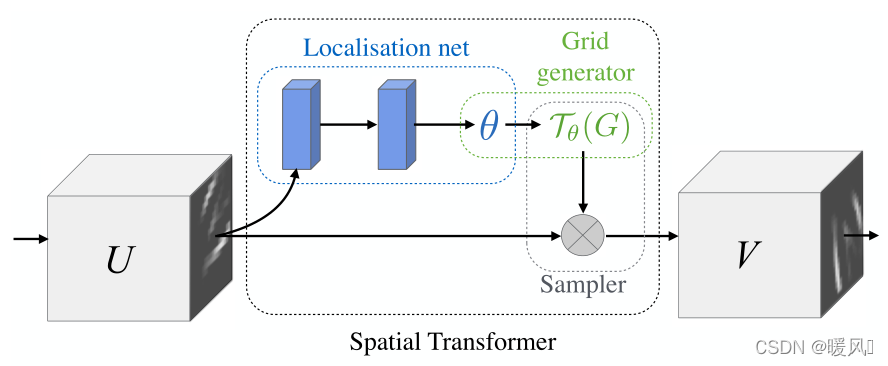
文章是Google DeepMind在2015年提出的Spatial Transformer Networks(STN),该模型能够让卷积网络学会数据的形状变换,能够对经过平移、旋转、缩放及裁剪等操作的图片得到与未经变换前相同的检测结果。STN作为一种独立的模块可以在网络的任意位置插入使得网络具有空间不变性。
文章链接:Spatial Transformer Networks
参考目录:
仿射变换和双线性插值:Spatial Transformer Networks
pytorch源码:SPATIAL TRANSFORMER NETWORKS TUTORIAL
完整且详细的STN讲解:
论文笔记之STN
Spatial Transformer Networks
理解Spatial Transformer Networks
论文笔记:空间变换网络
Spatial Transformer Networks
Abstract
卷积神经网络缺乏对输入数据保持空间不变的能力,导致模型性能下降。虽然CNN中引入池化层有助于满足这一特性,但这种空间不变性仅能在池化矩阵的范围内才具有平移不变性或者在卷积的深层层次上实现。在这篇文章中,作者提出了一种新的可学习模块,STN。这个可微模块可以插入现有的卷积结构中,使神经网络能够根据特征图像本身,主动地对特征图像进行空间变换,而不需要任何额外的训练监督或优化过程。
1 Introduction
- STN作为一种独立的模块可以在不同网络结构的
任意节点插入任意个数。 - STN具有
运算速度快的特点,它几乎没有增加原网络的运算负担,甚至在一些attentive model中实现了一定程度上的加速。 同一个网络层中也可以插入多个STN来对于多个物体进行不同的空间变换。往往同一个STN模块仅用于检测单个物体并会对其他信息进行剔除。同一个网络层中的STN模块个数在一定程度上影响了网络可以处理的最大物体数量。
2 Method
网络总体结构可以分为三步走:学习一个变换矩阵 - 找到位置映射关系 - 计算输出像素值
- 学习变换矩阵。输入特征图像U,经过FCN或者CNN输出一个变换矩阵θ 。
- 根据变换矩阵θ ,找到映射位置关系,注意这里是位置的对应关系,与像素值无关。就是说我们遍历输出图像的所有位置,要找到每个位置的值是由输入图像的哪个位置的值映射过来的,找出输入图像中的这个位置。找出所有的位置对应关系。output feature position -> input feature position
- 利用插值算法根据位置映射计算像素值。第二步找到了输出图像在输入图像中的位置对应关系,但是可能有小数,所以使用插值算法算出这个插值点的像素值,赋给输出图像。position->score
总结一下:学变换,往前推找到输入图像中的位置,得到像素值再传回输出图像。
2.1 Localisation Network
- Localisation网络是将输入图像(feature map) U ∈ R H × W × C U∈R^{H×W×C} U∈RH×W×C 经过若干卷积或全连接操作后接一个回归层输出一个变换矩阵 θ θ θ 。
- θ的尺寸可以根据参数的类型而变化。
变换矩阵θ可以表征任何现存的一种变换,比如仿射变换 θ ∈ R 2 × 3 θ∈R^{2×3} θ∈R2×3、投影变换 θ ∈ R 3 × 3 θ∈R^{3×3} θ∈R3×3等,不同的变换会产生不同size的θ。
PS:仿射变换可以简单看作线性变换加平移。
2.2 Parameterised Sampling Grid
根据得到的变换矩阵θ,就可以得知输出是如何由输入变换来的。
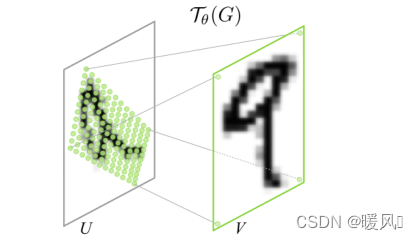
遍历输出图像的每个位置,根据变换矩阵找到变换前的输入图像位置,保存该位置。所有这一层的输出是位置坐标。
设输入feature map U每个像素位置的坐标为 ( x i s , y i s ) (x^s_i,y^s_i) (xis,yis),经过ST变换后输出feature map V每个像素位置的坐标为 ( x i t , y i t ) (x^t_i,y^t_i) (xit,yit)。
下图为输入和输出feature map的仿射变换关系。
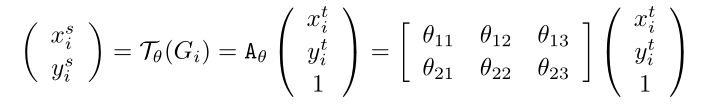
得到的坐标值往往都是非整数,所以需要插值算法来获取对应的像素值了。
2.3 Differentiable Image Sampling
第三步重采样也叫差分采样。获取U中像素值来作为V中对应位置的像素值。如果获得的U中的坐标点 ( x i s , y i s ) (x^s_i,y^s_i) (xis,yis)是整数,那就可以直接将 ( x i s , y i s ) (x^s_i,y^s_i) (xis,yis)处像素值作为输出V中 ( x i t , y i t ) (x^t_i,y^t_i) (xit,yit)的像素值。但往往获得的 ( x i s , y i s ) (x^s_i,y^s_i) (xis,yis)是小数的形式,因为不能直接取出像素值,就需要使用插值的方法来获取像素值。
理论上任意的插值方法都可以使用,作者介绍了两种插值方式:最近邻插值和双线性插值。双线性插值就是找出距离所求坐标最近的四个整数点,根据距离权重求和(距离越近权重越大,所以是1-距离)。下面列出了应用双线性插值的公式:(双线性插值的简单介绍:Spatial Transformer Networks)
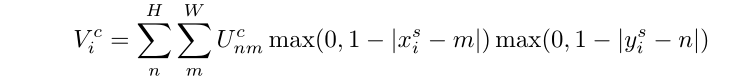
- 使用双线性插值可导,且满足
反向传播条件。为什么直接取最近的点值不行而要采用双线性插值的方法来进行反向传播可以看这篇解析 - 非插值部分一律取0,显示出来就是黑色像素块。
3 Conclusion
STN由Localisation network、Parameterised Sampling Grid以及Differentiable Sampling三部分组成,是一个独立的模块,可以在CNN体系结构的任意位置中加入任意数量的STN。该模块的加入可以使网络具备空间不变性,且STN模块计算速度非常快,只会造成很少的时间消耗。
STN网络有以下几个特点:
- 该模块可以作为插件放入任意网络中,并执行特征的显式空间变换,且无需对损失函数进行任何更改。
- STN是一个可导的网络,所以插入CNN后它可以实现端对端的训练。
- 在输入图像之后接一个ST是最常见的操作,也是最容易理解的,即自动图像矫正。
- 同一个网络层中也可以插入多个STN来对多个物体进行不同的空间变换。往往同一个STN模块仅用于检测单个物体并会对其他信息进行剔除。同一个网络层中的STN模块个数在一定程度上影响了网络可以处理的最大物体数量。
- STN模块可以插入到网络的任意位置,其输入可以是Image/feature map,输出也可以是Image/feature map。
- Pytorch源码:SPATIAL TRANSFORMER NETWORKS TUTORIAL
最后祝各位科研顺利,身体健康,万事胜意~