Preface
Unsupervised Learning(无监督学习)
K-means聚类算法
Unsupervised Learning
我们以前介绍的所有算法都是基于有类别标签的数据集,当我们对于没有标签的数据进行分类时,以前的方法就不太适用了。我们对于这样的数据集的分类叫做,聚类。对于对于这样的数据集的学习算法叫做,无监督学习。
K-means聚类算法
K-means聚类算法的目标就是将给定的数据集分成 类。( 由我们自己指定)
算法内容
- 随机选取n个聚类中心, 。
- 重复下面过程直到收敛 {
对于每一个样本 ,计算其应该属于的类:
对于每一个聚类 ,计算属于的类的聚类中心:
}
在上述算法过程中, 表示样本 到聚类中心点集合的最小值(表示为样本 属于取得最小值的那个聚类中心点); 表示为聚类中心,即为属于这个的所有样本的均值。
下图为选择k=2的聚类过程:
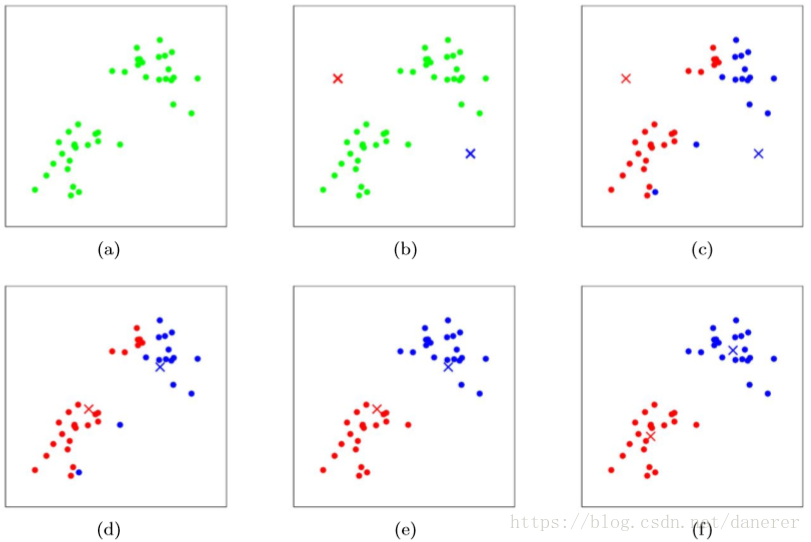
收敛验证
K-means 算法面对有一个重要问题时如何保证收敛,在上述算法内容中强调结束条件就是收敛,所以证明K-means 算法可以收敛至关重要。
首先,我们定义畸变函数(distortion function):
J函数表示每个样本点到其质心的距离平方和。K-means是要将J调整到最小。假设当前J没有达到最小值,那么首先可以固定每个簇中心 ,调整每个样例的所属的类别 来让J函数减少,同样,固定 ,调整每个簇中心 也可以使J减小。这两个过程就是内循环中使J单调递减的过程。当J递减到最小时, 和 也同时收敛。(在理论上,可以有多组不同的 和 值能够使得J取得最小值,但这种现象实际上很少见)。其实整体来看,这个算法就是坐标上升算法。
如果畸变函数J是非凸函数,意味着我们不能保证取得的最小值是全局最小值,也就是说k-means对簇中心初始位置的选取比较敏感,但一般情况下k-means达到的局部最优已经满足需求。但如果你怕陷入局部最优,那么可以选取不同的初始值跑多遍k-means,然后取其中最小的J对应的 和 输出。