这是一次教授布置的期末作业,也是书籍《商务数据分析与应用》的一个课后作业
目录
数据描述
数据预处理
描述性统计分析
模型分析(方差分析)
数据描述
非学位职业培训机构的178个学员的数据,目的是了解什么样的学员可能获得更好的学习效果
数据预处理
打开数据,查看一部分数据并锁定数据(这样之后可以直接使用变量名而不用$来指定数据)
grades=read.table('E:/SWlearning/R/assighment/RegressionAnalysis/Report/ins1.csv',
header=TRUE,sep=',')
head(grades)
attach(grades)
结果显示

将变量名改成英文
names(grades)=c('aveGrades','gender','birth','firmType','eduBG','eduGrd')
响应变量(因变量):因变量.平均成绩(aveGrades)
自变量:性别(gender),出生日期(birth),企业性质(firmType),最高学历(eduBG),最高学历毕业时间(eduGrd)
检查相应变量的正态性
shapiro.test(aveGrades)
结果显示
Shapiro-Wilk normality test
data: aveGrades
W = 0.89736, p-value = 9.286e-10
p值非常的小故拒绝原假设,即拒绝数据是正态分布的原假设
接下来用BoxCox的方法,建立新的相应变量从而保证其正态性,注意BoxCox.ar是包TSA里的函数
library(TSA)
boxcox=BoxCox.ar(aveGrades,lambda = seq(4, 8, 0.1))
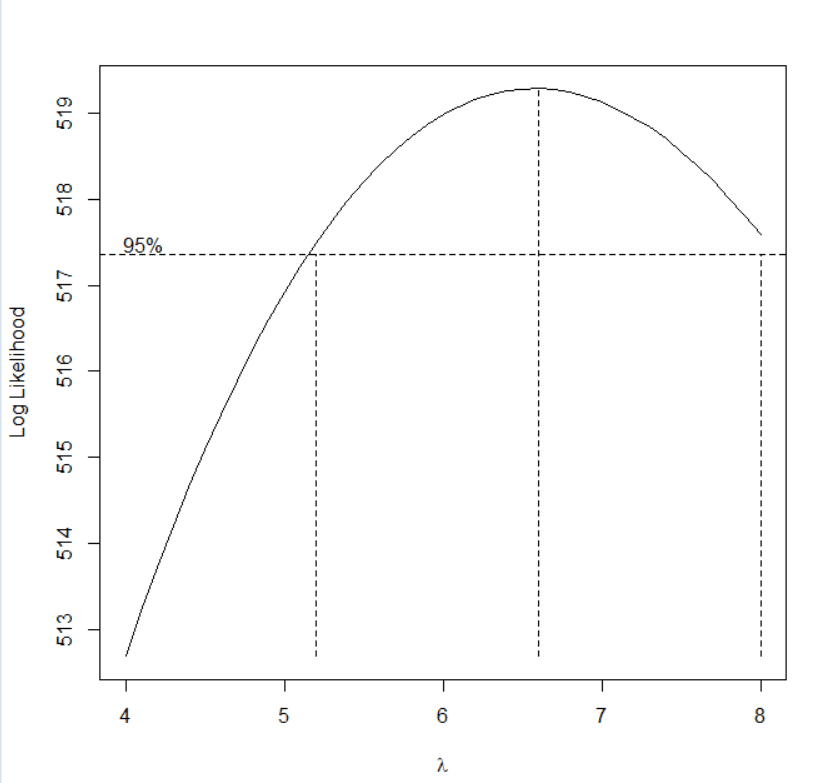
查看最优的lamda值
boxcox$mle
建立新的响应变量
aveGrades_mod=grades$aveGrades^6.6
检验新的响应变量的正态性
shapiro.test(aveGrades_mod)
结果显示
Shapiro-Wilk normality test
data: aveGrades_mod
W = 0.99007, p-value = 0.2522
p值达到了我们期望的结果,不拒绝原假设,即接受新的响应变量是正态分布的假设
描述性统计分析
注意我们的因变量中,出生日期(birth)和最高学历毕业时间(eduGrd)不是离散变量,我们将以十年的单位将这两个变量分类
出生日期(birth)中最大是 1952-6-26,最小是 1979-11-10,分成五十年代(1),六十年代(2), 七十年代(3)
最高学历毕业时间(eduGrd)中最大是 1982-1-1,最小是 2004-3-1,分为八十年代(1),九十年代(2), 零零后(3)
第一步
将出生日期(birth)和最高学历毕业时间(eduGrd)变成日期型变量以便之后的操作
birthmod=as.Date(grades$birth)
eduGrdmod=as.Date(grades$eduGrd)
第二步
我们先对出生年月进行分类
//d1~d4分别是四个时间节点,用来将数据分成五十年代(1),六十年代(2), 七十年代(3)
d1=as.Date('1950/1/1')
d2=as.Date('1960/1/1')
d3=as.Date('1970/1/1')
d4=as.Date('1980/1/1')
//计算出生日期(birthmod)中的数据个数
s=0
for(i in birthmod){
s=s+1
}
//建立新的数值型变量。因为birthmod是日期型变量,不能直接赋数值型的值如1,2,3
birth_mod=1:s
//开始分类
for(i in 1:s){
fac1=birthmod[i]-d1>0 & birthmod[i]-d2<=0
fac2=birthmod[i]-d2>0 & birthmod[i]-d3<=0
fac3=birthmod[i]-d3>0 & birthmod[i]-d4<=0
if(fac1){birth_mod[i]=1}
if(fac2){birth_mod[i]=2}
if(fac3){birth_mod[i]=3}
}
//给新变量birth_mod三个水平1,2,3
levels(birth_mod)=c(1,2,3)
//将数据类型变成factor,以便之后的统计
birth_mod=as.factor(birth_mod)
对最高学历毕业时间是同样的程序
d5=as.Date('1990/1/1')
d6=as.Date('2000/1/1')
d7=as.Date('2010/1/1')
s=0
for(i in eduGrdmod){
s=s+1
}
eduGrd_mod=1:s
for(i in 1:s){
fac3=eduGrdmod[i]-d4>0 & eduGrdmod[i]-d5<=0;fac3
fac4=eduGrdmod[i]-d5>0 & eduGrdmod[i]-d6<=0;fac4
fac5=eduGrdmod[i]-d6>0 & eduGrdmod[i]-d7<=0;fac5
if(fac3){eduGrd_mod[i]=1}
if(fac4){eduGrd_mod[i]=2}
if(fac5){eduGrd_mod[i]=3}
}
levels(eduGrd_mod)=c(1,2,3)
eduGrd_mod=as.factor(eduGrd_mod)
第三步
建立新的数据集grades_mod,注意此处的响应变量(aveGrades)没有用之前为了正态性修改的新的响应变量(aveGrades_mod),这里用aveGrades是为了结果好看,且不影响我们进行描述性统计分析
grades_mod=cbind(grades$aveGrades,grades[2],birth_mod,grades[4:5],eduGrd_mod)
summary(grades_mod)结果显示
grades$aveGrades gender birth_mod firmType eduBG eduGrd_mod
Min. :50.00 男:133 1:10 国企:95 本科 :148 1: 48
1st Qu.:77.00 女: 45 2:85 民企:43 大专 : 25 2:104
Median :81.00 3:83 外企:40 硕士 : 2 3: 26
Mean :79.72 硕士或以上: 3
3rd Qu.:84.00
Max. :91.00
第四步
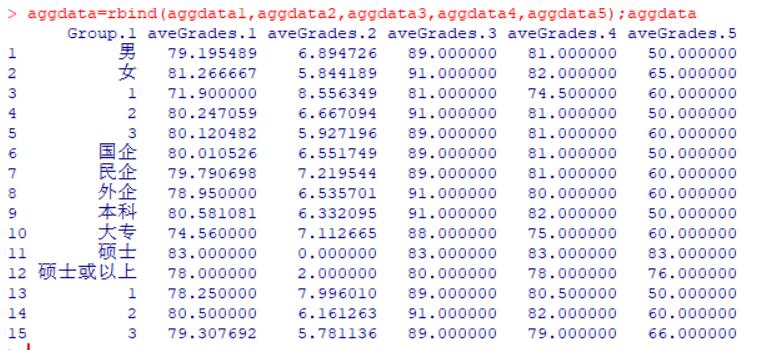
我们还想知道,各个因变量不同水平对应的学员平均成绩
//编写一个输出均值,标准差,最大值,中位数,最小值的函数
stats = function(x){
m = mean(x)
sd= sd(x)
max = max(x)
median = median(x)
min= min(x)
return=c(m,sd,max,median,min)
}
//aggregate是一个重新显示数据的函数,比如在aggdata1中,能显示按性别分类后,男性学员和女性学员对应的平均成绩的均值,标准差,最大值,中位数,最小值,FUN是function函数的意思
aggdata1= aggregate(grades['aveGrades'],
by=list(gender),FUN=stats);aggdata1
aggdata2= aggregate(grades['aveGrades'],
by=list(birth_mod),FUN=stats)
aggdata3= aggregate(grades['aveGrades'],
by=list(firmType),FUN=stats)
aggdata4= aggregate(grades['aveGrades'],
by=list(eduBG),FUN=stats);aggdata
aggdata5= aggregate(grades['aveGrades'],
by=list(eduGrd_mod),FUN=stats)
//按行将数据重叠起来
aggdata=rbind(aggdata1,aggdata2,aggdata3,aggdata4,aggdata5);aggdata
结果显示
模型分析
接下来我们将进行方差分析
第一步
//进行方差分析的函数是aov,~前面是响应变量,注意此时我们得保证响应变量的正态性,所以用的是新的响应变量(aveGrades_mod)而非原始数据,~后面是自变量,在此模型中还包括了所有的交互项
res.ano1=aov(aveGrades_mod~gender+birth_mod+firmType+eduBG+eduGrd_mod+
gender:birth_mod+gender:firmType+gender:eduBG+gender:eduGrd_mod+
birth_mod:firmType+birth_mod:eduBG+birth_mod:eduGrd_mod+
firmType:eduBG+firmType:eduGrd_mod+
eduBG:eduGrd_mod)
//显示方差分析结果
res1=summary(res.ano1);res1
结果显示

第二步
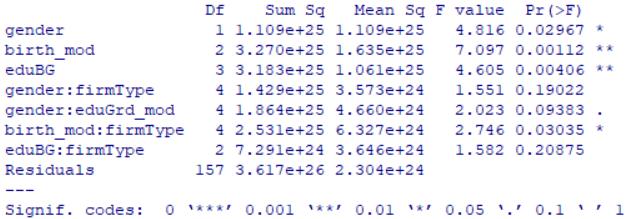
剔除没通过显著性检验的变量, 用剩下的变量再做一次方差分析
res.ano2=aov(aveGrades_mod~gender+birth_mod+eduBG+
gender:firmType+gender:eduGrd_mod+
birth_mod:firmType+
firmType:eduBG)
res2=summary(res.ano2);res2
结果显示
第三步
剔除没通过显著性检验的变量, 用剩下的变量再做一次方差分析
res.ano3=aov(aveGrades_mod~gender+birth_mod+eduBG+
gender:eduGrd_mod+
birth_mod:firmType)
res3=summary(res.ano3);res3
结果显示
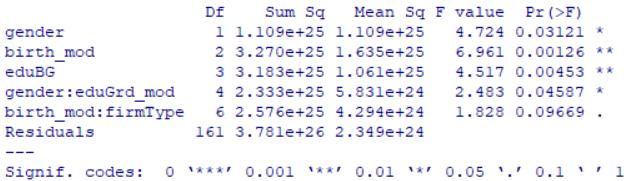
性别(gender),出生日期(birth_mod),最高学历(eduBG)以及交互作用, 性别:最高学历毕业日期(gender:eduGrd_mod),出生日期:企业性质(birth_mod:firmType)都通过了在 0.1 水平下的显著性检验
拒绝原假设,即变量的水平不同会显著影响成绩,如性别中,男生和女生的成绩显著不同,而企业性质的不同不影响学员的成绩