使用深度学习的超分辨率介绍
关于使用深度学习进行超分辨率的各种组件,损失函数和度量的详细讨论。
介绍
超分辨率是从给定的低分辨率(LR)图像恢复高分辨率(HR)图像的过程。由于较小的空间分辨率(即尺寸)或由于退化的结果(例如模糊),图像可能具有“较低分辨率”。我们可以通过以下等式将HR和LR图像联系起来:LR = degradation(HR)

显然,在应用降级函数时,我们从HR图像获得LR图像。但是,我们可以反过来吗?在理想的情况下,是的!如果我们知道确切的降级函数,通过将其逆应用于LR图像,我们可以恢复HR图像。
但是,存在问题。我们通常不知道降解功能。直接估计逆退化函数是一个不适定的问题。尽管如此,深度学习技术已证明对超分辨率有效。
本博客主要介绍如何使用有监督的培训方法,使用深度学习来执行超分辨率。还讨论了一些重要的损失函数和度量。许多内容来源于读者可以参考的文献综述。
监督方法
如前所述,深度学习可用于在给定低分辨率(LR)图像的情况下估计高分辨率(HR)图像。通过使用HR图像作为目标(或地面实况)和LR图像作为输入,我们可以将其视为监督学习问题。
在本节中,我们以卷积层的组织方式对各种深度学习方法进行分组。在我们进入这些小组之前,我们将介绍数据准备和卷积类型。用于优化模型的损失函数在本博客的末尾单独列出。
准备数据
获得LR数据的一种简单方法是降低HR数据。这通常通过模糊或添加噪声来完成。较低空间分辨率的图像也可以通过诸如双线性或双立方插值的经典上采样方法来缩放。还可以引入JPEG和量化伪像来降低图像质量。


需要注意的一点是,建议将HR映像存储为未压缩(或无损压缩)格式。这是为了防止由于有损压缩导致的HR图像质量的下降,这可能给出次优性能。
卷积的类型
除了经典的2D Convolutions之外,还可以在网络中使用几种有趣的变体来改善结果。膨胀(Atrous)卷绕可以提供更有效的视野,因此使用大距离分开的信息。跳过连接,空间金字塔池和密集块激发了低级和高级功能的结合,以提高性能。
 (
来源
)
(
来源
)
上图提到了许多网络设计策略。您可以参考本文以获取更多信息。有关深度学习中常用的不同类型卷积的入门读物,您可以参考此博客。
第1组 - 预上采样
在该方法中,首先内插低分辨率图像以获得“粗略”高分辨率图像。现在,CNN用于学习从插值的低分辨率图像到高分辨率图像的端到端映射。直觉是,使用传统方法(例如双线性插值)首先对低分辨率图像进行上采样可能更容易,然后细化结果,而不是学习从低维空间到高维空间的直接映射。
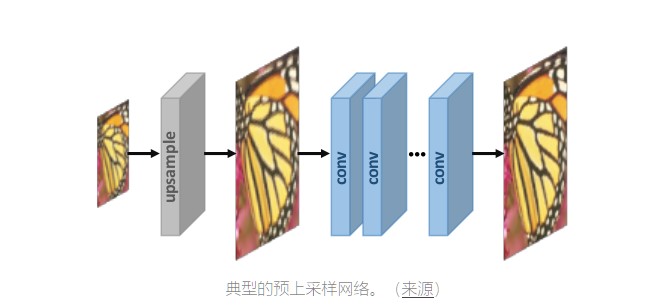
对于使用此技术的某些型号,您可以参考本文的第5页。优点在于,由于上采样是通过传统方法处理的,因此CNN仅需要学习如何细化粗略图像,这更简单。此外,由于我们在这里没有使用转置卷积,因此可能会绕过棋盘格。然而,缺点是预定义的上采样方法可能放大噪声并导致模糊。
第2组 - 后上采样
在这种情况下,低分辨率图像被传递到CNN。使用可学习层在最后一层执行上采样。
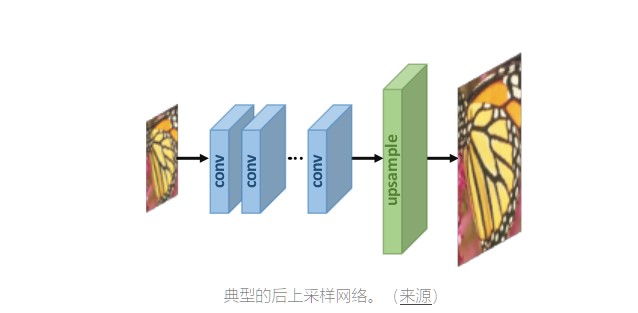
该方法的优点在于在较低维空间中(在上采样之前)执行特征提取,因此降低了计算复杂度。此外,通过使用可学习的上采样层,可以端到端地训练模型。
第3组 - 逐步上采样
在上述组中,即使计算复杂度降低,也只使用单个上采样卷积。这使得大型缩放因子的学习过程更加困难。为了解决这个缺点,拉普拉斯金字塔SR网络(LapSRN)和Progressive SR(ProSR)等工作采用了渐进式上采样框架。在这种情况下的模型使用级联的CNN以在每个步骤以较小的缩放因子逐步重建高分辨率图像。
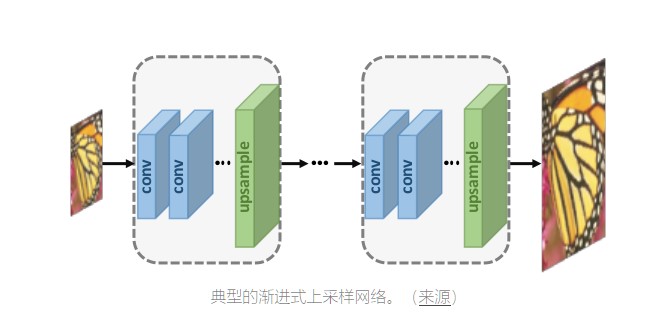
通过将困难的任务分解为更简单的任务,大大降低了学习难度并且可以获得更好的性能。此外,可以整合课程学习等学习策略,进一步降低学习难度,提高最终表现。
第4组 - 迭代上下采样
另一种流行的模型架构是沙漏(或U-Net)结构。诸如Stacked Hourglass网络之类的一些变体使用串联的几个沙漏结构,在上采样和下采样的过程之间有效地交替。

该框架下的模型可以更好地挖掘LR-HR图像对之间的深层关系,从而提供更高质量的重建结果。
损失函数
损失函数用于测量生成的高分辨率图像和地面实况高分辨率图像之间的差异。然后使用该差异(误差)来优化监督学习模型。存在几类损失函数,其中每种损失函数都惩罚所生成图像的不同方面。
通常,通过加权和总结从每个损失函数单独获得的误差来使用多于一个的损失函数。这使模型能够同时关注由多个损失函数贡献的方面。
total_loss = weight_1 * loss_1 + weight_ 2 * loss_2 + weight_3 * loss_3
在本节中,我们将探讨用于训练模型的一些流行的损失函数类。
像素丢失
像素损失是最简单的一类损失函数,其中生成的图像中的每个像素直接与地面实况图像中的每个像素进行比较。使用诸如L1或L2损耗之类的流行损失函数或诸如Smooth L1损失之类的高级变体。
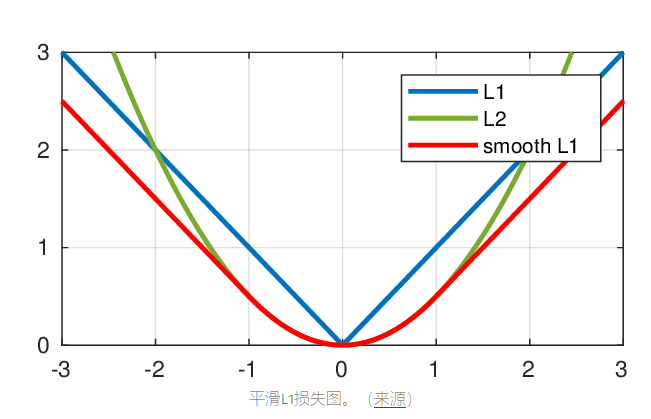
PSNR度量(下面讨论)与像素差异高度相关,因此最小化像素损失直接最大化PSNR度量值(指示良好性能)。然而,像素损失没有考虑图像质量,并且模型经常输出感知上不令人满意的结果(通常缺少高频细节)。
内容丢失
该损失基于其感知质量评估图像质量。一种有趣的方法是通过比较生成图像的高级特征和地面实况图像。我们可以通过预先训练的图像分类网络(例如VGG-Net或ResNet)传递这些图像来获得这些高级特征。

上面的等式计算地面实况图像和生成的图像之间的内容损失,给定预训练网络(Φ)和该预训练网络的层(1),在该层处计算损耗。这种损失促使生成的图像在感知上与地面实况图像相似。因此,它也被称为感知损失。
纹理损失
为了使生成的图像具有与地面实况图像相同的样式(纹理,颜色,对比度等),使用纹理损失(或样式重建损失)。Gatys等人描述的图像纹理。al,被定义为不同特征通道之间的相关性。特征通道通常从使用预训练的图像分类网络(Φ)提取的特征图获得。
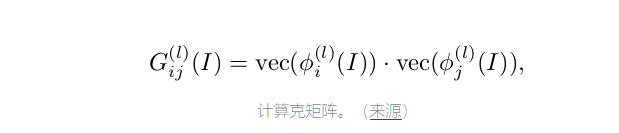
特征图之间的相关性由Gram矩阵(G)表示,Gm矩阵是矢量化特征图i和j图层之间的内积l (如上所示)。一旦计算了两个图像的Gram矩阵,计算纹理损失是直截了当的,如下所示:

通过使用这种损失,模型被激励创建逼真的纹理和视觉上更令人满意的结果。
总变异损失
总变差(TV)损耗用于抑制生成的图像中的噪声。它取相邻像素之间的绝对差值之和,并测量图像中的噪声量。对于生成的图像,电视丢失计算如下:

这里,分别i,j,k迭代高度,宽度和通道。
对抗性损失
生成性对抗网络(GAN)已越来越多地用于包括超分辨率在内的多种基于图像的应用。GAN通常由两个神经网络系统组成 - 发电机和鉴别器 - 相互决斗。
给定一组目标样本,Generator会尝试生成可以欺骗Discriminator的样本,使其相信它们是真实的。鉴别器尝试从假(生成)样本中解析实际(目标)样本。使用这种迭代训练方法,我们最终得到一个真正擅长生成类似于目标样本的样本的Generator。下图显示了典型GAN的结构。

引入了基本GAN架构的进步以提高性能。例如,Park et。al。使用特征级鉴别器来捕获真实高分辨率图像的更有意义的潜在属性。您可以查看此博客,以获得有关GAN进展的更详细的调查。
通常情况下,训练有对抗性损失的模型具有更好的感知质量,即使他们可能会因为像素丢失训练而失去PSNR。一个小的缺点是,GAN的训练过程有点困难和不稳定。然而,积极研究稳定GAN训练的方法。
度量
一个重要问题是我们如何定量评估模型的性能。许多图像质量评估(IQA)技术(或度量)用于相同的。这些指标可大致分为两类 - 主观指标和客观指标。
主观指标基于人类观察者的感知评估,而客观指标基于试图评估图像质量的计算模型。主观指标通常更“感知准确”,但是这些指标中的一些不方便,耗时或昂贵。另一个问题是这两类指标可能彼此不一致。因此,研究人员经常使用两个类别的指标显示结果。
在本节中,我们将简要探讨一些广泛使用的度量标准,以评估我们的超分辨率模型的性能。
PSNR
峰值信噪比(PSNR)是常用的客观度量,用于测量有损变换的重建质量。PSNR与地面实况图像和生成的图像之间的均方误差(MSE)的对数成反比。
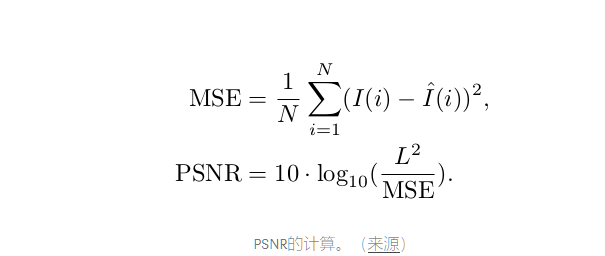
在上面的公式中,L是最大可能像素值(对于8位RGB图像,它是255)。不出所料,由于PSNR只关心像素值之间的差异,因此它并不能很好地代表感知质量。
SSIM
结构相似性(SSIM)是用于基于三个相对独立的比较(即亮度,对比度和结构)来测量图像之间的结构相似性的主观度量。摘要,SSIM公式可以作为独立计算的亮度,对比度和结构比较的加权乘积。
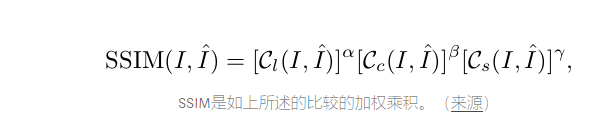
在上面的公式中,α,β和γ分别是亮度,对比度和结构比较函数的权重。SSIM公式的常用表示如下所示:
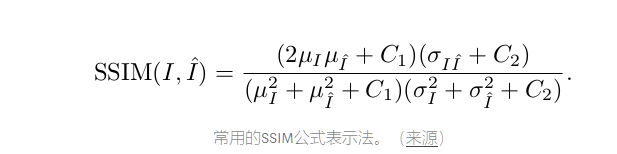
在上面的公式中μ(I)表示特定图像的平均值,σ(I) 表示特定图像的标准偏差,σ(I,I’)表示两个图像之间的协方差,并且C1, C2是为避免不稳定而设置的常数。为简洁起见,本博客中未解释术语的重要性和确切的推导,感兴趣的读者可以查看本文第2.3.2节。
由于图像统计特征或失真可能分布不均匀,因此在本地评估图像质量比在全球范围内应用图像质量更可靠。将图像分成多个窗口并平均在每个窗口获得的SSIM的平均SSIM(MSSIM)是一种在本地评估质量的方法。
无论如何,由于SSIM从人类视觉系统的角度评估重建质量,它更好地满足了感知评估的要求。
其他IQA分数
没有解释,下面列出了评估图像质量的一些其他方法。感兴趣的读者可以参考本文了解更多细节。
- 平均意见得分(MOS)
- 基于任务的评估
- 信息保真标准(IFC)
- 视觉信息保真度(VIF)
结论
这篇博客文章介绍了培训超分辨率深度学习模型的一些介绍性材料和程序。确实有更先进的技术引入了最先进的技术,可以产生更好的性能。此外,研究诸如无监督超分辨率,更好的归一化技术和更好的代表性指标等途径可以大大推动这一领域。鼓励感兴趣的读者通过参与PIRM挑战等挑战来试验他们的创新想法。