微博爬取要做到每日百万级的数据量,需要解决很多问题。
1.springboot自带@Scheduled注解是一个轻量级的quartz,可以完成定时任务。只需要在运行方法上加一个@Scheduled注解即可。
该注解有许多属性值
initiaDelay 从程序开始延长一定时间后首次执行。
fixedRate 首次后,该方法固定执行间隔。
cron 定时表达式。
等等
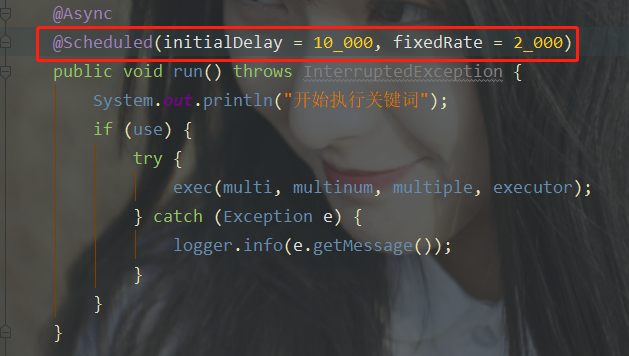
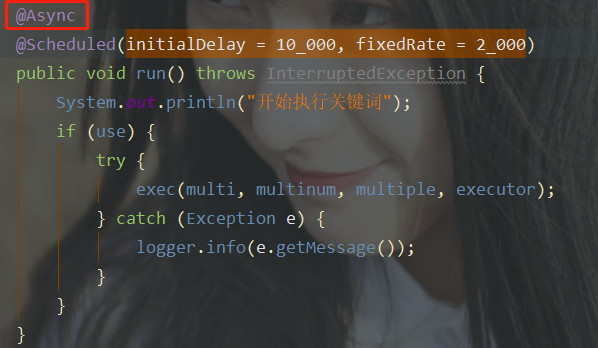
如果想要并发编程,在要执行定时任务的类上加注解@EnableAsync,在方法上加@Async。

接下来要设置线程池的大小。
package com.cnxunao.weibospider.configuration; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.scheduling.annotation.EnableScheduling; import org.springframework.scheduling.annotation.SchedulingConfigurer; import org.springframework.scheduling.config.ScheduledTaskRegistrar; import java.util.concurrent.Executor; import java.util.concurrent.Executors; @Configuration @EnableScheduling public class ScheduleConfig implements SchedulingConfigurer { @Override public void configureTasks(ScheduledTaskRegistrar taskRegistrar) { taskRegistrar.setScheduler(taskExecutor()); } /* * 并行执行 */ @Bean(name = "TaskPool") public Executor taskExecutor() { return Executors.newScheduledThreadPool(5); } }
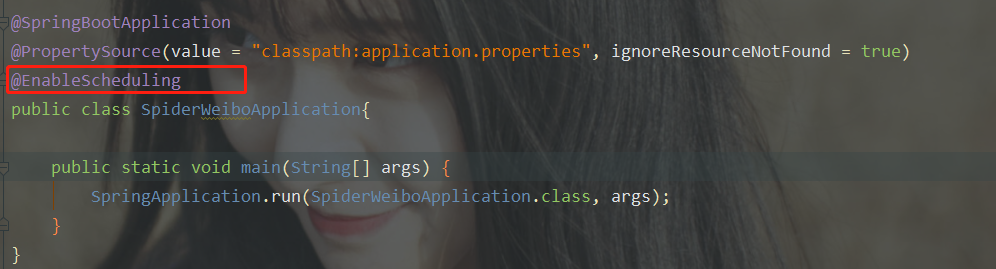
最后在启动类上加一个注解
2.微博的反爬机制还是蛮严格的,亲自试验让代理服务器每6秒爬取一次是很稳定的,不会被封。
也可以建立一个user_agent池用于反爬。(都是亲测可用的)
//user_Agent池 private static String[] userAgents = { "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.89 Safari/537.36", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50", "Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.9.168 Version/11.50", "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 2.0.50727; SLCC2; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; Tablet PC 2.0; .NET4.0E)", "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)", "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; GTB7.0)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)", "Mozilla/5.0 (Windows; U; Windows NT 6.1; ) AppleWebKit/534.12 (KHTML, like Gecko) Maxthon/3.0 Safari/534.12", "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.3 (KHTML, like Gecko) Chrome/6.0.472.33 Safari/534.3 SE 2.X MetaSr 1.0", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.41 Safari/535.1 QQBrowser/6.9.11079.201", "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)" }; //随机获取总数为14useragent池中的一个 private String userAgent = userAgents[random.nextInt(14)];
注:随机获取1-13的整数 random.nextInt(13)+1 。13位容量,1位初始值。
还可以采用购买大量微博账号(很便宜)模拟登陆后,获取cookie,然后构建cookie池的方法。
3.购买代理ip的话,需要调用商家的API来获取代理,具体方法商家官网都有开发者文档,代码有些简单这里就不发出来了。
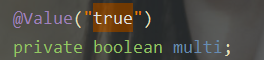
如果使用springboot的话,自定义配置可以使用@Value来进行赋值。
 application.properties
application.properties
 java文件
java文件
 自动填充效果
自动填充效果
4.java程序运行时间长后会变慢,可以利用一些设计模式来解决性能的问题,合理使用虚拟机内存空间,即使删除不用的对象。我也是边学边做,现在还没有完全解决,之后会更新。
5.并发程序有时会造成读写数据的错乱问题,需要了解一些并发编程的规范。还有一种办法,把需要共享的数据放在redis里,来解决这类问题。
6.如果你觉得微博关键字的爬取只能爬取首页太少,可以在模拟登录后保存cookie进行爬取,可以爬到所有的相关页面。
7.编程中日志是很重要的,是反应情况,分析问题,解决问题的关键,一定要在适当的程序位置加一些日志信息。下图是我写日志的一种方法。

