Spatial-Temporal Transformer for Dynamic Scene Graph Generation
论文地址:https://arxiv.org/abs/2107.12309
github地址:https://github.com/yrcong/sttran
STTran是一种可以利用时空上下文的Transformer (STTran: Spatial-Temporal Transformer)来生成动态场景图 (Dynamic Scene Graph).
主要贡献
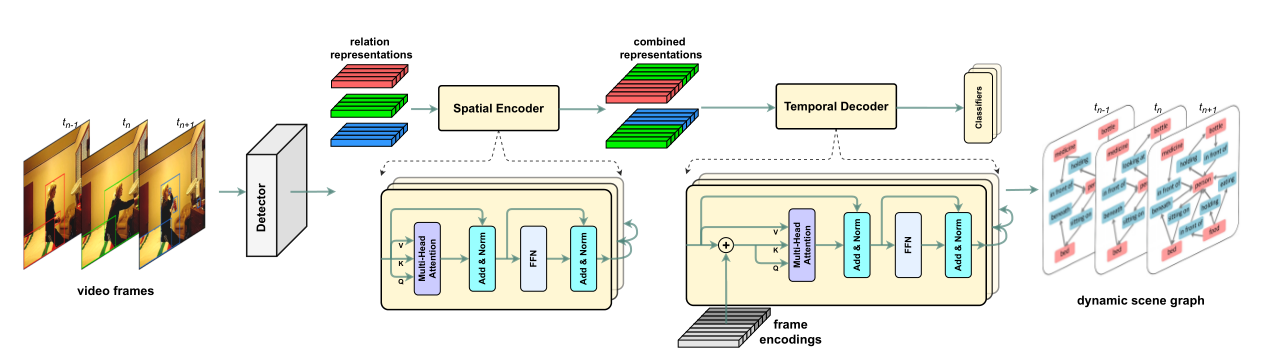
- 提出了用于动态场景图生成的时空转换器STTran,其编码器提取帧内的空间上下文,解码器捕获帧之间的时间依赖关系。
- 利用多标签损失引入一种新的生成场景图的策略:semi-constraint。
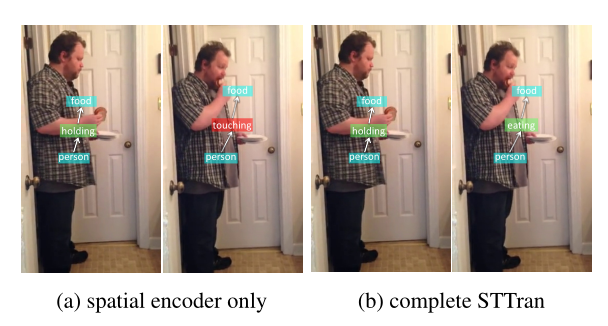
- 通过实验证明了STTran可以很好地利用时间上下文 (temporal context) 来改善关系检测。
研究背景
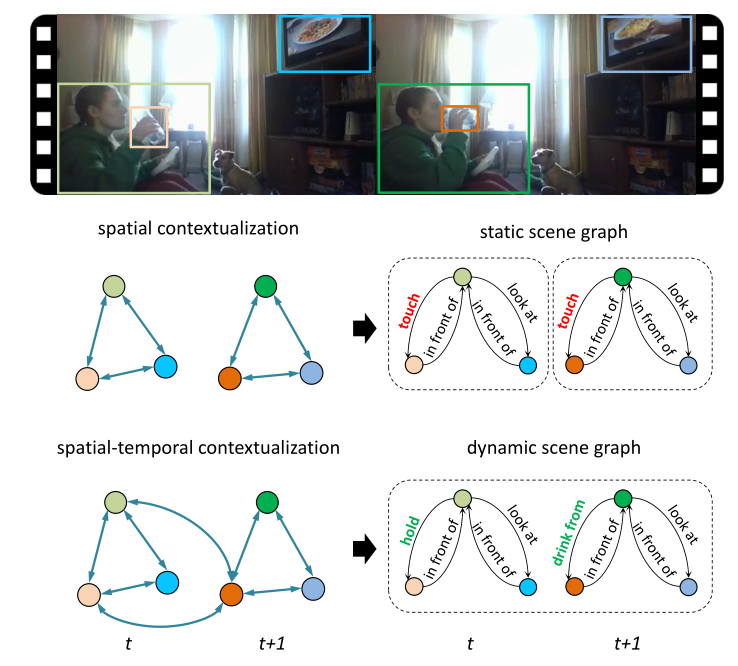
从视频生成动态场景图(Dynamic scene graph)比从图像生成场景图更具挑战性,因为目标之间的动态关系和帧之间的时间依赖性允许更丰富的语义解释。
如图显示了图像和视频生成场景图的不同:
主要实现
具体实现
转换器
首先回顾一下转换器的概念。转换器由Vaswani在《Attention is All You Need》中提出。
不懂的可以跳转这里进行学习。
- 在每一层中,给定 x x x有 N N N个 D D D维的输入, x ∈ R N × D x\in {R^{N \times D}} x∈RN×D,通过线性变换获取查询向量( Q = X W Q , W Q ∈ R D × D q Q=X{W_Q},{W_Q} \in R^{D \times {D_q}} Q=XWQ,WQ∈RD×Dq)、键向量( K = X W K , W K ∈ R D × D k K=X{W_K},{W_K} \in R^{D \times {D_k} } K=XWK,WK∈RD×Dk)和值向量( V = X W V , W V ∈ R D × D v V=X{W_V},{W_V} \in R^{D \times {D_v} } V=XWV,WV∈RD×Dv)。
- 其自注意层的公式如下: A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q K T D k ) V Attention(Q,K,V)=Softmax(\frac{Q{K}^T}{\sqrt{D_k}})V Attention(Q,K,V)=Softmax(DkQKT)V其中除以 D k \sqrt{D_k} Dk是为了让梯度更稳定,Softmax的作用是使所有输入归一化。
- 为了提高注意层的性能,采用多头注意力,其定义为: M u l t i H e a d ( Q , K , V ) = C o n c a t ( h 1 , . . . h h ) W o , h i = A t t e n t i o n ( X W Q i , X W K i , X W V i ) MultiHead(Q,K,V)=Concat(h_1,...h_h)W_o,h_i=Attention(X{W_{Q_i}},X{W_{K_i}},X{W_{V_i}}) MultiHead(Q,K,V)=Concat(h1,...hh)Wo,hi=Attention(XWQi,XWKi,XWVi)
- 之后是残差归一化层和前馈层,前馈层之后又是残差归一化层。
- 为了简单起见,将这种自我注意层表示为 A t t ( . ) Att(.) Att(.)。
在这项工作中,该文设计了一个基于 A t t ( . ) Att(.) Att(.)的时空转换器来探索工作在单个帧的空间上下文,和在序列上的时间依赖性。
关系表示
- 采用Faster R-CNN作为骨干;
- 给定一段视频内有T帧: V = [ I 1 , I 2 , . . . , I T ] V=[I_1,I_2,...,I_T] V=[I1,I2,...,IT],在时间t获取到 I t I_t It帧;
- 检测器提供视觉特征 { v t 1 , . . . , v t N ( t ) } ∈ R 2048 \{v_t^1,...,v_t^{N(t)}\}\in R^{2048} { vt1,...,vtN(t)}∈R2048,包围框 { b t 1 , . . . , b t N ( t ) } \{b_t^1,...,b_t^{N(t)}\} { bt1,...,btN(t)},对象类别分布 { d t 1 , . . . , d t N ( t ) } \{d_t^1,...,d_t^{N(t)}\} { dt1,...,dtN(t)},其中 N ( t ) N(t) N(t)表示 t t t时间帧中对象提议的个数。
- 在 N ( t ) N(t) N(t)个对象提议之间有一系列关系 R t = { r t 1 , . . . , r t k ( t ) } R_t=\{r_t^1,...,r_t^{k(t)}\} Rt={ rt1,...,rtk(t)}
- 第 i i i个和第 j j j个对象之间的关系 r t k r_t^k rtk的表示向量 x t k x_t^k xtk包含视觉特征、空间信息和语义嵌入,如下: x t k = < W s v t i , W o v t j , W u φ ( u t i j ⊕ f b o x ( b t i , b t j ) ) , s t i , s t j > x_t^k=<{W_s}{v_t^i}, {W_o}{v_t^j},{W_u}\varphi({u_t^{ij}\oplus f_{box}(b_t^i,b_t^j)),s_t^i,s_t^j}> xtk=<Wsvti,Wovtj,Wuφ(utij⊕fbox(bti,btj)),sti,stj>其中 < , > <,> <,>表示拼接, φ \varphi φ表示平滑操作, ⊕ \oplus ⊕表示元素相加, W s , W o ∈ R 2048 × 512 {W_s},{W_o}\in R^{2048 \times 512} Ws,Wo∈R2048×512, W u ∈ R 12544 × 512 {W_u}\in R^{12544 \times 512} Wu∈R12544×512,是用于维数压缩的线性矩阵, u t i j ∈ R 256 × 7 × 7 {u_t^{ij}\in R^{256 \times 7 \times 7}} utij∈R256×7×7表示并集盒通过ROIAlign计算后的特征图, f b o x f_{box} fbox是转换主客体的包围盒为一个和 u t i j {u_t^{ij}} utij相同形状的一个函数, s t i , s t j ∈ R 200 {s_t^i},{s_t^j}\in R^{200} sti,stj∈R200是对象类别的主体和客体。
关系表示在时空转换器中用来交换空间和时间信息。
时空转换器
空间编码器
- 关注于在一个帧中转换空间上下文,其输入为 X t = { x t 1 , x t 2 , . . . , x t K ( t ) } X_t=\{x_t^1,x_t^2,...,x_t^{K(t)}\} Xt={ xt1,xt2,...,xtK(t)};
- 其第n层的输出为: X t ( n ) = A t t e n c . ( Q = K = V = X t ( n − 1 ) ) X_t^{(n)}=Att_{enc.}(Q=K=V=X_t^{(n-1)}) Xt(n)=Attenc.(Q=K=V=Xt(n−1));
- 空间编码器由N个相同的 A t t e n c . Att_{enc.} Attenc.组成,并按顺序堆叠,第n层的输入为第n-1层的输出;
- 不同于一些主要的转换器方法,空间编码器没有将位置编码集成到输入中,因为帧内的关系在直观上是平行的;
- 在关系表示中隐藏的空间信息在自注意机制中起着至关重要的作用;
- 空间编码器堆栈的最终输出被发送到时域解码器中。
时域解码器中的帧编码
不同于以往的单词位置和像素位置,我们将定制帧编码来将时间未知注入到关系表中。
由于时域解码器中由窗口 η \eta η决定的嵌入向量的数量是固定的,且相对较短,因此帧编码 E f E_f Ef使用绝对嵌入参数构造的。 E f = [ e 1 , . . . e η ] E_f=[e_1,...e_\eta] Ef=[e1,...eη],其中 e 1 , . . . e η ∈ R 1936 e_1,...e_\eta \in R^{1936} e1,...eη∈R1936是和 x t k x_t^k xtk有相同长度的绝对向量。
实验中还使用了正弦编码方法作为对比。
时域解码器
- 时域解码器主要用来捕捉帧之间的时间依赖;
- 其使用滑动窗口对帧进行批处理,使消息在相邻帧之间传递,避免与远帧的干扰;
- A t t d e c . Att_{dec.} Attdec.和 A t t e n c . Att_{enc.} Attenc.一样都去掉了多头自注意层;
- 长度为 η \eta η的滑动窗口在 [ X 1 , . . . X T ] [X_1,...X_T] [X1,...XT]中运行,其中第 i i i个生成的输入批为 Z i = [ X i , . . . X i + η − 1 ] , i ∈ { 1 , . . . , T − η + 1 } , η ≤ T , T Z_i=[X_i,...X_{i+\eta-1}],i \in \{ 1,...,T-\eta+1\},\eta \leq T,T Zi=[Xi,...Xi+η−1],i∈{ 1,...,T−η+1},η≤T,T是整个视频的长度;
- 解码器和编码器相同,由N个相同的自注意层堆叠;
- 其第一层为: Q = K = Z i + E f Q=K=Z_i+E_f Q=K=Zi+Ef(这里增加了帧编码), V = Z i V=Z_i V=Zi, Z i ^ = A t t + d e c . ( Q , K , V ) \hat{Z_i}=Att+{dec.}(Q,K,V) Zi^=Att+dec.(Q,K,V)
- 最后一个解码器的输出作为最终预测;
- 由于使用了滑动窗口,一个帧中的关系在不同批次的输入中由不同的表示,选择最早出现在窗口中的表现;
损失函数
两个对象之间的相同类型的关系在语义上并不是唯一的,如hidding和touching。因此引入用于谓词分类的多标签边界损失函数: L p = ( r , ℘ + , ℘ − ) = ∑ p ∈ ℘ + ∑ q ∈ ℘ − m a x ( 0 , 1 − ϕ ( r , p ) + ϕ ( r , q ) ) L_p=(r,{ \wp }^{+},{ \wp }^{-})={\sum}_{p \in { \wp }^{+}} {\sum}_{q \in { \wp }^{-}}max(0,1-\phi(r,p)+\phi(r,q)) Lp=(r,℘+,℘−)=∑p∈℘+∑q∈℘−max(0,1−ϕ(r,p)+ϕ(r,q))其中 r r r表示主语-宾语对, ℘ + { \wp }^{+} ℘+表示被标注的谓语集合, ℘ − { \wp }^{-} ℘−表示未被标注的谓语集合, ϕ ( r , p ) \phi(r,p) ϕ(r,p)表示第 p p p个谓词的计算置信度。
层之间还有一个ReLU激活和一个批处理归一化,其使用标准交叉熵损失 L o L_o Lo,因此 L t o t a l = L p + L o L_{total}=L_p+L_o Ltotal=Lp+Lo
图生成策略
已有以下两种策略:
| 名称 | 描述 | 作用 | 缺点 |
|---|---|---|---|
| With Constraint | 允许每个主客体对中最多一个谓词 | 要求更严格,用来反映模型预测最重要关系的能力 | 不能胜任多标签任务 |
| No Constraint | 允许每个主客体对有多个谓词猜测 | 可以反应多标签预测的能力 | 可能导致生成的场景图的信息错误 |
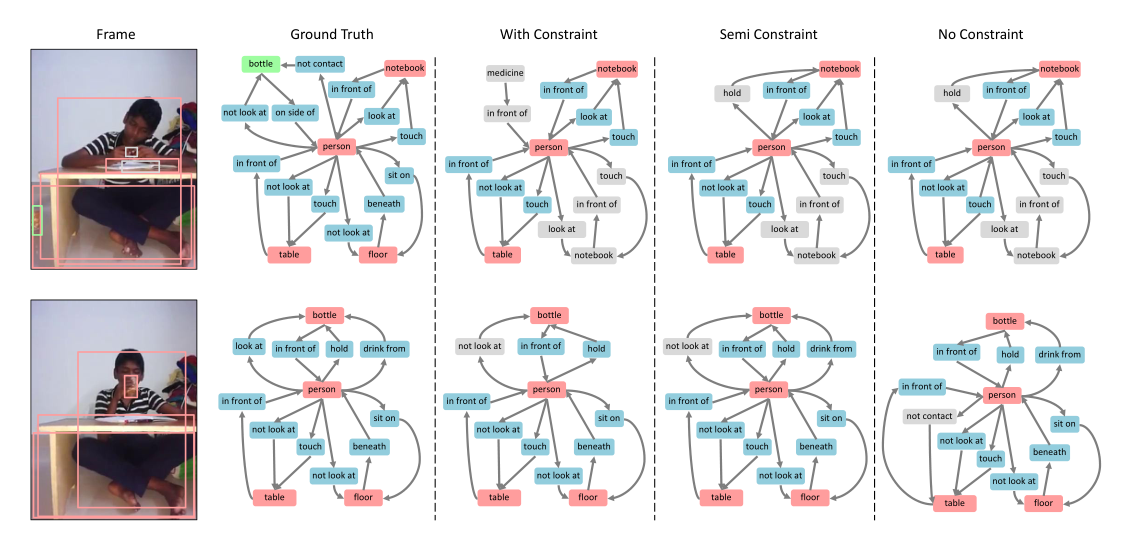
因此提出Semi-Constraint,其可以允许主客体有多个谓词,当且只有对应关系的置信度高于阈值时,才认定该谓词有效。
其中 < s u b j e c t − p r e d i c a t e − o b j e c t > <subject-predicate-object> <subject−predicate−object>三元组的得分为其置信度相乘: S r e l = S s u b ⋅ S p ⋅ S o b j S_{rel}=S_{sub} \cdot S_{p} \cdot S_{obj} Srel=Ssub⋅Sp⋅Sobj
其结果如下图所示:
实验数据
数据集
Action Genome (AG)数据集,提供了帧级场景图标签,建立在Charades数据集之上。它包括35 个目标类(没有人) 476229 个边框和 25 个关系类的 1715568 个实例,一共标注 234253 帧。
这 25 种关系细分为三种不同的类型:
- attention relationships 表示一个人是否正在看一个目标
- spatial relationships 空间关系
- contact relationships 表示接触目标的不同方式。
在 AG 数据中,有135484 个主-宾对,标记为多种spatial relationships(例如<人-前面-门> 和<人-侧面-门>)或contact relationships(例如<人-吃-食物> 和 <人-拿-食物>)。
评价指标
有以下三种评价指标:
- 谓词分类 PREDCLS:给定GT标签和对象的包围盒,预测对象对的谓词标签;
- 场景图分类 SGCLS:对GT包围盒和预测关系标签进行分类;
- 场景图检测 SGDET:检测对象并预测对象对的关系标签;
使用Recall@K 指标(K=10,20,50):即对预测三元组进行排序,分数前k个预测中,预测正确三元组的占比,即预测正确的三元组个数/GT三元组个数。
实验结果
在时空上下文的帮助下,STTran在场景图生成的三个setting中都优于基于图像的SOTA方法:
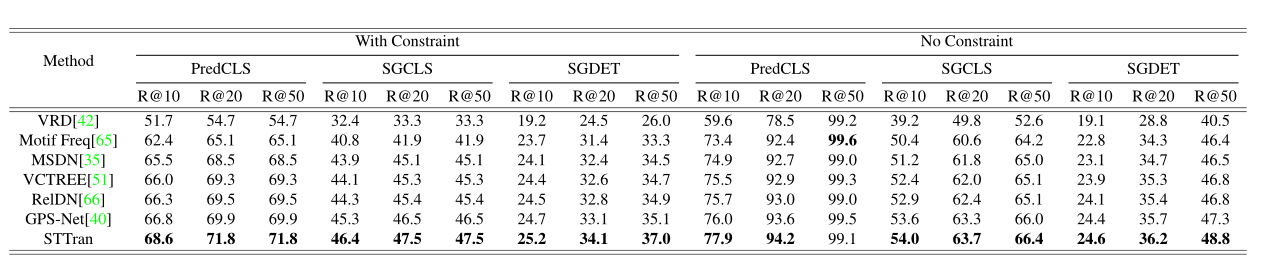
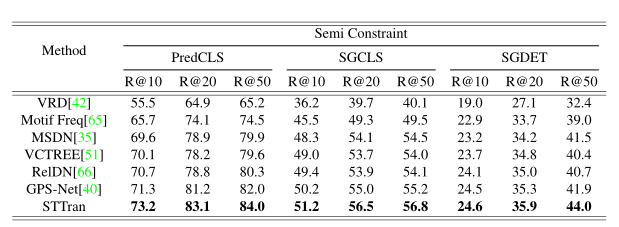
通过集成lstm来处理关系特征,然后将它们转发到分类器中,进入一些有代表性的基线。所有的基线都通过时间依赖得到了改进,但依旧比STTran差。

更多的实验内容和细节请看论文。
结论
- 该文提出了一种用于动态场景图生成的时空转换器(spatial - temporal Transformer, STTran),其编码器提取帧内的空间上下文,解码器捕获帧间的时间依赖关系。
- 与以往的单标签损失不同,该文利用多标签损失并引入一种新的生成场景图的策略。
- 多个实验表明,时间背景对关系预测有积极影响。
- 在Action Genome数据集上,动态场景图生成任务其获得了最先进的结果。