在网上稍微看了一下,好像还没有爬取微博热搜的java实例,心血来潮就动手写一个简易版的,之后会不会升级再说。
首先我们点开微博热搜榜电脑版,然后查看源码。
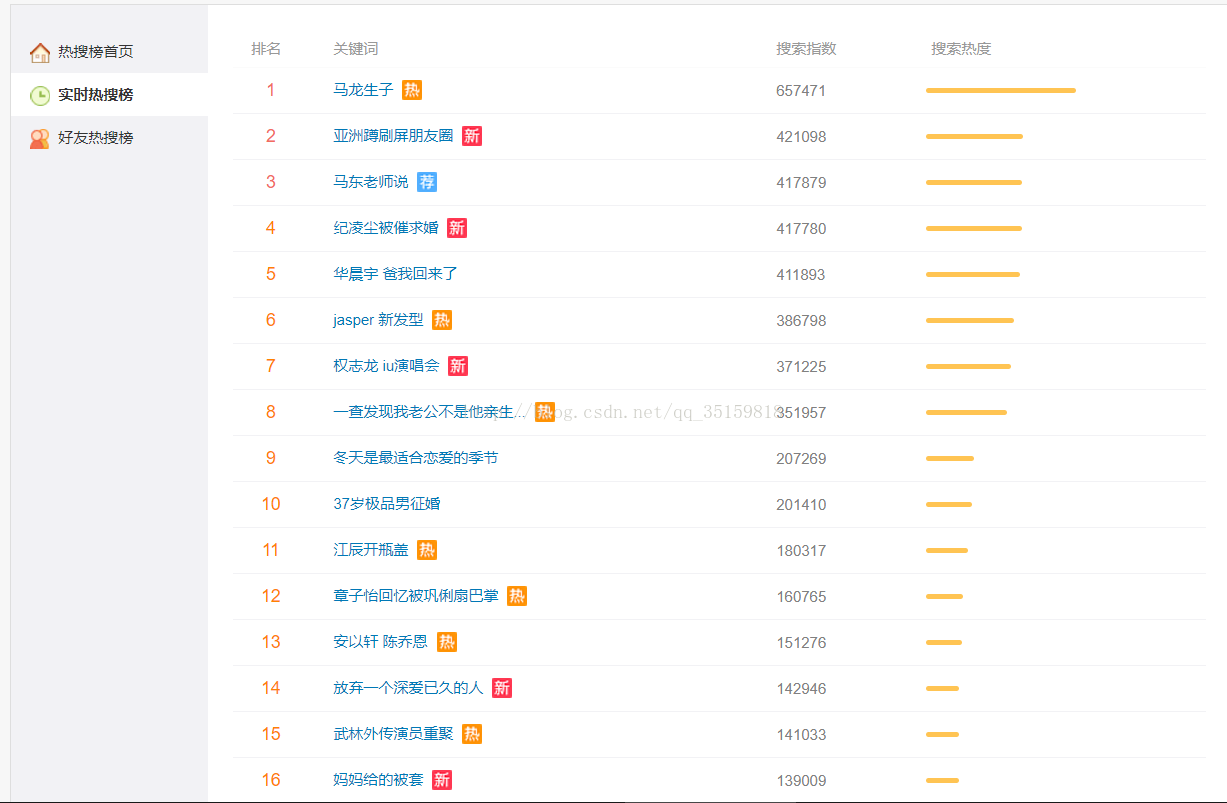

我们可以看到body的构成很简单,几乎没有什么东西,再往下滑就不得了了,没错,意料之中有很多script
就算不看源码我们分析也可以知道这应该是一个js动态页面,因为我们一点进去,里面都是实时的数据。
然后我们fidder抓下数据。
发现了一个比较有趣的数据包
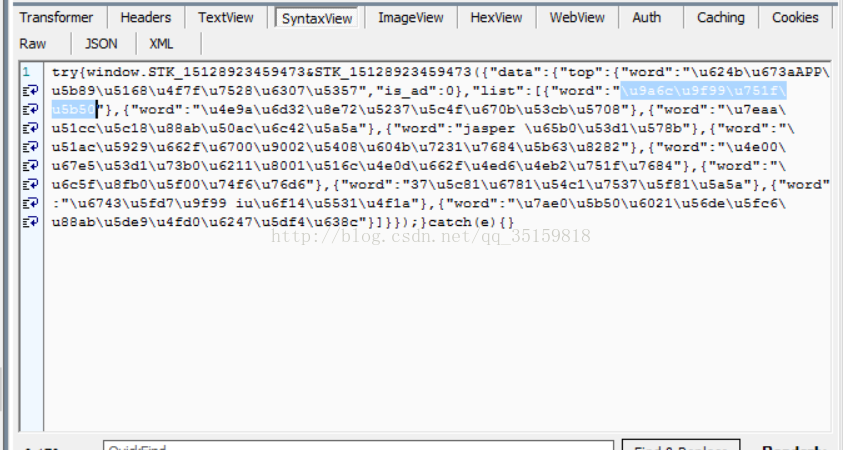
这些word=“xxxx” 里面的xxx又是什么呢,很明显是中文的URL编码。
取第一项写串代码转换成中文一下
可以看到转成了这玩意
很明显刚刚的推测是对的。
值得一题的是刚刚抓到的包,有个项居然特意标注了下is_ad...
个人猜测可能是广告热搜,估计要被新浪锤了

好了,我们知道了这些热搜标题的规则再回头来看看网页的源代码。这时候看就会清楚很多了。
我们看看这一片七七八八的script
马上就发现了其中很有意思的一个项,为什么说他有趣呢
因为它很长- -。
不过这当然还不够,很容易看出它包含了一张表格,并且有50行,很明显就是对应50项的微博热搜

我们提取出其中的一项tr来看看
<tr action-type=\"hover\">\n <td class=\"td_01\"><span class=\"search_icon_rankntop\"><em>1<\/em><\/span><\/td>\n <td class=\"td_02\"><div class=\"rank_content\"><p class=\"star_name\">\n <a href=\"\/weibo\/%25E5%2590%25B4%25E6%2598%2595%2B%25E9%259C%25B2%25E8%2583%258C%25E9%2595%25BF%25E8%25A3%2599&Refer=top\" target=\"_blank\" suda-data=\"key=tblog_search_list&value=list_realtimehot\">\u5434\u6615 \u9732\u80cc\u957f\u88d9<\/a>\n <i class=\"icon_txt icon_hot\">\u70ed<\/i><\/p><\/div><\/td>\n <td class=\"td_03\"><p class=\"star_num\"><span>693629<\/span><\/p><\/td>\n <td class=\"td_04\"><p class=\"rank_long\"><span class=\"long_con\" style=\"width:100%\"><\/span><\/p><\/td>\n <td class=\"td_05\"><a href=\"\/weibo\/%25E5%2590%25B4%25E6%2598%2595%2B%25E9%259C%25B2%25E8%2583%258C%25E9%2595%25BF%25E8%25A3%2599&Refer=top\" target=\"_blank\" class=\"search_icon icon_search\" suda-data=\"key=tblog_search_list&value=list_realtimehot\"><\/a><\/td>\n <\/tr>
看起来乱糟糟的,但是不要紧。
href里面的显然是连接,在http://s.weibo.com/weibo/后面加上每个热搜的链接就是单个热搜的网址了
但是我们也可以看到,这串script中的代码和普通的网页源码不大一样,多了许多 \ 在网址中也夹杂着25 估计是为了防止爬虫或者转义设计的。
同样,我们也可以很容易找到a标签中间的\u5434\u6615 \u9732\u80cc\u957f\u88d9,这很明显就是汉字转码后的编码\u70ed应该就是热度标志图片 693629自然是搜索指数 再后的width就是搜索热度那个进度条,看了一下,热度榜的逻辑应该是第一名满热度条即100%,之后的按搜索指数确定百分比
这样的项有50项,对应热搜榜单的前50
ok,基本的结构我们已经摸得比较清楚了
为了得到包含热搜内容的script,我们可以先把所有的script都提取出来,然后选取其中最长的项,这是一个比较取巧的方法,不过确实是比较简单有效的,因为这项包含了50项热搜内容,肯定是最长的一项。
仔细观察这一项,我们可以发现,热搜内容是包含在这个div里面的

然后运用正则表达式就很容易可以获取到需要的内容
下面是完整代码
package demo;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.net.URLDecoder;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import javax.print.Doc;
import org.apache.commons.lang3.StringEscapeUtils;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.impl.client.TargetAuthenticationStrategy;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class weibo_hotnews {
public static String webheader="http://s.weibo.com/weibo/";
public static void main(String []args) throws UnsupportedEncodingException{
String [][]result=patter_script(Analysis_page(get_page("http://s.weibo.com/top/summary?cate=realtimehot")));
for (int i = 0; i < result.length; i++) {
System.out.println((i+1)+" "+result[i][0]+" "+result[i][1]);
}
}
public static String download_page(String url){
String content=null;
//创建客户端
DefaultHttpClient httpClient=new DefaultHttpClient();
HttpGet httpGet=new HttpGet(url);
HttpResponse response;
try {
response = httpClient.execute(httpGet);
HttpEntity entity=response.getEntity();
if (entity!=null) {
content=EntityUtils.toString(entity,"utf-8");
EntityUtils.consume(entity);
}
} catch (ClientProtocolException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}finally {
httpClient.getConnectionManager().shutdown();
}
return content;
}
public static Document get_page(String url){
try {
return Jsoup.connect(url).get();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
System.out.println("url或网络连接错误");
return null;
}
}
public static String Analysis_page(Document page_html){
Elements links=page_html.getElementsByTag("script");
String allstring=null;
int tag=0;
for(Element link:links){
String script=link.toString();
if (script.length()>tag) {
tag=script.length();
allstring=script;
}
}
return allstring;
}
public static String[][] patter_script(String tag){
String [][] result=new String[50][2];
int i=0,j=0;
Pattern pattern = Pattern.compile("class=\\\\\"star_name\\\\\">\\\\n <a href=\\\\\"\\\\/weibo\\\\/(.*?)&Refer=top\\\\\" target=\\\\\"_blank\\\\\" suda-data=\\\\\"key=tblog_search_list&value=list_realtimehot\\\\\">(.*?)<\\\\/a>");
Matcher matcher = pattern.matcher(tag);
while (matcher.find()) {
result[i][j]=StringEscapeUtils.unescapeJava(matcher.group(2));
j++;
result[i][j]=webheader+matcher.group(1);
j=0;i++;
}
return result;
}
}
确实是实现是爬取的功能,后续可能会继续爬取各个话题的热门评论
