2.1 词汇表征(Word Representation)
用one-hot表示,使得每一个词都是独立没有联系的,两个向量相乘都是0,不能获取词与词之间的关联相似性。

解决办法 特征表征:词嵌入
利用不同的特征来对各个词汇进行表征,这样产生的向量使得词之间的相似性很好的表现出来,算法的泛化性也更好。
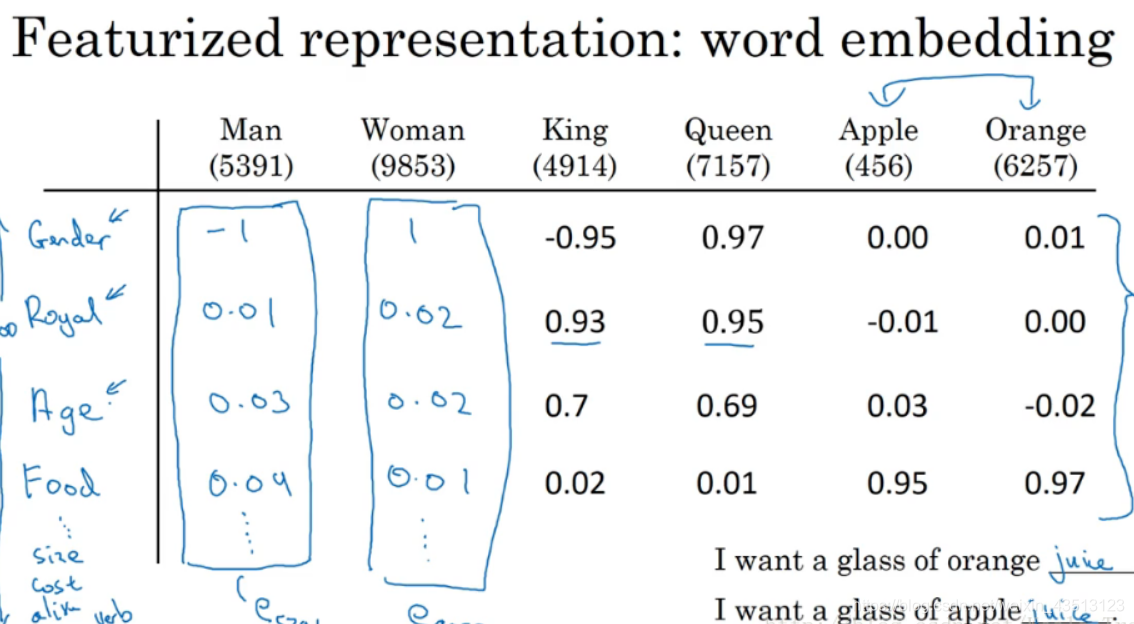
t-SNE算法将高维的词向量映射到2维空间(这个过程被称为嵌入embeddings),对词向量进行可视化,可视化后看见相似的词都聚集到一起。这些就是相似的特征向量。
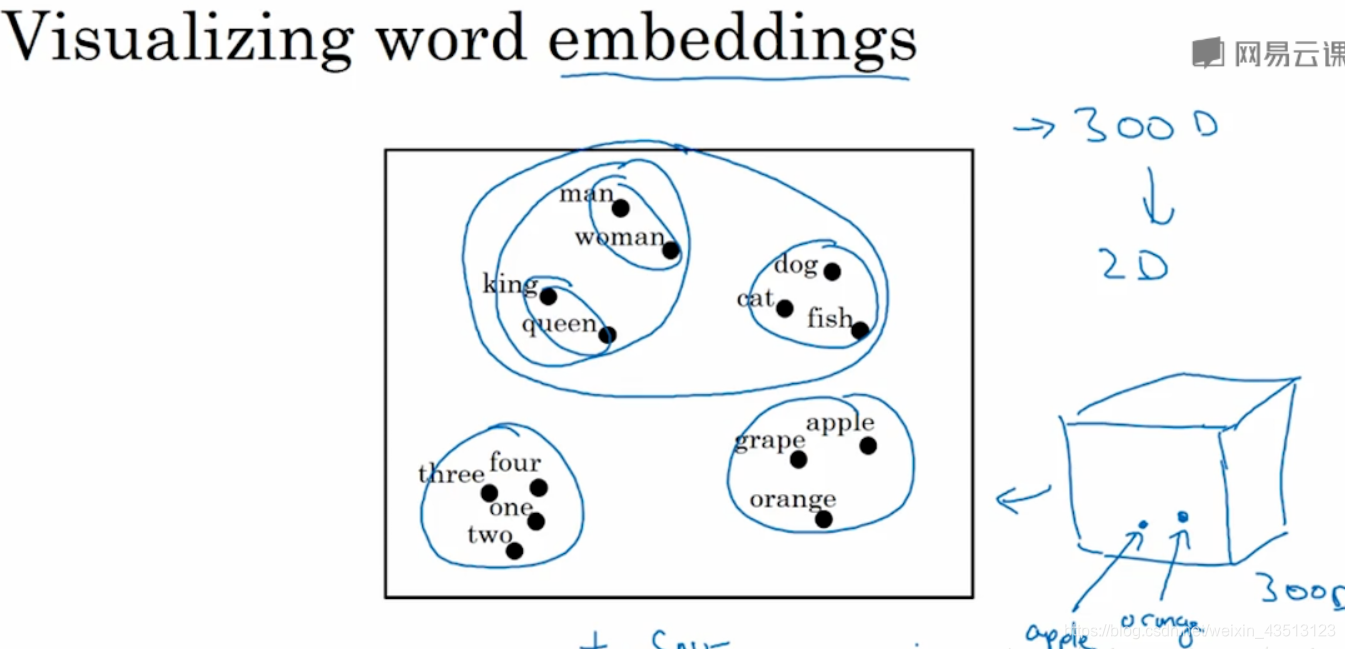
2.2 使用词嵌入(Using Word Embeddings)
假如我们有一个比较小的数据集,那么要训练时就需要用到迁移学习。
用词嵌入做迁移学习:
- 从一个非常大的文本集中学习词嵌入或者下载预训练好的词嵌入模型
- 用这些模型迁移到只有少量标注训练集的任务中
- 可选择操作:是否继续用新数据词嵌入微调模型
人脸识别:将任意一个没有见过的人脸照片输入到我们构建的网络中,则可输出一个对应的人脸编码。
词嵌入:所有词汇的编码是在一个固定的词汇表中进行学习单词的编码以及其之间的关系。
2.3 词嵌入的特性(Properties of Word Embeddings)
词嵌入还有一个重要的特性,类比推理。通过不同词向量之间的相减计算,可以发现不同词之间的类比关系,例如man——woman、king——queen。

计算词与词之间的相似度,实际上是在多维空间中,寻找词向量之间各个维度的距离相似度。

例如
那么相当于求两个向量之间的最最相似度
相似度函数

- 余弦相似度函数
- 欧氏距离
2.4 嵌入矩阵(Embedding Matrix)
当应用算法来让词汇表学习嵌入词时,实质上就是要学习这个词汇表对应的一个嵌入矩阵E。当我们学习好了这样一个嵌入矩阵后,通过嵌入矩阵与对应词的one-hot向量相乘,则可得到该词汇的embedding。
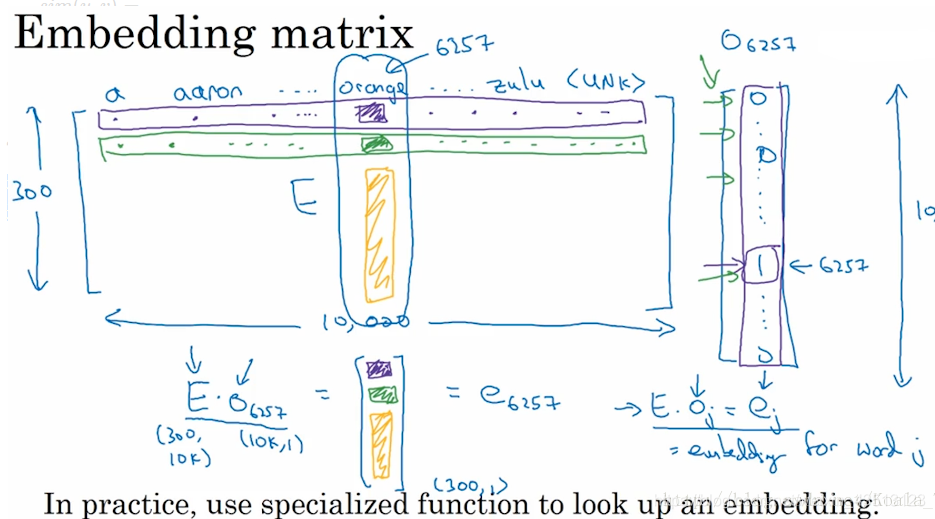
手动实现时,用嵌入矩阵与对应词的one-hot向量相乘效率低下,所以实践中会用专门的函数来单独查找矩阵E的某列。