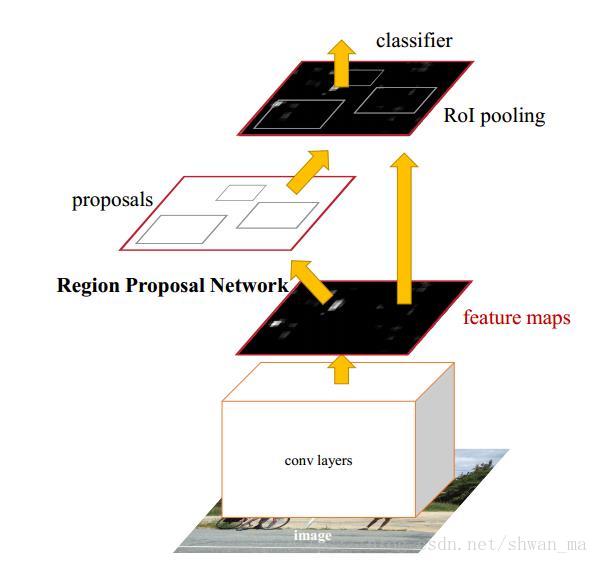
从上文我们知道:RCNN采用了3个部分:Selective Search + CNN + SVM
Fast-RCNN 将提取特征和分类两者合在了一起,但是proposal仍然还是由SS算法。
这就导致了一个尴尬的处地,提取proposal的时间比后面分类+回归的总时间都长。Faster-RCNN则着重于这点,提出了RPN网络,并引入anchor框。
为了更好的理解RPN网络,这里附上Caffe的RPN实现:
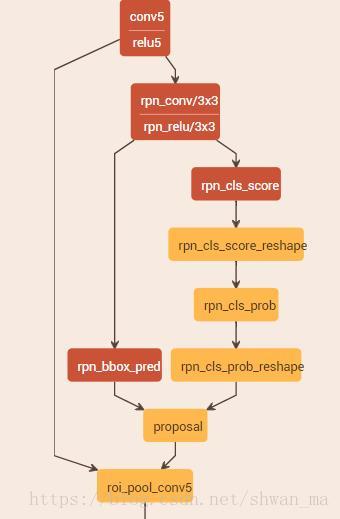
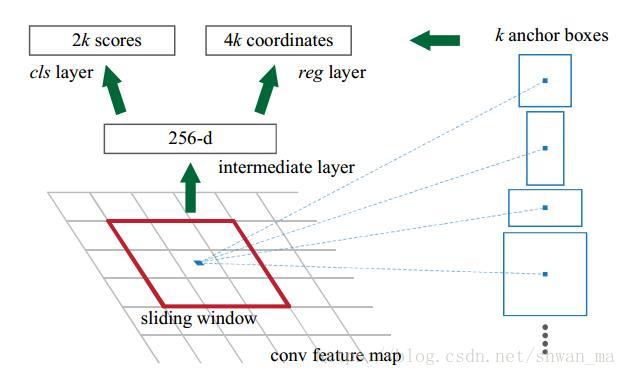
由Con5/relu5 输出了 feature map, 在对feature map上作者采用了3x3的滑动框。对于滑动框在滑动的中心,对应了9个anchor,3x3的形式:3种大小(128^2, 256^2, 512^2),3种比例:(1:1, 1:2, 2:1)。之所以选择这么9种anchor框,由于后面的loss会对box regression。所以前面的anchor可以设置的稍微粗糙些。注意这里的输入大小,作者对shorter side re-scale到600pixle。
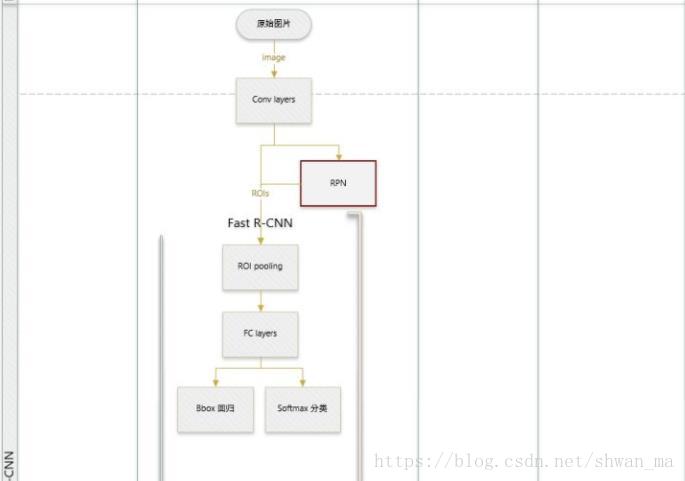
Faster-RCNN的整个计算流程
参考文献: