疫情期间,最开始在微博上有零星病例情况公布,于是研究微博爬虫,希望从微博中提取病例信息,研究疾病传染情况。后来爬出来以后,一是官方不再公布病例信息,二是不会NLP…就没继续做下去。但当时在网上找资料,很多基于移动端的微博爬虫,爬取的信息是省略的,结尾显示…全文
就像这样:
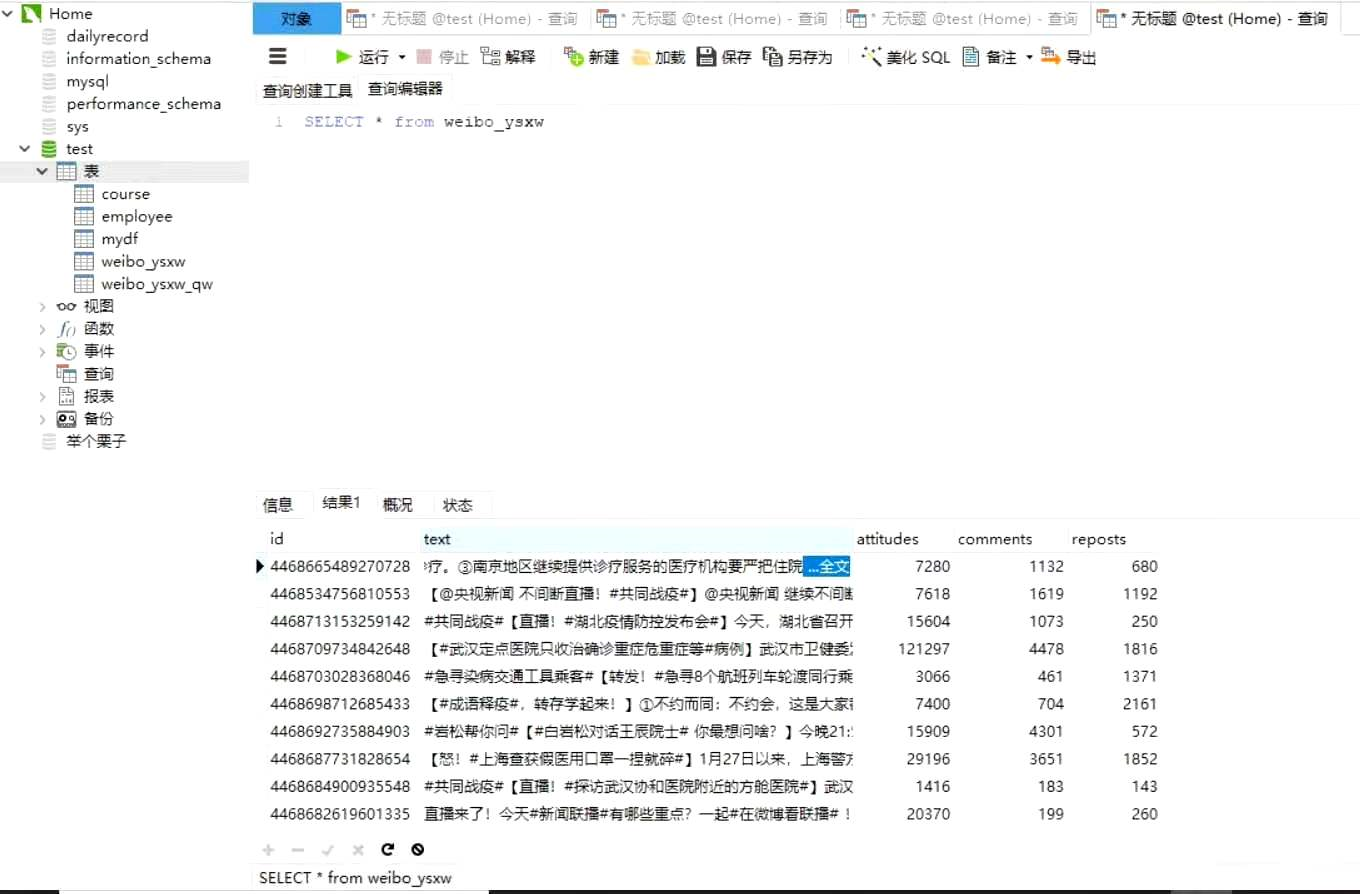
研究实验以后,终于能完整爬取微博全文的数据,结果如下:
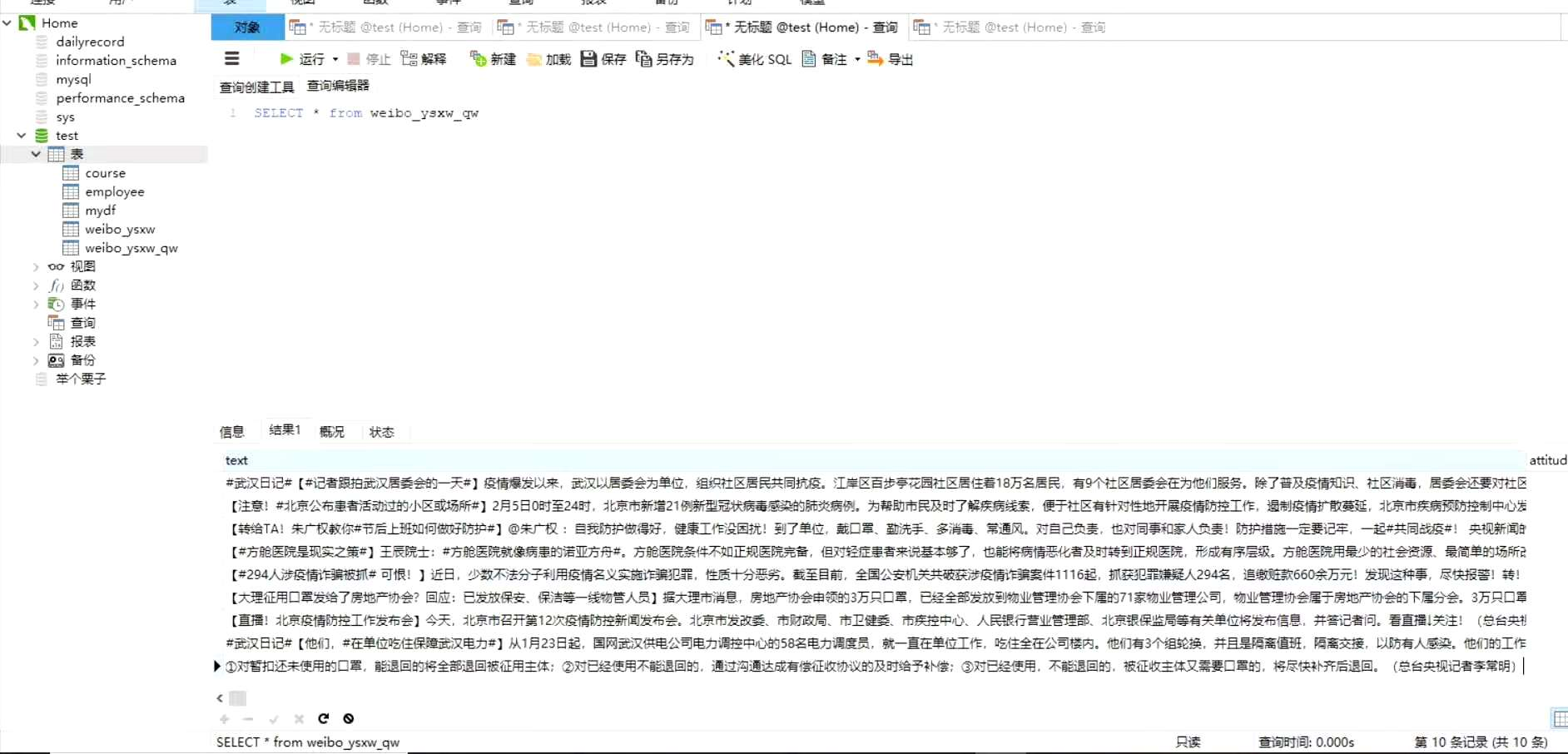
微博爬虫大体上是基于大佬代码的改的(具体哪位大佬忘记了,如果大佬看见麻烦联系我,我在文章里标上)
因为原先大佬代码无法显示全文,我也是找了好多资料,后来自己想了一种方法解决的。大半年过去了,忽然想着不要浪费,还是整理下,如果有人遇到类似问题,也许可以参考下。
接下来放代码(有不清楚的地方可以私信我)
因为我是将爬取的数据放进了MySQL数据库,这里需要首先创建一张存爬虫数据的新表:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
## 创建新表for新浪爬虫内容(新浪全文)
import pymysql
# 打开数据库连接
db = pymysql.connect("localhost", "root", "1234", "test", charset='utf8' ) #自己改一下这里的数据库信息,改成自己的,比如用户名root 密码1234 数据库test
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# 如果数据表已经存在使用 execute() 方法删除表。
cursor.execute("DROP TABLE IF EXISTS weibo_ysxw_new")
# 创建数据表SQL语句
sql = """CREATE TABLE weibo_ysxw_new (
text TEXT,
attitudes INT,
comments INT,
reposts INT ,
contentid varchar(32) unique) """
cursor.execute(sql)
# 关闭数据库连接
db.close()
print('successful')
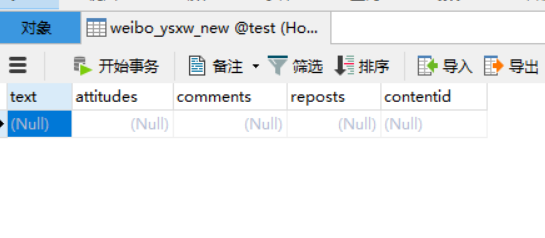
创建好以后可以看到test数据库里已经有一张空表了
接下来,直接微博爬虫,并把爬下来的内容更新到数据库
# 抓取微博全文内容
import requests
from urllib.parse import urlencode
from pyquery import PyQuery as pq
import pandas as pd
from sqlalchemy import create_engine
import pymysql
host = 'm.weibo.cn'
base_url = 'https://%s/api/container/getIndex?' % host
user_agent = 'User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1 wechatdevtools/0.7.0 MicroMessenger/6.3.9 Language/zh_CN webview/0'
headers = {
'Host': host,
'Referer': 'https://m.weibo.cn/u/2656274875', #这里是想要爬的微博的ID,自己替换一下,这里以央视新闻为例
'User-Agent': user_agent
}
# 按页数抓取数据
def get_single_page(page):
params = {
'type': 'uid',
'value': 2058586920, #随便去网上找了个,但这里需要替换成自己的微博信息
'containerid': 1076032058586920, #随便去网上找了个,但这里需要替换成自己的微博信息
'page': page
}
url = base_url + urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('catch wrong', e.args)
# 解析原页面返回的json数据
def parse_page(json):
items = json.get('data').get('cards')
for item in items:
item = item.get('mblog')
if item:
data = {
'id': item.get('id')
}
yield data
# 按内容ID抓取数据
def get_single_content(contentid):
base_url2='https://m.weibo.cn/statuses/extend?id='
url2 = base_url2 + contentid
headers2 = {
'Host': host,
'Referer': 'https://m.weibo.cn/status/'+contentid,
'User-Agent': user_agent}
print(url2) #打印出来要爬的这条微博的URL,不想看打印出来的信息可以注释掉,不影响最后写入数据库
try:
response = requests.get(url2, headers=headers2)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('catch wrong', e.args)
# 解析全文展开页面返回的json数据
def parse_page_content(json2):
item2 = json2.get('data')
if item2:
data = {
'text': pq(item2.get("longTextContent")).text(), # 仅提取内容中的文本
'attitudes': item2.get('attitudes_count'),
'comments': item2.get('comments_count'),
'reposts': item2.get('reposts_count')
}
yield data
def exportdata():
for page in range(20, 25): # 抓取前十页的数据
json = get_single_page(page)
results = parse_page(json)
db = pymysql.connect("localhost", "root", "1234", "test", charset='utf8' ) # 打开数据库连接
cursor = db.cursor() # 使用cursor()方法获取操作游标
table = 'weibo_ysxw_new' #mysql数据库里建的表
for result in results:
contentid = result['id']
json2=get_single_content(contentid)
results2=parse_page_content(json2)
for result2 in results2:
result2['contentid']=contentid
print(result2) #把抓取的每一条数据打印出来看看
data=result2
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
sql = 'INSERT INTO {table}({keys}) VALUES({values}) ON DUPLICATE KEY UPDATE '.format(table=table, keys=keys,values=values) #ON DUPLICATE KEY UPDATE表示当主键存在时,执行更新操作
#更新
updata = ', '.join(["{key} = %s".format(key=key) for key in data]) #连接起来实现更新数据
sql += updata
try:
if cursor.execute(sql, tuple(data.values()) * 2):
print("successful")
db.commit()
except:
print('failed')
db.rollback()
db.close()
if __name__ == '__main__':
exportdata()
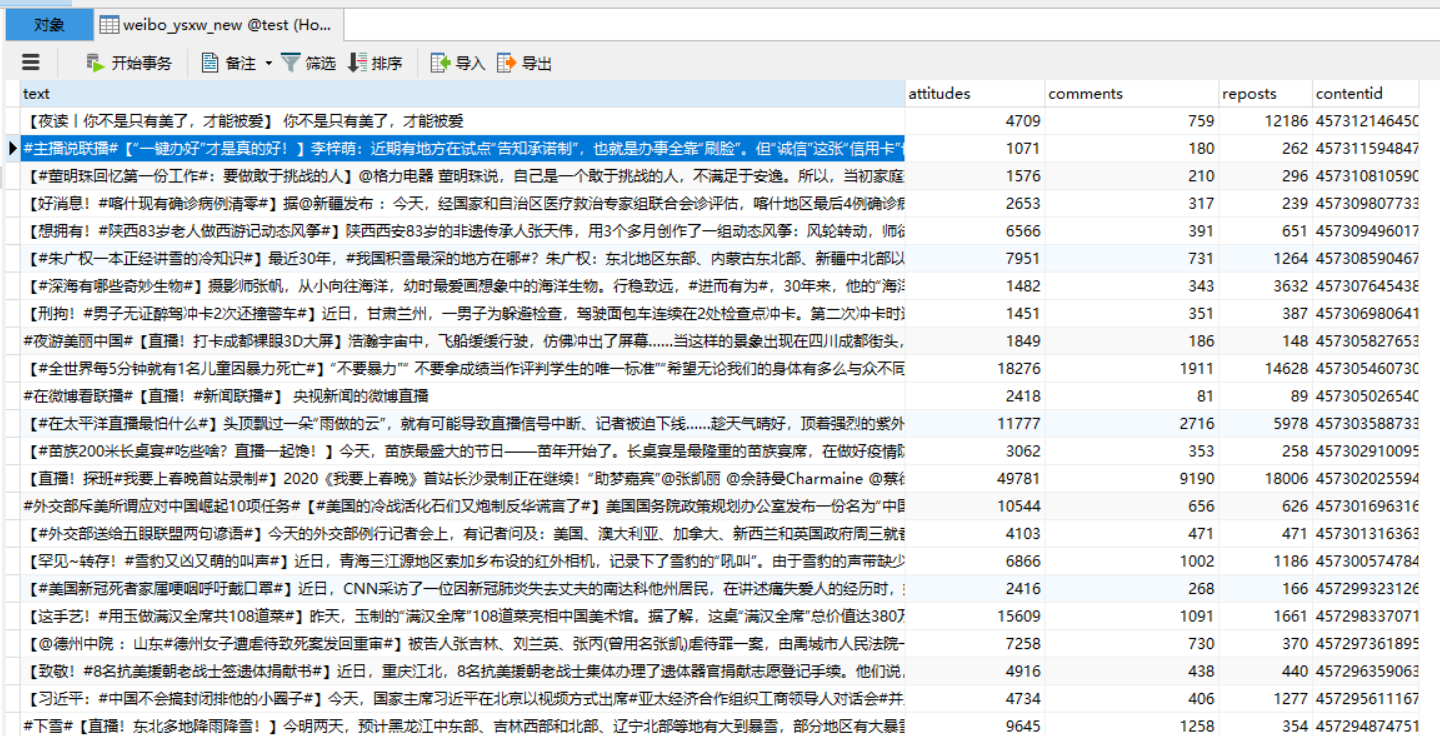
再去数据库里查看,这张表里已经有数据了
微博爬虫的代码放进GitHub了,有兴趣可以去看,有任何问题欢迎留言
https://github.com/JuneYaooo/weibo-reptile