Spatial Transformer Networks(STN)
15年NIPS
这篇文章通过注意力机制,将原始图片中的空间信息变换到另一个空间中并保留了关键信息。
思想非常巧妙,因为卷积神经网络中的池化层(pooling layer)直接用一些max pooling 或者average pooling 的方法,将图片信息压缩,减少运算量提升准确率。
作者认为之前pooling的方法太过于暴力,直接将信息合并会导致关键信息无法识别出来,所以提出了一个叫空间转换器(spatial transformer)的模块,将图片中的的空间域信息做对应的空间变换,从而能将关键的信息提取出来。
Unlike pooling layers, where the receptive fields are fixed and local, the spatial transformer module is a dynamic mechanism that can actively spatially transform an image (or a feature map) by producing an appropriate transformation for each input sample.

空间转换器模型直观的实验图:
(a)列是原始的图片信息,其中第一个手写数字7没有做任何变换,第二个手写数字5,做了一定的旋转变化,而第三个手写数字6,加上了一些噪声信号;这些变化都是随机的
(b)列中的彩色边框是学习到的spatial transformer的框盒(bounding box),每一个框盒其实就是对应图片学习出来的一个spatial transformer;
©列中是通过spatial transformer转换之后的特征图,可以看出7的关键区域被选择出来,5被旋转成为了正向的图片,6的噪声信息没有被识别进入。
(d)列最终可以通过这些转换后的特征图来预测出中手写数字的数值。
spatial transformer其实就是注意力机制的实现,因为训练出的spatial transformer能够找出图片信息中需要被关注的区域,同时这个transformer又能够具有旋转、缩放变换的功能,这样图片局部的重要信息能够通过变换而被框盒提取出来。
模型结构:
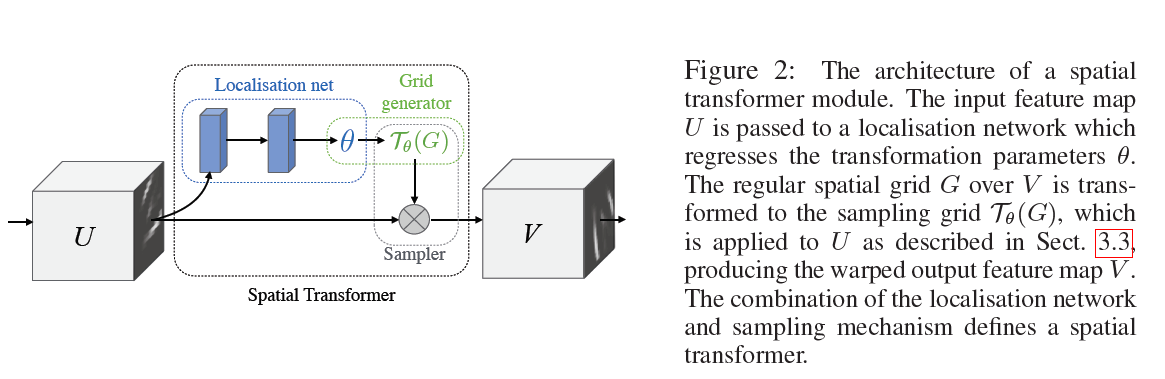
这是空间变换网络(spatialtransformer network)中最重要的空间变换模块,这个模块可以作为新的层直接加入到原有的网络结构,比如ResNet中。来仔细研究这个模型的输入:
U ∈ R H × W × C U \in \mathbb{R}^{H \times W \times C} U∈RH×W×C
神经网络训练中使用的数据类型都是张量(tensor), H H H是上一层tensor的高度(height), W W W是上一层tensor的宽度(width),而 C C C代表tensor的通道(channel),比如图片基本的三通道(RGB),或者是经过卷积层(convolutional layer)之后,不同卷积核(kernel)都会产生不同的通道信息。之后这个输入进入两条路线,一条路线是信息进入定位网络(localisation net),另一条路线是原始信号直接进入采样层(sampler)。
STN主要分为下述三个步骤
1、Localisation net:
自己定义的网络,可以是各种结构,它输入 U U U,输出变化参数 θ \theta θ,这个参数用来映射 U U U和 V V V的坐标关系
其中这个定位网络会学习到根据输入输出一组参数 θ \theta θ,而这组参数就能够作为网格生成器(grid generator) T θ \mathcal{T}_{\theta} Tθ的参数
The localisation network takes the input feature map U ∈ R H × W × C U \in \mathbb{R}^{H \times W \times C} U∈RH×W×C with width W W W, height H H H and
C C C channels and outputs θ \theta θ, the parameters of the transformation T θ \mathcal{T}_{\theta} Tθ to be applied to the feature map:
θ = f loc ( U ) \theta=f_{\operatorname{loc}}(U) θ=floc(U). The size of θ \theta θ can vary depending on the transformation type that is parameterised,
e.g. for an affine transformation θ \theta θ is 6-dimensional as in (1).
The localisation network function f loc ( U ) f_{\operatorname{loc}}(U) floc(U) can take any form, such as a fully-connected network or
a convolutional network, but should include a final regression layer to produce the transformation
parameters θ \theta θ.
网络训练的时候,对于localization network这一部分的初始化,将weight全部设置为0,bias设置为numpy.array([[1.0,0,0],[0,1.0,0]]),也就是设置为一个等变变换;随着训练的进行,不断调整weight和bias,学习到所需的变换矩阵。
2、Grid generator:
这一步进行几何变换,不过是对每一个输出坐标进行几何变换(变换由参数 θ \theta θ决定),得到所需要的输入坐标;
在 θ \theta θ下生成一个采样信号,这个采样信号其实是对 G G G(regular grid)的一个变换矩阵 T θ ( G i ) \mathcal{T}_{\theta}\left(G_{i}\right) Tθ(Gi),这个采样矩阵与原始图片进行矩阵乘法之后,可以得到变换之后的就可以得到矩阵 V V V( V ∈ R H ′ × W ′ × C V \in \mathbb{R}^{H^{\prime} \times W^{\prime} \times C} V∈RH′×W′×C) 变换之后的矩阵大小是可以通过调节变换矩阵来形成缩放的。
计算的时候是根据 V V V中的坐标点和变化参数 θ \theta θ,计算出所需要的采样的 U U U中的坐标点。这里是因为 V V V的大小是自己先定义好的,当然可以得到 V V V的所有坐标点,而填充 V V V中每个坐标点的像素值的时候,要从 U U U中去取,所以根据 V V V中每个坐标点和变化参数 θ \theta θ进行运算,得到一个坐标。在sampler中就是根据这个坐标去 U U U中找到像素值,这样子来填充 V V V
以2D的仿射变换例,
( x i s y i s ) = T θ ( G i ) = A θ ( x i t y i t 1 ) = [ θ 11 θ 12 θ 13 θ 21 θ 22 θ 23 ] ( x i t y i t 1 ) (1) \left(\begin{array}{c}x_{i}^{s} \\ y_{i}^{s}\end{array}\right)=\mathcal{T}_{\theta}\left(G_{i}\right)=\mathrm{A}_{\theta}\left(\begin{array}{c}x_{i}^{t} \\ y_{i}^{t} \\ 1\end{array}\right)=\left[\begin{array}{lll}\theta_{11} & \theta_{12} & \theta_{13} \\ \theta_{21} & \theta_{22} & \theta_{23}\end{array}\right]\left(\begin{array}{c}x_{i}^{t} \\ y_{i}^{t} \\ 1\end{array}\right)\tag{1} (xisyis)=Tθ(Gi)=Aθ⎝⎛xityit1⎠⎞=[θ11θ21θ12θ22θ13θ23]⎝⎛xityit1⎠⎞(1)
( x i s y i s ) \left(\begin{array}{c}x_{i}^{s} \\ y_{i}^{s}\end{array}\right) (xisyis)为输入的网格坐标( U U U中的坐标), ( x i t y i t ) \left(\begin{array}{c}x_{i}^{t} \\ y_{i}^{t}\end{array}\right) (xityit)为变换后的网格坐标( V V V中的坐标);需要通过根据变换后的网格坐标,也就是 V V V中的网格坐标去计算变换前输入坐标的位置(也就是 U U U中的位置)。
这是图像领域常用的方案,是为了避免输出出现空洞和重叠。
 ]
]
通过这张转换图片,可以看出空间转换器中产生的采样矩阵是能够将原图中关键的信号提取出来,(a)中的采样矩阵是单位矩阵,不做任何变换,(b)中的矩阵是可以产生缩放旋转变换的采样矩阵。
3、Sampler:
要做的是填充 V V V,根据Grid generator得到的一系列坐标和原图 U U U(因为像素值要从 U U U中取)来填充,因为计算出来的坐标可能为小数,实际在feature map上是不存在的;所以需要通过采样(插值)的方式计算其对应的值;文章中使用双线性插值,保证了可微,可以用反向传播进行训练。
这个模块加进去最大的好处就是能够对上一层信号的关键信息进行识别(attention),并且该信息矩阵是一个可以微分的矩阵,因为每一个目标(target)点的信息其实是所有源(source)点信息的一个组合,这个组合可以是一个线性组合,复杂的变换信息也可以用**核函数(kernel)**来表示:
V i c = ∑ n H ∑ m W U n m c k ( x i s − m ; Φ x ) k ( y i s − n ; Φ y ) ∀ i ∈ [ 1 … H ′ W ′ ] ∀ c ∈ [ 1 … C ] V_{i}^{c}=\sum_{n}^{H} \sum_{m}^{W} U_{n m}^{c} k\left(x_{i}^{s}-m ; \Phi_{x}\right) k\left(y_{i}^{s}-n ; \Phi_{y}\right) \quad \forall i \in\left[1 \ldots H^{\prime} W^{\prime}\right] \forall c \in[1 \ldots C] Vic=∑nH∑mWUnmck(xis−m;Φx)k(yis−n;Φy)∀i∈[1…H′W′]∀c∈[1…C]
Φ x \Phi_{x} Φx 和 Φ y \Phi_{y} Φy 核函数 k ( ⋅ ) k(\cdot) k(⋅)的参数定义插值方式
U n m c U^c_{nm} Unmc输入图像的 c c c通道 n m nm nm位置的像素值
V i c V^c_{i} Vic输入图像的 c c c通道 i i i位置 ( x i t , y i t ) (x^t_i,y^t_i) (xit,yit)的像素值
个人理解
每个通道是通过统一方式做变换的具有一定的相关性,相当于说每一个 V i c V_i^c Vic都需要,把刚才计算出来的所需要的采样点的坐标值进行核函数 k ( x i s − m ; Φ x ) k ( y i s − n ; Φ y ) k\left(x_{i}^{s}-m ; \Phi_{x}\right) k\left(y_{i}^{s}-n ; \Phi_{y}\right) k(xis−m;Φx)k(yis−n;Φy)映射后,做成mask,坐标再乘进去之后求和,达到的效果按照如下的方式叙述:
每一个 V i c V_i^c Vic中的坐标,已经通过 θ \theta θ算出来了一个变换映射点坐标 ( x i s , y i s ) (x_i^s,y_i^s) (xis,yis),这个坐标会影响后面核函数的输出,在计算 V i c V_i^c Vic的值的时候核函数的输出会因为 m n mn mn的不同,而产生不同的值因为此时 ( x i s , y i s ) (x_i^s,y_i^s) (xis,yis)是固定的,相当于说 V i c V_i^c Vic 的值可以因为这个映射源点坐标的不同,产生对 U U U中不同像素点位置的值 U n m c U_{nm}^c Unmc有不一样的增益或者衰减(因为有核函数的参与所以变成了连续的差值),这就是不同注意力的产生。
总结
理论上来说,这样的模块是可以加在任意层的,因为模块可以同时对通道信息和矩阵信息同时处理。
但是由于文章提出对所有的通道信息进行统一处理变换,我认为这种模块其实更适用于原始图片输入层之后的变化,因为卷积层之后,每一个卷积核(filter)产生的通道信息,所含有的信息量以及重要程度其实是不一样的,都用同样的transformer其实可解释性并不强。
在CNN中插入ST模块即可构成STN, ST模块可以插入在任意位置,任意数量。ST模块可以让网络在训练过程中如何主动地对feature map进行变换以帮助减小网络损失。STN网络具体对输入feature map进行怎样的变换就是由localization network中学习到的这些网络权重来决定的。
参考文献
计算机视觉中的注意力机制(Visual Attention)
Spatial Transformer Networks 论文详解及代码_強云的博客-CSDN博客
Spatial Transformer Networks 论文解读_JerryZhang__的博客-CSDN博客
论文笔记:空间变换网络(Spatial Transformer Networks) - PilgrimHui - 博客园