我们要找的是一个概率。

f即x属于C1的几率。

上面的过程就是logistic regression。
下面将logistic regression与linear regression作比较。

接下来训练模型,看看模型的好坏。

假设有N组training data,如上蓝框中显示,x1属于C1,其他类推。假设这组training data是从![]() 函数产生的。
函数产生的。
给我们一组w和b,我们就可以决定![]() 函数。
函数。
某一组w和b,产生N组training data的几率怎么计算?
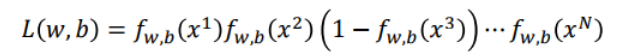
假设x3属于C2,则就有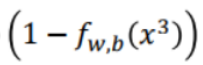 ,其他以此类推。
,其他以此类推。
有最大可能性可以产生这组training data的w和b我们叫做

这其实就是概率论与数理统计中的最大似然估计。

我们可以把似然函数写成对数似然函数,这样更好计算。取ln后上面的相乘式就变成了相加式。
即
加上负号,那么就从找似然函数的最大值变成找对数似然函数的最小值。
如果某个xi属于class1,我们就说它的target是1,如果它属于class2,我们就说它的target是0。
于是对数似然函数可以写成:

注意从左边到右边的写法实际上是交叉熵。

上面的展开式我们可以写成:
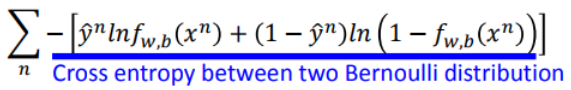
这就是交叉熵。(实际上是两个伯努利分布的交叉熵)
即:假设有两个伯努利分布p和q如下:

则p和q的交叉熵为:
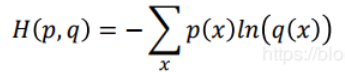
那么在logistic regression中如何定义function的好坏?

我们使用上面的交叉熵函数作为loss function来确定函数的好坏。
为什么要用交叉熵函数作为loss function而不用方差和的平均值?
个人的理解是,logistic regression的输出经过了sigmoid函数的处理,使得输出值都在(0,1)之间;而linear regression的输出可以是任何值(不限制区间),因此如果logistic regression的loss function使用方差和的平均值的话,其loss值就会很小。效果不太好。
下面我们要找一个最好的function。

整理一下,结果为:

接下来我们继续比较linear regression和logistic regression更新参数的方式:

我们可以发现它们更新参数的方式是一模一样的。唯一不同的是,logistic regression的![]() 一定是0或1,
一定是0或1,![]() 的值一定在(0,1)内。
的值一定在(0,1)内。
logistic regression如果用squaer Error作为loss函数会怎么样?

这时候如果你离目标很近或很远时,其梯度算出来都是0。这时对class1的例子,如果对class2,结果也一样。

如果我们把loss值变化做成图,如下:

如果用Square Error作为loss function,那么无论是离最低点很近或很远时其梯度都接近0,参数更新会非常慢。
如果用cross entropy作为loss function,那么离的远时梯度大,离的近时梯度小。
所以我们要用cross entropy。
我们可以发现linear regression和logistic regression的model是一样的。

不同的是logistic regression的输出用sigmoid函数作了处理。
虽然是同一种model的形式,但是因为我们作了不同的假设,我们根据同一组training data找出来的w和b也不一样。
如果我们比较生成模型和判别模型:

为什么我们会觉得discriminative model比generative model更好?
我们举一个例子。

class1只收集到1笔data,class2共收集到12笔data。
这时给出图上的testing data,你觉得它是class1或2?
我们看看贝叶斯公式:
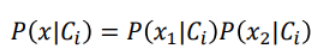
我们来根据training data统计一下几率:

现在我们计算test data属于class1的几率。

结果小于0.5。也就是说用贝叶斯公式的话,机器会认为这个test data属于class1的几率小于0.5。
为什么会这样?因为对贝叶斯公式,各个样本都是独立的。
如果我们用logistic regression(属于discriminative model),我们会认为test data属于class1的几率更大。
如果我们用generative model,如上面的贝叶斯公式,由于generative model要做种种的假设,最后反而计算出test data属于class2的几率更大。当然,这种判断不一定是错的。
如果train data很少时,使用generative model可以得到更准确的判断;
如果model中的train data中noise较多时,使用discriminative model的判断更准确。
换句话说,在某些应用场景中,我们可以确定数据的来自哪个分布的先验概率。这种情况下discriminative model的判断更准确。
下面看看Multi-class Classification。

这个时候我们使用softmax函数对输出做处理。

如果只有二分类的情况下使用softmax就退化成logistic regression的情况。
logistic regression的限制:

如果有上面这一组train data,这时候我们可以发现,我们无法用一条直线将所有的红点的z>0,蓝点z<0分辨划分在直线的两边。

这时怎么办呢?我们可以对原来的featrue做一下转换:
但是feature transformation的函数不是很好找,转换了也不一定就能够找出一个合适的logistic regression。
feature transformation可以看成多个logistic regression的重叠。

这个其实就是多层感知机。
即x1和x2通过蓝色和绿色的logistic regression先处理生成x1',x2'。
现在我们给蓝色和绿色的logistic regression各假设一组参数。计算出的结果如下图右边的图。

接下来红色的logistic regression的输入就是x1',x2'。

上面的这个结构就是deep learning中的神经元结构。由许多神经元结构组成一个神经网络。

这就是deep learning。