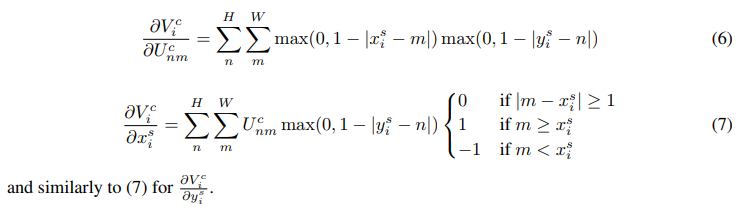Spatial Transformer Networks
简介
本文提出了能够学习feature仿射变换的一种结构,并且该结构不需要给其他额外的监督信息,网络自己就能学习到对预测结果有用的仿射变换。因为CNN的平移不变性等空间特征一定程度上被pooling等操作破坏了,所以,想要网络能够应对平移的object或者其他仿射变换后的object有更好的表示,就需要设计一种结构来学习这种变换,使得作用了这种变换后的feature能够能好的表示任务。
网络结构

上图中U表示输入feature map,通过spatial transformer 分支学习到transform,然后通过差值或其他sampler映射到输出feature,这样输出的feature会有一种更加健壮的表示。
spatial transform的结构由三个部分组成,下面会详细介绍。
仿射变换
仿射变换分为平移、缩放、翻转、旋转和裁剪这几种变换,其中二维的变换可以用矩阵来表示:
\[ \left(\begin{matrix} x' \\ y' \end{matrix}\right) = \left[\begin{matrix} \theta_1 & \theta_2 & \theta_3 \\ \theta_4 & \theta_5 & \theta_6 \\ \end{matrix}\right] \left(\begin{matrix} x \\ y\\ 1 \end{matrix}\right) \]
其中theta对应取不同的值会对应不同的变换。所以网络同学学习到这种变换,帮助feature得到一种更加有效的表示。
Localisation Network
该部分对应与上图中的localisation net部分,目的是为了学习到上面公式中的theta参数,也就是说,这一部分的结构可以直接全连接6个theta或者使用conv结构,只要能映射到6个theta就可以了。这一部分比较简单。
Parameterised Sampling Grid
这一部分对应于上图的Grid Generator部分,这一部分的作用是建立输入图像位置到输出图像位置的映射,也就是对应于我们上面提到的仿射变换,我们在这一结构下可以通过上面学习到的参数theta来通过矩阵形式对输入进行放放射变换,注意变换的时候每个channel的变换应该是一致的。公式表示为:

我们可以通过限定theta的取值来限定网络只学习某种变换,也就是只学习一部分theta参数。
Differentiable Image Sampling
上面放射变换只是定义了变换前到变换后的位置映射,这个映射其实并不完整,这就意味着有些点是没有值的,如果要给值,就要使用插值的方法了。论文中提到了最邻近插值和双线性插值两种插值方法。
对于最邻近插值给出了这样的定义:

这样对于输出feature的第i个值,其对应的输入feature的位置取决于m和n,由krnoecker delta函数定义知,当且仅当自变量为0时输出为1.所以上式只有在m取得x方向上距离对应点最近的整数点以及n取得y方向上距离最近的整数点时有值,其值就为对应两个方向都最近的点的值。
对于双线性插值给出了这样的定义:
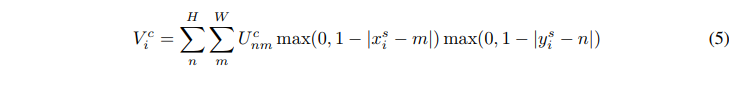
由上式可以知道,只有当m和n取值为对应点xy方向上距离为1以内的整数时才有值,而距离对应点最近的整数点是有四个的,比如(0.5,0.5)距离其最近的四个点分别为(0,0),(0,1),(1,1),(1,0),后面两个取值就成了距离权重,前面U取值为四个点之一的整数点的值,所以这个式子可以解释为以距离作为权重,取最近的四个点的值的加权求和。
反向传播
定义了上面的对应函数,作者证明了输出到输入是可以进行反向传播的,以双线性插值为例: