
Lapply返回一个列表, 并无视输入变量的类型。
x <-list(a = 1:5, b = rnorm(10))
lapply(x, mean)
## $a
## [1] 3
##
## $b
## [1] 0.4671
Sapply 简化lapply函数返回的结果。
若结果是一个list,且每个元素长度为1,则会返回一个向量
若结果是一个list,且每个元素长度为大于1,则会返回一个矩阵
若其他复杂的结果,会返回一个向量
apply 函数,应用某函数到一个数组上
此函数经常被用于对矩阵的行或列进行指定目的的循环
可以被用于多个数组的循环
该函数作用于一行进行循环
> str(apply)
function (X, MARGIN, FUN, ...)
X 是一个数组
MARGIN 参数是一个数字向量,在适用与矩阵时,1表示行,2表示列,也可以是列名
FUN 是适用循环的函数
... 表示其他参数
求解行列的和或平均值时,可以由以下函数确定
rowSums= apply(x, 1, sum)
rowMeans= apply(x, 1, mean)
colSums= apply(x, 2, sum)
colMeans= apply(x, 2, mean)
tapply适用于数据框的一个连续变量做分组描述统计。
> str(tapply)
function (X, INDEX, FUN = NULL, ..., simplify = TRUE)
X 是一个向量
INDEX 是一个因子类型的列表(或强制转换为因子列表)
FUN 表示待循环的函数
simplify简化返回结果
split 用于使某向量或对象分为指定数目的组,指定数目的组由因子列表确定
> str(split)
function (x, f, drop = FALSE, ...)
X是一个向量或数据框
F是一个因子或因子列表
Drop表示空因子水平是否舍弃
图形展示三步
第一步 明确你要表达的信息
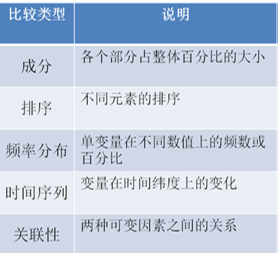
第二步 确定相对关系
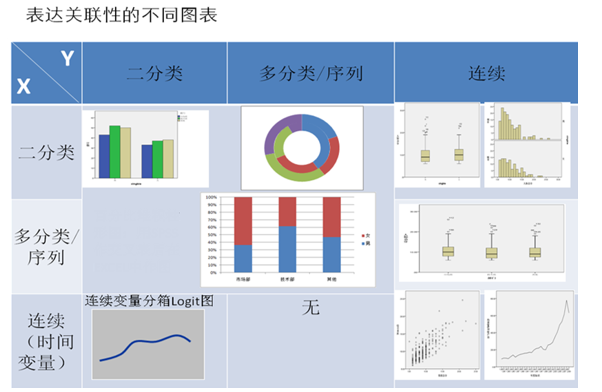
第三步 选择图表形式


统计图属于描述性统计,是对统计汇总表的形象性展示。EXCEL虽然提供了比R更多的图表功能。但是严格来说,EXCEL并不能直接做出统计图,它需要在个体记录原始数据的基础之上进行统计汇总,然后根据汇总数据进行作图。而R的作图功能是直接基于个体记录的原始数据进行绘图。
每类统计图是为了满足特定叙述目的而出现的,其类似于语言,有其明确的定义与叙述方式。复杂叙述目的的实现是通过综合运用每类统计图,而不是创造出复杂的图。好的统计图可以使阅读者在仅阅读标题关键字和图形时,不用注意任何坐标轴标题、刻度和附注的情况下顺利地理解需要表达的意义。
统计图分为描述性统计图和检验统计图,前者是对某些变量分布、趋势的描述,大量出现在工作报告中和统计报告中,比如饼图、条图。后者是对特定统计检验和统计量的形象展示,仅出现在特定统计报告中,一般不在工作报告中出现,比如直方图和箱形图,P-P图,ROC曲线。不过这个界限有些模糊,比如箱线图一开始是统计图,但后来人们觉得其表现连续函数和分类变量的关系时很直观,所以也被广泛用于工作报告中。
饼图—反映成分占比
#使用灰度
pie(table(accepts$bankruptcy_ind), col = gray(seq(0.5,1.0,length=3)))
#自定义颜色
pie(table(accepts$bankruptcy_ind), col = c("Green", "blue", "black"))
#使用预定义的彩虹色
pie(table(accepts$bankruptcy_ind), col = rainbow(3))
直方图—连续单变量的分布
x=accepts$fico_score
hist(x, freq = F,main="fico_score",
sub ="source:汽车贷款数据", xlab="fico_score打分",
ylab="频数",nclass=20)
使用Hist()函数生成这些点的直方图,这里通过main参数设置主标题
Sub=参数,指定直方图的下标题,例中为“Subtitle”
Xlab=参数,指定直方图x轴的标题,例中为“Values for X”
Ylab=参数,指定直方图y轴的标题,例中为“Values for Y”
Legend函数用于在图表指定位置生成图例
盒须图/箱形图—连续单变量的分布
盒须图能够提供某变量分布以及异常值的信息,其通过分位数来概括某变量的分布信息从而比较不同变量的分布。盒须图的基本元素包括:
IQR:变量上下四分位数之间的数据,这个范围代表了数据中间50%的数据。
中位数位置:中位数位置即代表变量中位数在总体分布中的位置。
1.5IQR:上下1.5IQR表示上下1.5倍IQR范围的数据,其能够提供中位数左右95%的置信区间的数据。可以直观的从盒须图中看出超出95%置信区间范围的数据,即异常值。
不同变量的盒须图比较时,可以通过中位数位置来比较两变量数据的中位数差异状况。

简单散点图—两个连续变量之间的关系描述
plot(x=x,y=y,type="p")#散点图
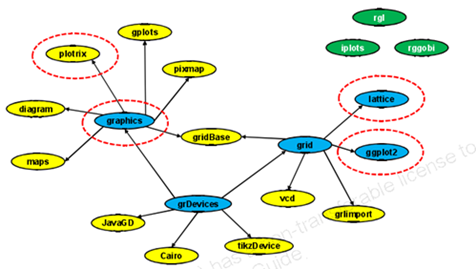
R制图系统有五种核心的包,即上图中蓝色椭圆,黄色椭圆代表核心包的拓展。一些包有它自己的制图系统,这些为绿色椭圆。