Preface
Jensen’s Inequality(Jensen不等式)
Expectation-Maximization Algorithm(EM算法)
Jensen’s Inequality
对于凸函数
令
f(x)
为一个凸函数,且如果它有二阶导数,其二阶导数恒大于等于0(
f(x)′′≥0
)。令
x
为一个随机变量,那么:
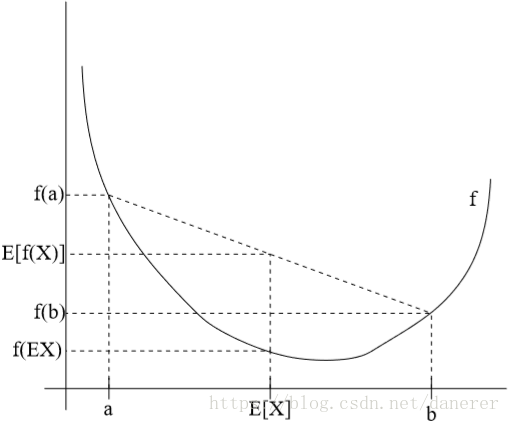
E[f(x)]≥f(EX)
这个不等式的含义如下图所示:
我们可以进一步推导出,如果
f(x)′′>0
,即
f(x)
为一个严格的凸函数。那么:
E[f(x)]=f(EX)⟺x为常量的概率为1⟺X=EX的概率为1
对于凹函数
如果
f(x)′′≤0
,即
f(x)
为一个凸函数。那么:
f(EX)≥E[f(x)]
Expectation-Maximization Algorithm
问题定义
假设训练集
{x(1),x(2),...,x(m)}
是由m个独立的无标记样本构成。我们有这个训练集的概率分布模型
p(x,z;θ)
,但是我们只能观察到
x
。我们需要使参数
θ
的对数似然性最大化,即:
argmaxθl(θ)=argmaxθ∑mi=1logp(x(i);θ)=argmaxθ∑mi=1log∑zp(x(i),z(i);θ)
形式化过程
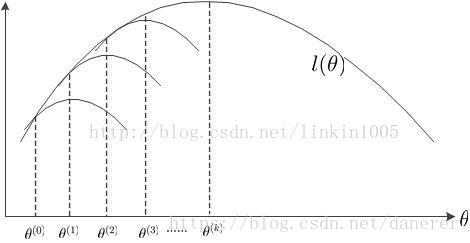
EM算法的过程大致如下:
首先,初始化
θ(0)
,调整
Q(z)
使得
J(Q,θ(0))
与
θ(0)
相等,然后求出
J(Q,θ(0))
使得到最大值的
θ(1)
;固定
θ(1)
,调整
J(Q,θ(1))
,使得
J(Q,θ(1))
与
θ(1)
相等,然后求出
J(Q,θ(1))
使得到最大值的
θ(2)
;……;如此循环,使得
l(θ)
的值不断上升,直到k次循环后,求出了
l(θ)
的最大值
l(θ(k))
。
推导过程
在问题定义中我们知道:
argmaxθl(θ)=argmaxθ∑mi=1logp(x(i);θ)=argmaxθ∑mi=1log∑zp(x(i),z(i);θ)
接下来我们正式开始EM算法的推导:
假设每一个
z(i)
的分布函数为
Qi
。故有
∑ZQi(z)=1,Qi(z)≥0
。所以:
l(θ)=∑ilog∑z(i)p(x(i),z(i);θ)=∑ilog∑z(i)Qi(z(i))p(x(i),z(i);θ)Qi(z(i))≥∑i∑z(i)Qi(z(i))logp(x(i),z(i);θ)Qi(z(i))(1)(2)(3)
对于上述公式中的第(2)步到第(3)步的理解:
- 首先由于数学期望公式
Y=g(X),g(X)为连续函数;E(Y)=E(g(x))=∏∞k=1g(xk)pk
,
∑z(i)Qi(z(i))p(x(i),z(i);θ)Qi(z(i))
可以看做随机变量为
Qi(z(i))
概率分布函数为
p(x(i),z(i);θ)Qi(z(i))
的期望,即为:
∑z(i)Qi(z(i))p(x(i),z(i);θ)Qi(z(i))=E(p(x(i),z(i);θ)Qi(z(i)))
- 由Jensen不等式,且
f(x)=logx,f′′(x)=−1x2<0
,所以:
f(Ez(i)∼Qi[p(x(i),z(i);θ)Qi(z(i))])≥Ez(i)∼Qi[f(p(x(i),z(i);θ)Qi(z(i)))]
所以参数
θ
的对数似然性就有了一个下界,我们回想在EM算法的形式化过程中的不断推进得到的下界不断上升的过程,在这里我们也希望得到一个更加紧密的下界,也就是使等号成立的情况。
根据Jensen不等式,所以有:
p(x(i),z(i);θ)Qi(z(i))=c(c为常数)
所以:
Qi(z(i))=c∗p(x(i),z(i);θ)(c为常数)
因为
∑ZQi(z)=1,Qi(z)≥0
,所以:
∑ZQi(z(i))=∑Zc∗p(x(i),z(i);θ)=1(c为常数)
所以:
c=1∑Zp(x(i),z(i);θ)(c为常数)
所以:
Qi(z(i))=p(x(i),z(i);θ)∑zp(x(i),z;θ)=p(x(i),z(i);θ)p(x(i);θ)=p(z(i)|x(i);θ)
EM算法
EM算法主要有两个步骤,EM算法的具体内容如下:、
Repeat until convergence{
- (E-step) for each i, set
Qi(z(i)):=p(z(i)|x(i);θ)
- (M-step) set
θ:=argmaxθ∑i∑z(i)Qi(z(i))logp(x(i),z(i);θ)Qi(z(i))
}
收敛性证明
我们可以定义一个优化目标
J(Q,θ)=∑i∑z(i)Qi(z(i))logp(x(i),z(i);θ)Qi(z(i))
使用Jensen不等式,我们可以推导出:
l(θ)≥J(Q,θ)
回顾前面所学的知识,EM 可以看作是函数 J 的坐标上升法,E步固定θ优化Q,M 步固定Q优化θ。 再利用相关知识便可以证明。