用 R 做数据分析
Vol_0:数据的数字特征及相关分析
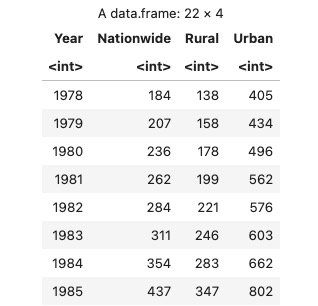
导入数据
导入文本表格数据
Year Nationwide Rural Urban
1978 184 138 405
1979 207 158 434
1980 236 178 496
1981 262 199 562
1982 284 221 576
1983 311 246 603
1984 354 283 662
1985 437 347 802
...
R 代码:
data <- read.table("./data.txt", header=TRUE)
data
结果:
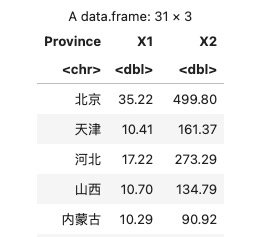
导入 CSV 数据
序号,省市区,11月,1~11月
1,北京,35.22,499.8
2,天津,10.41,161.37
3,河北,17.22,273.29
4,山西,10.7,134.79
5,内蒙古,10.29,90.92
...
R 代码:
data <- read.csv("./data.csv")
注:这个数据里表头标题有中文、有特殊符号,会被 R 自动处理成:
> cat(names(data))
X.序号 省市区 X11月 X1.11月
可以手动改一下:
data <- data[-1] # remove "序号" col
names(data) <- c("Province", "X1", "X2")
data
结果:
注:后文里会随机使用这两个导入的数据中的一个作示例。
attach
为了方便调用 data.frame 里的各列数据,我们可以:
attach(data)
然后就可以直接用列名引用一列数据了,比如:
print(X1)
不必再通过 data 取索引:
print(data[2])
用完之后,记得 detach:
detach(data)
均值、方差、标准差、变异系数、偏度、峰度
单变量
数据:一个变量,一“列”数据
x <- c(1, 2, 3, 4, 5)
均值:
x ‾ = 1 n ∑ i = 1 n x i \overline x = \frac{1}{n}\sum_{i=1}^nx_i x=n1i=1∑nxi
mean(x)
方差:
s 2 = 1 n − 1 ∑ i = 1 n ( x i − x ‾ ) 2 s^2=\frac{1}{n-1}\sum_{i=1}^n(x_i-\overline x)^2 s2=n−11i=1∑n(xi−x)2
var(x)
标准差:
s = s 2 = 1 n − 1 ∑ i = 1 n ( x i − x ‾ ) 2 s = \sqrt{s^2}=\sqrt{\frac{1}{n-1}\sum_{i=1}^n(x_i-\overline x)^2} s=s2=n−11i=1∑n(xi−x)2
sd(x)
变异系数:
C V = s x ‾ CV = \frac{s}{\overline x} CV=xs
cv <- function(x) sd(x)/mean(x)
cv(x)
注:书上是百分数的 C V = 100 × s x ‾ ( % ) CV = 100 \times \frac{s}{\overline x} (\%) CV=100×xs(%).
偏度:
g 1 = 1 ( n − 1 ) ( n − 2 ) 1 s 3 ∑ i = 1 n ( x i − x ‾ ) 3 g_1=\frac{1}{(n-1)(n-2)}\frac{1}{s^3}\sum_{i=1}^n(x_i-\overline x)^3 g1=(n−1)(n−2)1s31i=1∑n(xi−x)3
g1 <- function(x) {
n <- length(x)
A <- n / ((n-1) * (n-2))
B <- 1 / sd(x)^3
S <- sum((x - mean(x))^3)
A * B * S
}
g1(x)
峰度:
g 2 = n ( n + 1 ) ( n − 1 ) ( n − 2 ) ( n − 3 ) 1 s 4 ∑ i = 1 n ( x i − x ‾ ) 4 − 3 ( n − 1 ) 2 ( n − 2 ) ( n − 3 ) g_2 = \frac{n(n+1)}{(n-1)(n-2)(n-3)}\frac{1}{s^4}\sum_{i=1}^n(x_i-\overline x)^4\\-\frac{3(n-1)^2}{(n-2)(n-3)} g2=(n−1)(n−2)(n−3)n(n+1)s41i=1∑n(xi−x)4−(n−2)(n−3)3(n−1)2
g2 <- function(x) { # 峰度
n <- length(x)
A <- (n * (n+1)) / ((n-1) * (n-2) * (n-3))
B <- 1 / sd(x)^4
S <- sum((x - mean(x))^4)
C <- (3 * (n-1)^2) / ((n-2) * (n-3))
A * B * S - C
}
g2(x)
作用于 data.frame
我们导入的数据都是 data.frame,可以单独取出一列来,就和上面的 x 一样了:
x <- data[[2]] # 取出 data 的第二列数据
mean(x)
但每一列都都调用一次也很烦,所以这里还有一种方法,一次性把 mean 或者其他函数作用于 data.frame 的各列(这里用前文第一个表格导入进来的 data 做例子):
apply(data[-1], MARGIN=2, FUN=mean)
结果:

说明:
- 这里 data 的第一列是字符的,求均值没有意义: 用
data[-N]去掉第 N 列(R 从1开始索引) - 第二个参数
MARGIN=2就是逐列处理 - 第三个 FUN 是要作用的函数,这里是求均值。方差什么的也是一样的,把这个参数换成
FUN=var啥的就行了。
all in one
为了方便,我们可以把算这几个东西的过程封装在一起:
describes <- function(df) {
# TODO(CDFMLR): 优化重复计算
cv <- function(x) sd(x)/mean(x) # 变异系数
g1 <- function(x) { # 偏度
n <- length(x)
A <- n / ((n-1) * (n-2))
B <- 1 / sd(x)^3
S <- sum((x - mean(x))^3)
A * B * S
}
g2 <- function(x) { # 峰度
n <- length(x)
A <- (n * (n+1)) / ((n-1) * (n-2) * (n-3))
B <- 1 / sd(x)^4
S <- sum((x - mean(x))^4)
C <- (3 * (n-1)^2) / ((n-2) * (n-3))
A * B * S - C
}
itm <- matrix(c("均值", "方差", "标准差", "变异系数", "偏度", "峰度"), 6, 1)
res <- apply(df, 2,
function(x) c(mean(x), var(x), sd(x), cv(x), g1(x), g2(x)))
cbind(itm, res)
}
传入参数是一个 data.frame,这个函数会求出各列的均值、方差等,(例如作用于前文导入的 csv 数据):
describes(data[-1])
结果:

一次性全出来了,这样就很方便。
调包
当然,这些操作都有第三方包有封装实现,比如这个:
安装这个包(直接在 R 里面写):
install.packages("psych")
导包:
library(psych)
然后就可以用这个包里的东西了。
这个包提供了前面最难写的峰度偏度:
# g1、g2 是用 type=2: see help(skew)
g1 <- function(x) skew(x, type=2)
g2 <- function(x) kurtosi(x, type=2) # help(kurtosi)
这个包还提供了一个 describe 函数可以一次性求出前面大多数值(类似于我们手写的 describes):
describe(data[-1], type=2)
结果:

中位数、上下四分位数、四分位极差
可以先求五数:最小值、下四分位数、中位数、上四分位数、最大值
fn <- apply(data[-1], 2, fivenum)
fn
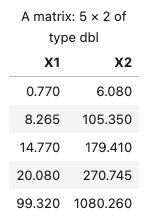
四分位极差:
R1 <- function(Q3, Q1) Q3 - Q1
R1(Q3=fn[4,], Q1=fn[2,])
[Math Time]
p 分位数:
M p = { x ( [ n p ] + 1 ) , n p 不是整数 1 2 ( x ( n p ) + x ( n p + 1 ) ) , n p 是整数 M_p=\left\{\begin{array}{ll} x_{([np]+1)} ,& np \textrm{ 不是整数}\\ \frac{1}{2}(x_{(np)}+x_{(np+1)}) ,& np \textrm{ 是整数}\\ \end{array}\right. Mp={ x([np]+1),21(x(np)+x(np+1)),np 不是整数np 是整数
上下四分位数:
Q 3 = M 0.75 , Q 1 = M 0.25 Q_3=M_{0.75}, \qquad Q_1=M_{0.25} Q3=M0.75,Q1=M0.25
四分位极差:
R 1 = Q 3 − Q 1 R_1=Q_3-Q_1 R1=Q3−Q1
注:R 求分位数用 quantile,详见 help(quantile)。
有了上下四分位数、四分位极差,可以求个异常数据:
定义:下、上截断点:
Q 1 − 1.5 R 1 , Q 3 + 1.5 R 1 Q_1-1.5R_1,\qquad Q_3+1.5R_1 Q1−1.5R1,Q3+1.5R1
大于「上截断」、小于「下阶段」的数据视为异常值:
abnormal <- function(x) {
fn <- fivenum(x);
Q1 <- fn[2]; Q3 <- fn[4];
R1 <- Q3 - Q1
QD <- Q1 - 1.5 * R1
QU <- Q3 + 1.5 * R1
x[(x < QD) | (x > QU)]
}
apply(data[-1], 2, abnormal)
# 若结果为空则没有异常值
数据分布图
茎叶图
stem(Nationwide)

直方图
最简单的是直接用 hist(x),但我们可以画的好看一点。
封装:
histogram <- function(x, xname="x") {
hist(x, prob=TRUE, main=paste("Histogram of" , xname))
lines(density(x))
rug(x) # show the actual data points
}
调用:
histogram(X1, "X1")
结果:
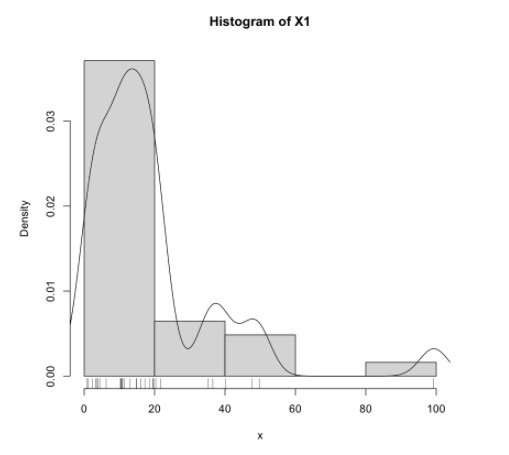
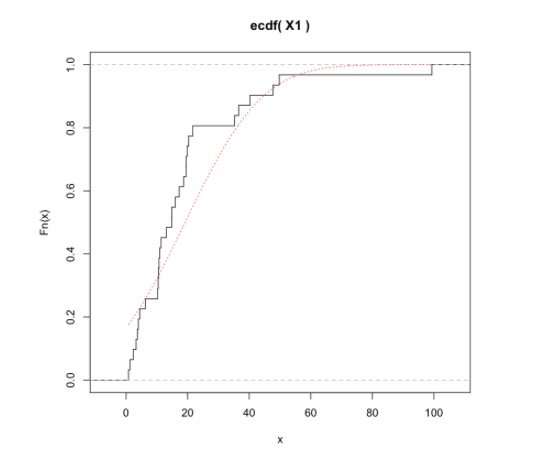
经验分布函数图
封装:
plot_ecdf <- function(x, xname="x") {
plot(ecdf(x), do.points=FALSE, verticals=TRUE, main=paste("ecdf(" , xname, ")"))
xs <- seq(min(x), max(x), 1/sqrt(length(x)))
lines(xs, pnorm(xs, mean=mean(x), sd=sd(x)), lty=3, col="red")
}
注意 xs 这里我选择用 1 n \frac{1}{\sqrt{n}} n1 的密度,这个值比较适合我的数据(画出来不过稀也不太密),这个可以随便改。
调用:
plot_ecdf(X1, "X1")
结果:
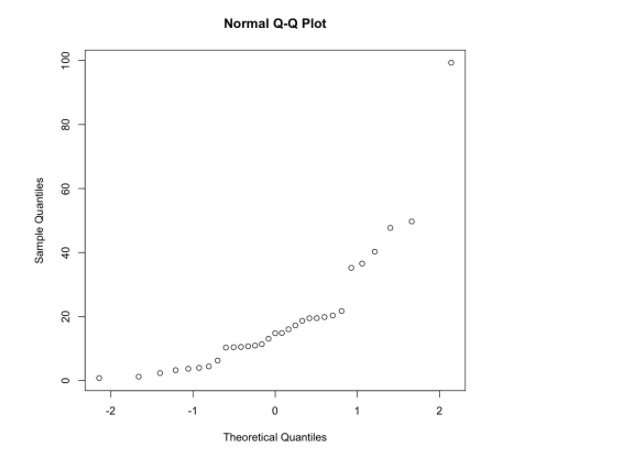
正态 Q-Q 图
qqnorm(X1)
Pearson 与 Spearman 相关系数
Pearson 相关系数
二维总体: ( X , Y ) T (X,Y)^T (X,Y)T
观测数据: ( x 1 , y 1 ) T , ( x 2 , y 2 ) T , ⋯ , ( x n , y n ) T (x_1,y_1)^T,(x_2,y_2)^T,\cdots,(x_n,y_n)^T (x1,y1)T,(x2,y2)T,⋯,(xn,yn)T
记: x ‾ = 1 n ∑ i = 1 n x i , y ‾ = 1 n ∑ i = 1 n y i \overline x=\frac{1}{n}\sum_{i=1}^nx_i,\quad \overline y=\frac{1}{n}\sum_{i=1}^ny_i x=n1∑i=1nxi,y=n1∑i=1nyi
则 X , Y X, Y X,Y 的观测数据的方差:
s x x = 1 n − 1 ∑ i = 1 n ( x i − x ‾ ) 2 s y y = 1 n − 1 ∑ i = 1 n ( y i − y ‾ ) 2 s_{xx}=\frac{1}{n-1}\sum_{i=1}^n(x_i-\overline x)^2 \quad s_{yy}=\frac{1}{n-1}\sum_{i=1}^n(y_i-\overline y)^2 sxx=n−11i=1∑n(xi−x)2syy=n−11i=1∑n(yi−y)2
X , Y X,Y X,Y 的观测数据的协方差:
s x y = 1 n − 1 ∑ i = 1 n ( x i − x ‾ ) 2 ( y i − y ‾ ) 2 s_{xy}=\frac{1}{n-1}\sum_{i=1}^n(x_i-\overline x)^2(y_i-\overline y)^2 sxy=n−11i=1∑n(xi−x)2(yi−y)2
(注:协方差矩阵 S = [ s x x s x y s y x s y y ] S=\left[\begin{matrix}s_{xx} & s_{xy} \\ s_{yx} & s_{yy}\end{matrix}\right] S=[sxxsyxsxysyy],其中 s y x = s x y s_{yx}=s_{xy} syx=sxy)
Pearson 相关系数:
r x y = s x y s x x s y y r_{xy}=\frac{s_{xy}}{\sqrt{s_{xx}}\sqrt{s_{yy}}} rxy=sxxsyysxy
这个值 ∣ r x y ∣ ≤ 1 |r_{xy}|\le1 ∣rxy∣≤1,衡量 X 和 Y 的线性相关程度:
- r x y → 1 r_{xy}\rightarrow 1 rxy→1 正相关
- r x y → 0 r_{xy}\rightarrow 0 rxy→0 不线性相关
- r x y → − 1 r_{xy}\rightarrow -1 rxy→−1 负相关
用 R 来算相关系数,用 cor(x, y, method="pearson") 这个函数会直接求出 r x y r_{xy} rxy 值。也可以用下面这个函数,会输出更多的信息:
cor.test(X1, X2, method="pearson")
输出:( cor = r x y \textrm{cor}=r_{xy} cor=rxy)

【Math Time】关于上面输出的假设检验:
设二维总体 ( X , Y ) T (X,Y)^T (X,Y)T 的分布函数为 F ( x , y ) F(x,y) F(x,y)
总体的相关系数 ρ X Y = C o v ( X , Y ) V a r ( X ) V a r ( Y ) \rho_{_{XY}}=\frac{\mathrm{Cov}(X,Y)}{\sqrt{\mathrm{Var}(X)}\sqrt{\mathrm{Var}(Y)}} ρXY=Var(X)Var(Y)Cov(X,Y)
n n n 充分大时,有 ρ X Y ≈ r x y \rho_{_{XY}} \approx r_{xy} ρXY≈rxy
现在的问题是:
- 对任意观测数据总可以求到 r x y r_{xy} rxy,而且求出来一般不为0
- 而如果总体的 X X X、 Y Y Y 是不相关的( ρ X Y = 0 \rho_{XY}=0 ρXY=0):这时用 r x y r_{xy} rxy 来度量 X X X、 Y Y Y 的关联性就没有意义了。
所以要做个假设检验:
H 0 : ρ X Y = 0 ↔ H 1 : ρ X Y ≠ 0 H_0:\rho_{_{XY}}=0 \quad \leftrightarrow \quad H_1:\rho_{_{XY}}\ne0 H0:ρXY=0↔H1:ρXY=0
若总体时二维正态的,则 H 0 H_0 H0 为真时,统计量
t = T x y n − 2 1 − r x y 2 ∼ t ( n − 2 ) t=\frac{T_{xy}\sqrt{n-2}}{\sqrt{1-r_{xy}^2}} \sim t(n-2) t=1−rxy2Txyn−2∼t(n−2)
将观测数据算得的 t t t 值记为 t 0 t_0 t0 则检验 p p p 值:
p = P H 0 ( ∣ t ∣ > ∣ t 0 ∣ ) = P ( ∣ t ( n − 2 ) ∣ ≥ ∣ t 0 ∣ ) p=P_{H_0}(|t|>|t_0|)=P(|t(n-2)|\ge|t_0|) p=PH0(∣t∣>∣t0∣)=P(∣t(n−2)∣≥∣t0∣)
给定显著水平 α \alpha α , p < α p<\alpha p<α 时拒绝 H 0 H_0 H0,认为 X , Y X,Y X,Y 相关,可以用 r x y r_{xy} rxy 衡量相关程度。
Spearman 相关系数
Spearman 是秩相关系数。
样本秩:把观测值 x 1 , x 2 , ⋯ , x n x_1,x_2,\cdots,x_n x1,x2,⋯,xn 从小到大排序, x i x_i xi 排在第几个则其秩 R i R_i Ri 就是多少。
e.g.
x i : 7 − 3 − 1 5 R i : 4 1 2 3 \begin{array}{r} x_i: & 7 & -3 & -1 & 5 \\ R_i: & 4 & 1 & 2 & 3 \end{array} xi:Ri:74−31−1253
记:
- x 1 , x 2 , ⋯ , x n x_1,x_2,\cdots,x_n x1,x2,⋯,xn 的秩分别为: R 1 , R 2 , ⋯ , R n R_1,R_2,\cdots,R_n R1,R2,⋯,Rn
- R ‾ = 1 n ∑ i = 1 n R i = 1 n ∑ i = 1 n i = n + 1 2 \overline R=\frac{1}{n}\sum_{i=1}^nR_i=\frac{1}{n}\sum_{i=1}^n i=\frac{n+1}{2} R=n1∑i=1nRi=n1∑i=1ni=2n+1
- y 1 , y 2 , ⋯ , y n y_1,y_2,\cdots,y_n y1,y2,⋯,yn 的秩分别为: S 1 , S 2 , ⋯ , S n S_1,S_2,\cdots,S_n S1,S2,⋯,Sn
- S ‾ = 1 n ∑ i = 1 n S i = n + 1 2 \overline S=\frac{1}{n}\sum_{i=1}^nS_i=\frac{n+1}{2} S=n1∑i=1nSi=2n+1
则定义 Spearman 相关系数:
q x y = ∑ i = 1 n ( R i − R ‾ ) ( S i − S ‾ ) ∑ i = 1 n ( R i − R ‾ ) 2 ∑ i = 1 n ( S i − S ‾ ) 2 \begin{array}{l} q_{xy} &=& \frac{\sum_{i=1}^n(R_i-\overline R)(S_i-\overline S)}{\sqrt{\sum_{i=1}^n(R_i-\overline R)^2}\sqrt{\sum_{i=1}^n(S_i-\overline S)^2}} \end{array} qxy=∑i=1n(Ri−R)2∑i=1n(Si−S)2∑i=1n(Ri−R)(Si−S)
用 R 来计算(输出里 rho = q x y \textrm{rho}=q_{xy} rho=qxy):
cor.test(X1, X2, method="spearman")

还是一样的,有一个假设检验:
H 0 : ρ X Y = 0 ↔ H 1 : ρ X Y ≠ 0 H_0:\rho_{_{XY}}=0 \quad \leftrightarrow \quad H_1:\rho_{_{XY}}\ne0 H0:ρXY=0↔H1:ρXY=0
【EOF】
暂时就这些了。最近忙,后面如果有时间可能还会写回归分析、方差分析…这些完整一套的。
CDFMLR 2021.06.07
【P.S. 2021.07.15】 真的没时间写啊,感觉又是未完不必待续了。
(如果有人想看后续可以吱一声)
其实如果需要的话,整本数据分析的各种代码基本在 github.com/cdfmlr/daex 里都有写,可以参考一下。